







随着人工智能技术的飞速发展,遥感图像理解在环境监测、气候变化、粮食安全和灾害预警等多个领域扮演着越来越重要的角色。然而,现有的通用视觉语言模型(VLMs)在处理遥感图像时仍面临挑战,主要因为遥感图像的独特性和当前VLMs相对有限的空间感知能力。为了克服这些限制,研究者们提出了H2RSVLM,即“Helpful and Honest Remote Sensing Vision Language Model”,这是一个专为遥感领域设计的新型视觉语言模型。本文将详细介绍H2RSVLM模型的创新之处,包括其用于RSVLMs的帮助和诚实数据集、模型架构以及在多个遥感公共数据集上的实验验证。(注:H2RSVLM中2为上标,以下皆相同)
在构建H2RSVLM模型的过程中,研究者们特别重视为模型提供高质量的训练数据,这直接关系到模型最终的性能和可靠性。为此,他们开发了两个关键的数据集:HqDC-1.4M和RSSA,这两个数据集共同为RSVLMs提供了必要的帮助和诚实性。
HqDC-1.4M数据集是这一努力的核心,它包含了140万张遥感图像及其对应的详细描述。这些描述不是简单的标签或简短的句子,而是通过先进的VLM Gemini-Vision生成的丰富、详尽的标题,它们能够提供图像中对象的类型、场景和具体细节。例如,在一个码头的航拍图像中,描述不仅会提到码头上停泊的船只数量,还会细致到船只的大小、颜色和停靠的状态,甚至是周围水域的颜色和质地。这样的描述极大地增强了模型对遥感图像内容的深入理解,以及对图像中空间细节的感知能力,比如能够更准确地进行定位和计数。
为了解决模型可能产生的“幻觉”问题,即在面对无法回答的问题时生成错误答案,研究者们创建了RSSA数据集。RSSA是首个专注于提升RSVLM自我感知能力的遥感数据集,它通过在视觉问答任务中引入无法回答的问题,教会模型识别出这些问题并拒绝回答。这种自我感知的能力对于保持模型输出的真实性至关重要。例如,在一张黑白的遥感图像中,如果问到某个物体的实际颜色,模型将学会回答无法确定颜色,因为黑白图像无法提供颜色信息。
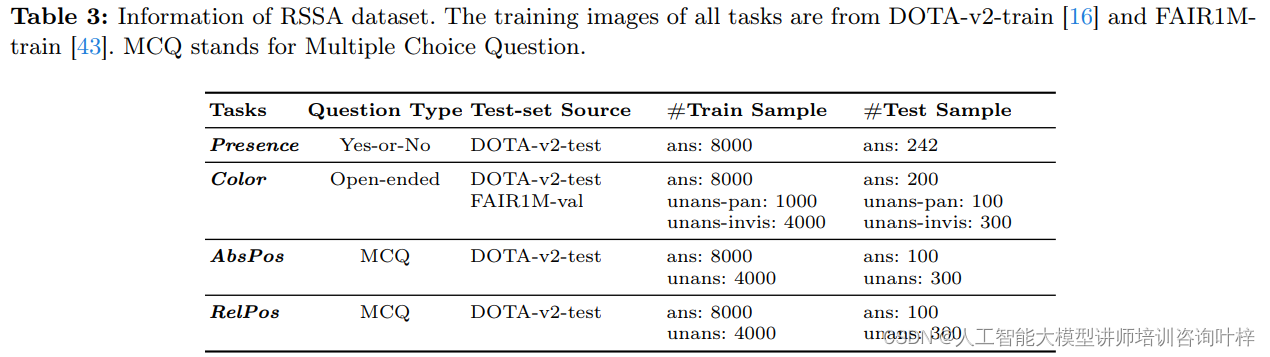
通过HqDC-1.4M和RSSA这两个数据集的结合使用,H2RSVLM模型不仅能够获得丰富的图像理解能力,还能培养出对自身知识限制的自我意识,从而在实际应用中提供更可靠、更真实的答案。这种结合高质量数据和自我感知训练的方法,标志着遥感视觉语言模型的一个重要进步。

在 Fig. 1 中,(a) 和 (b) 分享了相同的图像,而 (c) 和 (d) 则展示了类似场景的不同图像。通过这种对比,突出了 HqDC-1.4M 数据集在提供详尽描述和增强模型理解能力方面的优势。这些详细的描述对于训练一个能够有效处理遥感图像的 RSVLM 是至关重要的,因为它们可以帮助模型学习如何识别和定位图像中的对象,以及如何准确地描述这些对象的特征和相互之间的关系。
H2RSVLM模型的构建是在已有的LLaVA模型基础上进行的,它代表了对现有技术的一次显著扩展和改进。这个模型由三个主要部分组成,每个部分都针对遥感图像理解任务进行了特别优化。
核心的第一步是图像的转换和理解,这由预训练的视觉编码器CLIP-Large完成。CLIP-Large的作用是将输入的遥感图像转换成模型能够进一步处理的格式,即将视觉信息编码成一系列的特征向量,为后续的处理打下基础。这一步骤至关重要,因为它直接影响到模型对图像内容的捕捉和理解能力。
紧接着,模型采用了基于开源Vicuna-v1.5的大型语言模型(LLM)。这个语言模型是H2RSVLM的智能核心,赋予了模型强大的自然语言处理能力。Vicuna-v1.5使得H2RSVLM不仅能理解图像内容,还能以自然语言的形式与用户进行交流,生成描述,回答问题,甚至进行复杂的推理。
最后,一个关键的组件是连接视觉编码器和语言模型的投影器MLP。MLP的作用是确保图像内容和语言描述之间的有效交互,它作为桥梁,将视觉编码器提取的图像特征与语言模型的语义理解能力结合起来,使得模型能够生成与图像内容紧密相关的语言描述。
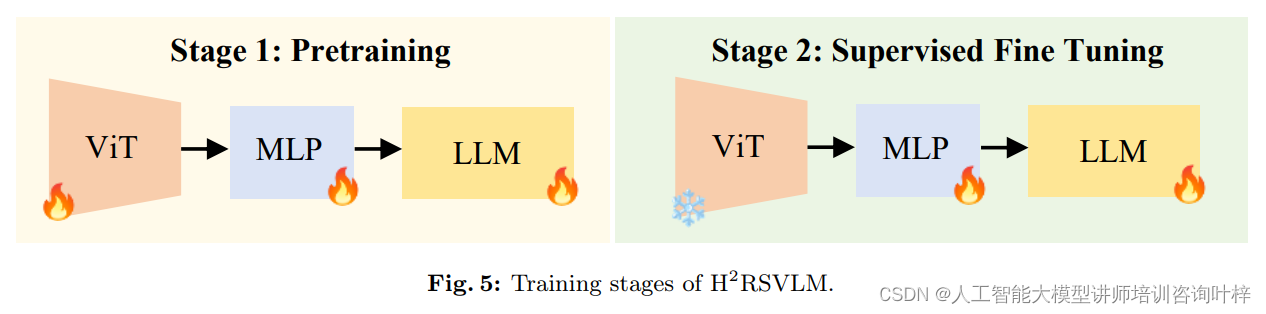
通过这三个组件的协同工作,H2RSVLM模型能够精确地理解遥感图像,并以自然、准确的方式与用户交流。这种集成了视觉感知和语言理解的模型,为遥感图像的自动解释和分析提供了强大的支持,极大地推动了遥感图像理解技术的发展。
H2RSVLM模型的训练过程精心设计,以确保其在遥感图像理解方面的卓越性能。这一过程始于预训练阶段,这是模型构建知识基础的关键时刻。在这一阶段,HqDC-1.4M数据集扮演了至关重要的角色,它提供了丰富的遥感图像资源库,每张图像都附有详尽的描述。这些描述不仅覆盖了图像中的主要对象,还细致到了对象的数量、颜色、形状和空间位置等属性。这样的设计让模型在早期学习阶段就能够深入理解遥感图像的复杂性。
利用HqDC-1.4M数据集,模型的视觉编码器、语言模型和投影层在预训练阶段都经过了微调。视觉编码器负责解析图像内容,将其转化为模型能够理解的格式;语言模型则赋予模型处理和生成自然语言的能力;而投影层则作为连接视觉和语言处理部分的桥梁,确保两者能够有效地协同工作。这一协同工作是模型成功的关键,因为它允许模型精确捕捉图像的关键特征和细节,为后续的理解和分析打下坚实的基础。
预训练不仅仅是一个技术过程,它还是模型学习和适应遥感图像特性的开始。通过对HqDC-1.4M数据集中的图像和描述的学习,H2RSVLM模型能够建立起对遥感图像的深刻理解,这种理解是模型后续发展和应用的基石。随着模型在预训练阶段对基础知识的掌握,它已经准备好进入下一个阶段,即监督式微调,这将进一步增强模型的能力,使其能够处理更为复杂的遥感图像理解任务。
在完成了预训练阶段的知识积累之后,H2RSVLM模型进入了监督式微调阶段,这是一个更为复杂和深入的学习过程。在这一阶段,模型接触到了更为广泛的数据集,包括HqDC-Instruct、RSSA、RS-Specialized-Instruct和RS-ClsQaGrd-Instruct,这些数据集涵盖了从多轮对话到复杂推理的多种任务类型。
HqDC-Instruct数据集专注于提升模型的多轮对话能力,通过提供详细的遥感图像描述和相关问题,训练模型在对话中保持上下文连贯性,理解复杂问题,并给出准确的回答。RSSA数据集则针对模型的自我感知能力进行训练,教会模型识别无法回答的问题,并在必要时拒绝回答,从而提高模型的诚实性和可信度。
RS-Specialized-Instruct数据集引入了遥感图像处理的专业技能和知识,包括图像类型识别、空间分辨率估计、目标测量等专业任务,这些训练帮助模型掌握了遥感图像分析的专业能力。RS-ClsQaGrd-Instruct数据集则包含了场景分类、视觉问答和视觉定位等任务,通过这些任务的训练,模型能够更好地理解遥感图像的内容,并在多种视觉语言任务中表现出色。
通过这些丰富多样的数据集的训练,H2RSVLM模型不仅在多轮对话中表现出色,能够在交流中提供连贯、准确和有帮助的信息,而且在复杂推理任务上也有显著提升。这使得H2RSVLM能够处理更为复杂的遥感图像相关问题,提供丰富和准确的答案,极大地增强了模型在实际应用中的效能和可靠性。
在这一过程中,H2RSVLM模型的学习不仅限于表面的特征识别,而是深入到图像的语义理解,以及与用户意图和问题背景相关的深层次推理。这样的训练使得H2RSVLM成为一个强大的遥感图像分析工具,能够在各种复杂场景中提供有价值的洞察和信息。
在H2RSVLM模型的实验部分,研究者们进行了一系列的定量和定性评估,以验证模型在遥感图像理解任务上的性能。实验涵盖了场景分类、视觉问答(VQA)、视觉定位(VG)以及多标签土地覆盖分类、图像类型识别、对象测量、建筑足迹矢量化和计数等专业遥感任务。
场景分类实验中,H2RSVLM在多个数据集上进行了测试,包括NWPU、METER-ML、SIRI-WHU、AID和WHU-RS19等,这些数据集包含了不同分辨率和类别的遥感图像。H2RSVLM展现出了卓越的性能,其平均准确率显著高于其他通用VLMs,证明了其在遥感图像分类任务上的有效性。
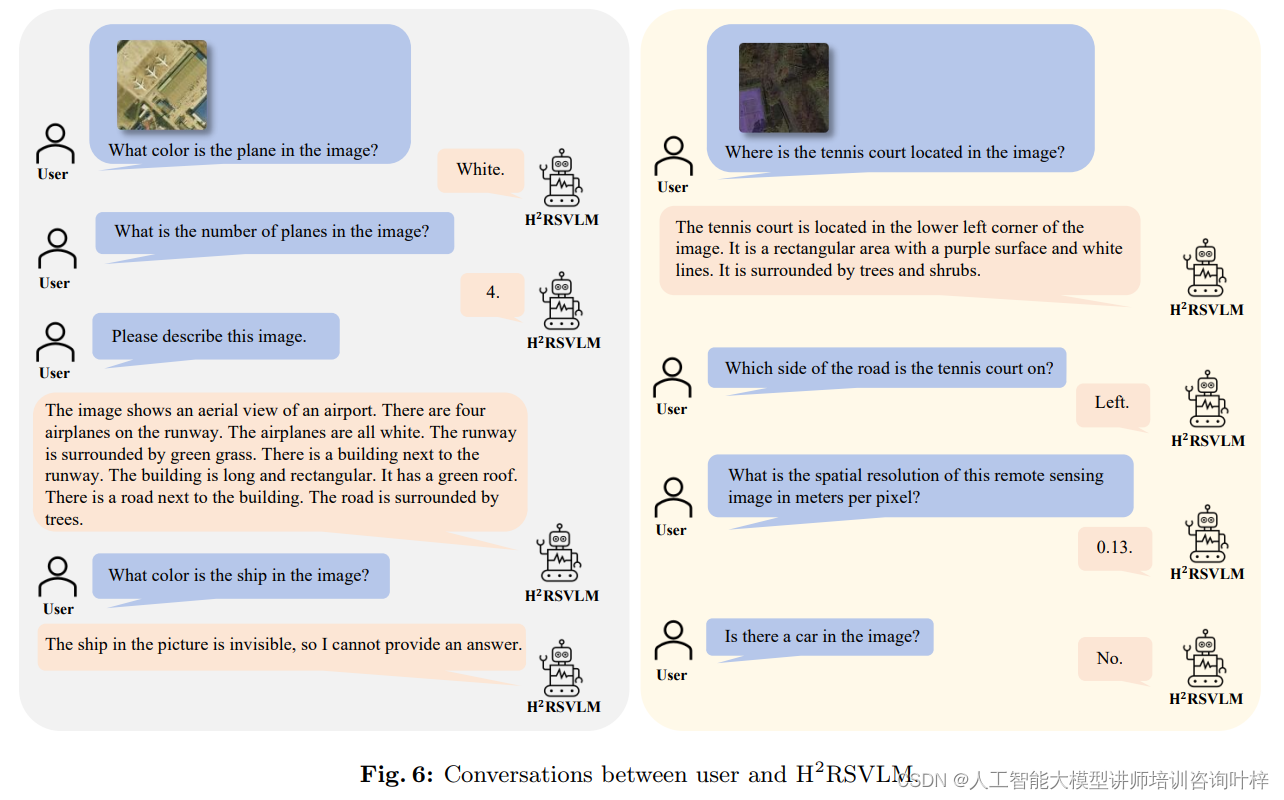
Fig. 6 展示了用户和 H2RSVLM(Helpful and Honest Remote Sensing Vision Language Model)之间的对话示例。这个模型是为了提高遥感图像理解、空间感知能力,并增强模型的诚实性而设计的。展示了 H2RSVLM 在遥感图像理解、空间细节感知、诚实性以及与用户交互方面的能力。通过这些交互,我们可以看到 H2RSVLM 不仅能够理解和回答有关遥感图像的问题,还能够在必要时诚实地表达其限制,这是在遥感领域中一个重要的特性。
视觉问答任务是评估模型理解图像内容并用自然语言回答问题的能力。H2RSVLM在RSVQA-LR和RSVQA-HR数据集上进行了评估,结果显示,即使在训练数据较少的情况下,模型也能展现出与其它模型相媲美的性能,而在零样本学习设置下,H2RSVLM的性能更是超越了其他VLMs。
视觉定位任务测试了模型识别图像中特定对象位置的能力。在DIOR-RSVG数据集上,H2RSVLM在图像细粒度理解和定位方面表现出色,准确率达到了48.04%,这一结果展示了模型在处理具有挑战性的遥感图像时的强大能力。
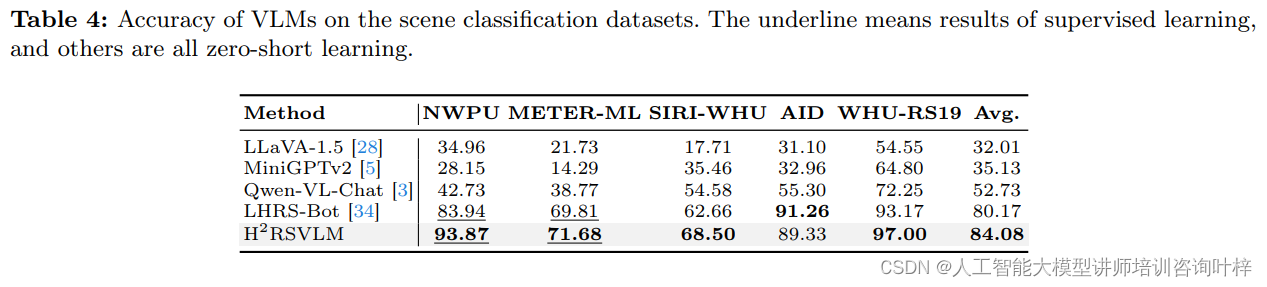
Table 4 在论文中提供了不同视觉语言模型(VLMs)在场景分类数据集上的性能对比。表格列出了几个不同的数据集和几种不同的方法,并展示了它们在监督学习(supervised learning)和零样本学习(zero-shot learning)两种情况下的准确率。
在更专业的遥感任务中,H2RSVLM同样进行了评估。例如,在图像地面采样距离估计(GSDEst)任务中,模型需要预测图像的空间分辨率,而在对象测量(ObjMeas)任务中,模型需要测量图像中对象的具体尺寸。多标签土地覆盖分类(MlLc)任务要求模型识别图像中的多种土地覆盖类型。在这些任务中,H2RSVLM都显示出了良好的性能,尽管在视觉定位(VG)和建筑足迹矢量化(BFV)任务中,模型在处理小对象和复杂轮廓时还存在一些挑战。
通过这些实验,H2RSVLM证明了其在遥感图像理解领域的潜力。研究者们还通过可视化的方式展示了模型的一些预测结果,如图14和图15所示,这些结果不仅展示了模型在某些任务上的准确性,也揭示了模型在处理特定类型图像时可能遇到的困难。这些实验结果为H2RSVLM的进一步优化和应用提供了宝贵的反馈和指导。


















 5322
5322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









