







在人工智能领域,音频理解一直是一个挑战性的话题。随着技术的进步,我们越来越需要模型能够通过对话的形式来理解和交互音频内容。然而,现有的数据集大多专注于单轮交互任务,例如音频字幕和简单的问答,这限制了模型处理更复杂音频对话的能力。这些数据集通常只提供对音频的一次性描述或简短问题的回答,缺乏对音频内容进行深入、交互式探索的能力。并且,在生成过程中现有数据集往往缺乏详细的元描述和基于人类反馈的质量控制,导致生成的对话可能包含不确定性或不准确的信息。
为了克服这一限制,研究者们提出了Audio Dialogues数据集,它包含多轮对话和音频比较问题,用于提高模型对一般声音和音乐的深入理解。通过利用大型语言模型(LLM)生成基于提示的多轮对话,该数据集旨在推动音频理解模型在复杂交互和对话任务中的表现,从而促进音频增强的大型语言模型在音频相关领域的应用和发展。
数据生成管道
在构建Audio Dialogues数据集的过程中,研究者们采用了一个创新的数据生成管道,该管道是整个项目的核心。这个管道的起点是两个已经存在的数据集:AudioSet-SL和MusicCaps。这两个数据集为研究者们提供了丰富的音频样本,并且每个样本都有详细的强标注信息,这些信息包括了精确到秒的时间戳以及每个声音事件的声学特征描述。
在声学特征描述方面,研究者们采取了一种独特的方法。他们利用GPT-4的能力,为每一个声音类别生成一个简洁的描述。例如,对于“howl”(嚎叫)这个声音类别,GPT-4会生成如“Loud, prolonged, mournful, echoing sound”(响亮的、持久的、哀伤的、回响的声音)的描述。这样的描述不仅捕捉到了声音的本质特征,而且为后续的对话生成提供了丰富的素材。

对话生成是数据生成管道的下一个关键步骤。研究者们为此设计了一系列特定的提示模板,这些模板指导GPT-4生成自然的多轮对话以及音频比较问题的答案对。这些模板包括了系统提示和一些手工制作的对话示例,它们共同构成了生成对话的基础。系统提示会告诉GPT-4基于声音事件创建一个对话,其中包括用户的提问和助手的回答。这个过程不仅需要GPT-4理解音频内容,还需要它能够以一种有帮助且全面的方式回应用户。
为了确保生成的对话质量,研究者们实施了数据过滤策略。这个策略的目标是排除那些包含不确定性或信心不足的问答对。例如,如果生成的回答中包含了“难以推断”、“未指定”或“无具体信息”等短语,那么这个问答对就会被过滤掉。此外,研究者们还采用了一种基于余弦相似度的计算方法,来评估CLAP文本嵌入和音频嵌入之间的相似性。那些余弦相似度低于0.3的样本会被从数据集中移除,以此来进一步提高数据集的准确性和可靠性。
Audio Dialogues数据生成管道通过精心设计的步骤和严格的质量控制,为音频理解领域提供了一个高质量、多轮对话的数据集,这将有助于推动音频增强的大型语言模型在交互式对话任务中的表现。
Audio Dialogues数据集
Audio Dialogues数据集是NVIDIA研究团队为了推动音频和音乐理解而精心设计的一个多模态数据集。它通过模拟真实世界的对话场景,使模型能够更深入地理解和交互音频内容。以下是对Audio Dialogues数据集的详细描述:
数据集统计信息
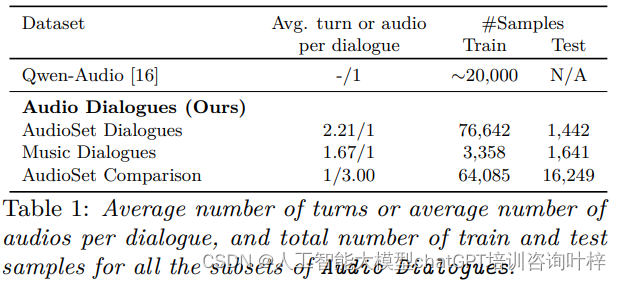
Audio Dialogues数据集的统计信息揭示了其规模和构成。与Qwen Audio数据集相比,Audio Dialogues提供了更为丰富的样本量,总计达到163.8k个样本。这些样本被分为不同的子集,以适应不同类型的音频理解任务。例如,AudioSet Dialogues子集专注于一般声音的对话,而Music Dialogues子集则专注于音乐样本。此外,还有一个AudioSet Comparison子集,它包含了多个音频样本的比较问题,要求模型在比较不同音频时展现出更高级的理解能力。
在样本分布上,AudioSet Dialogues训练集包含76,642个对话,测试集有1,442个对话;Music Dialogues训练集有3,358个对话,测试集有1,641个对话;AudioSet Comparison训练集有64,085个对话,测试集有16,249个对话。这种分配确保了模型在训练和评估时都有足够的数据,并且可以模拟真实世界中的多样性。
生成对话的示例
为了更好地理解Audio Dialogues数据集的内容和应用,研究者们提供了在AudioSet-SL数据集上生成的对话示例。这些示例展示了如何通过对话形式来探索和理解音频样本。例如,一个关于“心跳声”和“背景噪音”的音频样本可以激发以下对话:
- 用户:这段音频中的主要声音是什么?
- 助手:这段音频中的主要声音是心跳声和一些背景噪音。
- 用户:心跳声在整个音频中是一致的吗?
- 助手:是的,心跳声在整个音频中都是一致且有节奏的,中间有短暂的停顿。
这个对话不仅展示了用户如何通过提问来探索音频内容,也展示了助手如何利用音频的声学特征来提供信息丰富、逻辑连贯的回答。这种交互方式模拟了人类理解音频的过程,使得模型能够通过对话来逐步构建对音频的理解。
对话生成的细节
生成这些对话的过程中,研究者们使用了基于提示的方法。这意味着他们为大型语言模型(LLM)提供了精心设计的提示模板,这些模板指导模型生成与音频内容紧密相关的对话。提示模板不仅包含了音频的描述,还包含了用户可能的提问方式和助手的回答策略。
在生成对话时,研究者们还特别注意保持对话的多样性和复杂性。他们确保用户提出的问题覆盖了音频内容的不同方面,并且助手的回答能够提供全面的推理。这种方法不仅提高了数据集的质量,也为模型提供了更丰富的训练信号。
数据集的过滤和质量控制
为了进一步提高数据集的质量,研究者们实施了严格的数据过滤策略。他们排除了那些包含不确定性或信心不足的问答对,例如那些包含“难以推断”、“未指定”或“无具体信息”等短语的样本。此外,他们还通过计算CLAP文本嵌入和音频嵌入之间的余弦相似度来评估每个问答对的相关性,进一步确保了数据集的准确性。
Audio Dialogues数据集是一个高质量、多模态的资源,它为音频理解领域提供了新的挑战和机遇。通过模拟真实世界的对话,它不仅增强了模型对音频的理解能力,也为音频增强的大型语言模型的发展提供了新的方向。随着音频理解技术的不断进步,Audio Dialogues数据集有望在未来发挥更大的作用。
实验
在验证Audio Dialogues数据集有效性的过程中,研究者们开展了一系列实验,这些实验涉及了多个音频理解大型语言模型(LLMs),并严格遵循了科学的方法论。以下是对实验部分的详细描述:
实验设计
实验的核心目标是评估Audio Dialogues数据集对于提升音频理解模型性能的作用。为此,研究者们选取了三个具有代表性的音频理解模型:LTU、Qwen-Audio和Audio Flamingo。这些模型在音频理解领域各有特点,能够全面地反映数据集对不同类型模型的促进效果。
零样本评估
在零样本评估阶段,研究者们没有对模型进行任何针对Audio Dialogues数据集的专门训练。这一步骤的目的是模拟模型在遇到完全未知数据时的表现,从而提供一个性能的基准。零样本评估能够揭示模型在没有额外数据支持下,对Audio Dialogues数据集中音频内容的理解和生成对话的能力。
微调过程
为了进一步探索Audio Dialogues数据集的价值,研究者们对LTU和Audio Flamingo模型进行了微调。微调是指使用特定数据集对模型的参数进行优化,以期达到更好的性能。这个过程对于评估数据集对模型性能提升的贡献至关重要。微调后,模型在Audio Dialogues数据集上的表现预期将超过零样本评估的结果。
评估指标
研究者们使用了多个指标来评估模型性能,包括CIDEr、Bleu4和Rouge-L(R-L)。这些指标能够从不同角度衡量模型生成的对话或答案的质量,包括一致性、流畅性、准确性和多样性。
实验结果
实验结果显示,经过微调的模型在所有评估指标上都有所提升,这表明Audio Dialogues数据集对模型性能有显著的正面影响。特别是Audio Flamingo模型,它结合了上下文学习和检索增强生成技术,在微调后展现出了更强的对话能力和更准确的音频理解。
定性分析
除了定量的评估指标,研究者们还进行了定性分析,通过具体的对话示例来展示模型在处理复杂音频内容时的表现。定性分析有助于深入理解模型在实际对话中的能力,包括对音频内容的理解、上下文的把握和对话的连贯性。

Audio Dialogues数据集为音频和音乐理解领域提供了一个宝贵的资源。通过多轮对话的形式,该数据集不仅增强了模型对音频内容的理解,而且推动了音频增强LLMs在交互式对话方面的能力。尽管存在一些局限性,如缺少时间戳信息,但这项工作为未来音频理解模型的发展奠定了基础,并指出了未来研究的潜在方向。
论文链接:https://arxiv.org/abs/2404.07616
Github 地址:https://audiodialogues.github.io/
















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









