







機器學習基石 (Machine Learning Foundations) 学习要点小结:
课程来自coursera:
https://class.coursera.org/ntumlone-002/lecture
第1讲 The Learning Problem
机器学习的应用场景:
(1)Navigating on Mars:需要自适应
(2)Speech/visual recognition:很难define the solution
(3)High-frequency trading:需要快速决策
(4)Consumer-targeted marketing:需要个性化
(5)a lot more…
Machine Learning的定义:
利用Data和Hypothesis set H得到g,使得g尽可能地接近真实的target f。
这里暂时可以用一个图来形象的表示其components:
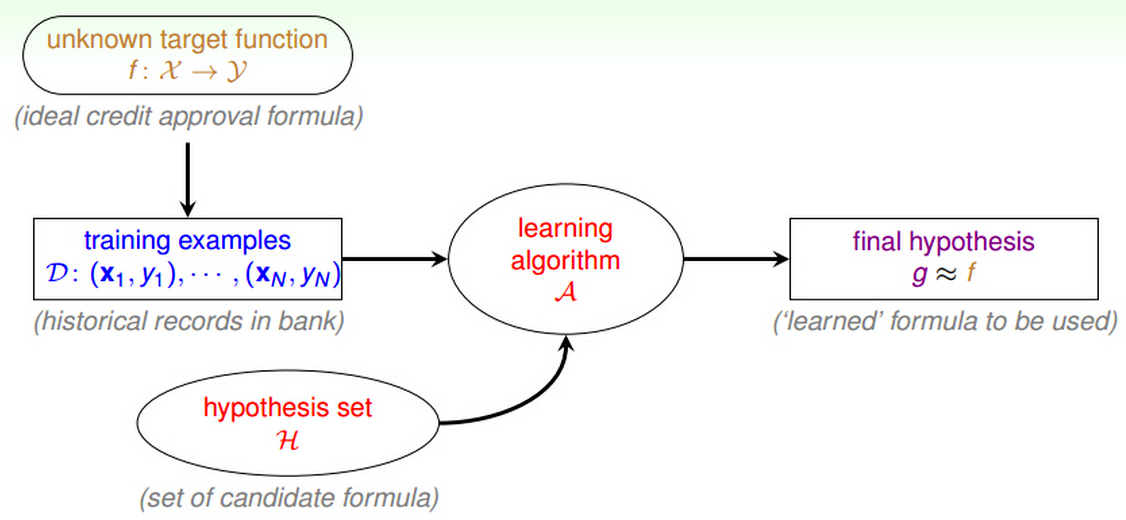
举个例子,我们想象一种场景:银行需要根据一系列信用卡申请者的信息,决定能否发放信用卡。在这里:
input:x就是申请者信息;
output:y就是发放/不发放;
data:训练数据。银行中的历史数据,申请人信息,信用卡是否发放,信用卡使用情况等;
target f:理想的信用卡发放的condition,这个我们是不知道的。我们只有一系列的信用卡发放历史记录,以及他们是否正常还款等等的信息,需要从这些历史data中学出来这个target function;
hypothesis:我们假定的一些可能与真实的target f很接近的条件。
第2讲 Learning to Answer Yes/No
感知机模型(perceptron):
hypothesis set:

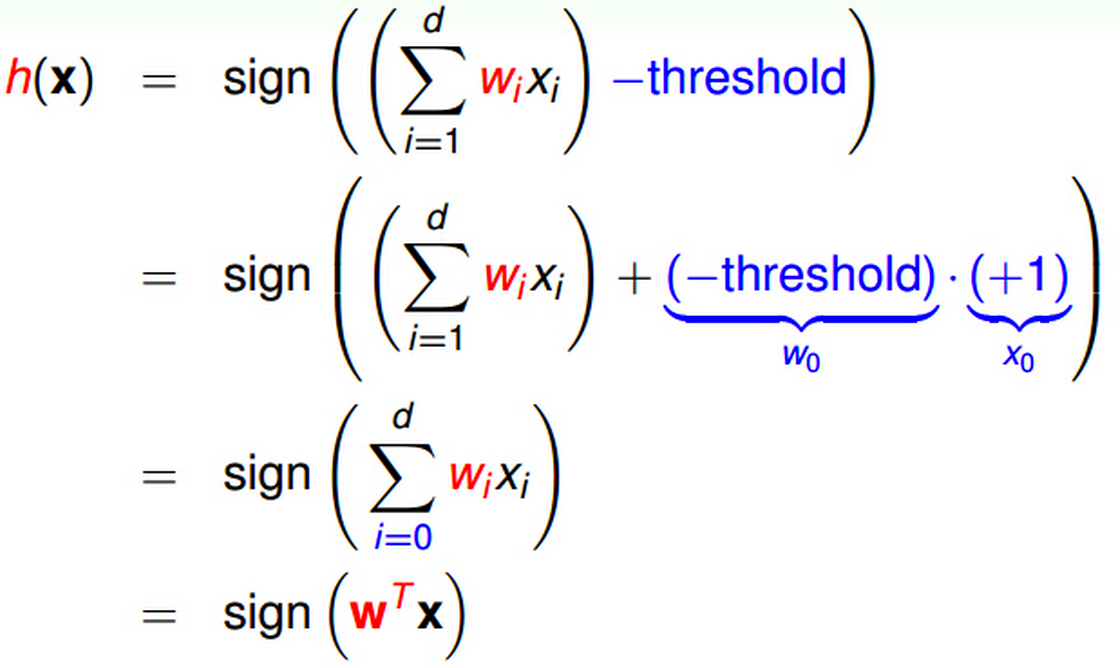
从几何的角度来看,最简单的感知机模型就是超平面中的一条线,因此,也可以称之为线性分类器(linear classification)。
有了hypothesis set以后,我们需要从中选出一个最接近f的g,因此就有了感知机学习算法(PLA:perceptron learning algorithm)。

当然,运用PLA有前提:需要Data线性可分。即只有在线性可分的前提下,PLA算法仅需要有限次的试错更新即可找到合适的超平面。
对于线性不可分的Data,PLA算法不会停止,会一直处于不断“自我纠错”,也就是学习的状态。
一种改进的策略是贪心,即在学习的过程中,如果找到一个好的w,就更新当前的w,直到一定的迭代次数过后,我们就暂且认为最后的w是目前为止最好的一个w。这个算法叫做Pocket PLA。
PLA算法的优点是:
(1)简单易实现;
(2)适用于高维feature空间;
缺点是
(1)需要线性可分的数据;
(2)理论上有最少次数的上界,但是具体多少需要看数据;
第3讲 Types of Learning
ML依据不同的标准有不同的分类方式:
比如:
按照输出空间Yn来分:
- 二元分类 binary classification:y = {-1, 1}
- 多元分类 multi-class classification:y = {1, 2, …, K}
- 回归分析 regression:y = R
- 结构学习 structured learning:y = structures
- a lot more …
按照Data来分:
- supervised data : all Yn, each Xn has a Yn
- unsupervised data : no Yn
- semi-supervised data : some Yn
- reinforcement:implicit y(n) 通过标记goodness(y^(n))。如果我们没有训练数据应有的输出y(n)的信息,但是我们有一些额外的输出标记、以及这些额外的标记的好坏。举个例子,训练宠物狗坐下的例子,我们没法告诉它当我说“坐下”的时候它的输出应该是怎样的;但是我可以通过奖励或者惩罚的方式对它作出的输出进行反馈。
- a lot more …
按照Target f 来分:
- batch learning
- online learning
- active learning
- a lot more …
按照Xn分类:
- concrete features
- raw features
- abstract features
- a lot more …
第4讲 Feasibility of Learning
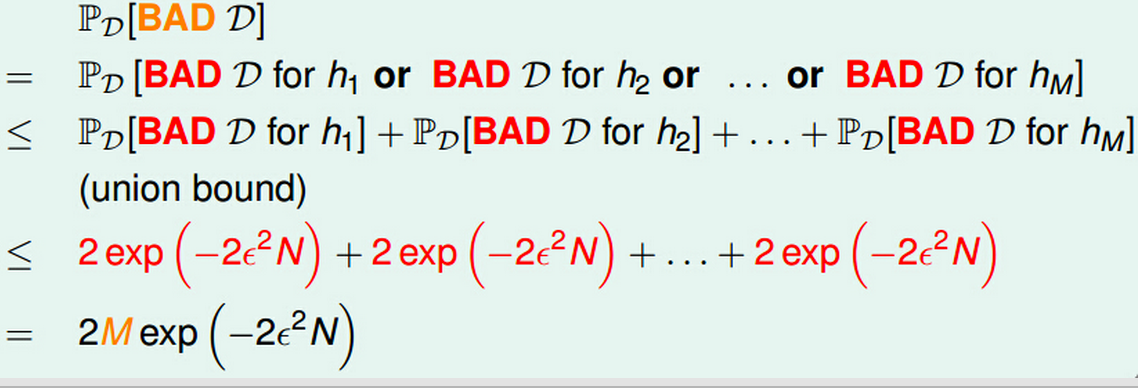
这里,M是hypothesis set的个数,N是data得大小。
我们根据Hoeffding’s Inequality可以得知:
如果hypothesis set是有有限种选择,训练样本data够多,那么不管学习算法A怎么选择,样本的判别结果都会与总体的一致。如果此时,我们从找到H中找到一个g,使得Ein很小,那么我们就可以说可以通过learning学到东西。
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









