







人工智能咨询培训老师叶梓 转载标明出处
随着大模型模型规模的增长,这些强大工具的透明度、可复现性和对数据偏见的敏感性也引起了人们的关注。这些问题不仅关系到研究的开放性和公平性,也关系到模型输出的可信度和安全性。为了应对这些挑战,Apple的研究团队发布了名为OpenELM的新一代开放语言模型。OpenELM采用了层级缩放策略,优化了变换器模型中每层的参数分配,从而提升了模型的准确性。例如,在大约十亿参数的预算下,OpenELM在准确性上比现有的开放语言模型OLMo提高了2.36%,同时所需的预训练数据减少了一倍。

OpenELM架构
OpenELM采用了解码器仅的变换器架构,这种架构专注于生成文本任务,并且是当前大型语言模型的主流设计。这种架构的优势在于它能够集中所有的参数用于解码,而不是像编码器-解码器架构那样将参数分散在编码和解码两个部分。
OpenELM的一个关键创新是层级缩放策略,它允许模型根据每层的需要分配不同数量的参数。这种策略通过调整变换器层中的注意力头数和前馈网络的维度来实现,使得模型能够更有效地利用其参数预算,从而在各种任务上实现更高的准确性。
OpenELM的架构还包括了一系列先进的组件,如下:
- RMSNorm: OpenELM使用RMSNorm作为其正规化层,有助于模型训练的稳定性和更快的收敛速度。
- RoPE(旋转位置嵌入): 这是一种新颖的位置编码方法,可以更有效地捕捉序列中的位置信息。
- 分组查询注意力(GQA): 替代了传统的多头注意力机制,可能提供更好的注意力聚焦和计算效率。
- SwiGLU FFN: 这是一种改进的前馈网络,通过门控机制提高了信息处理的能力。
- Flash Attention: 这是一种高效的注意力计算方法,可以减少内存使用并加速模型的推理过程。
OpenELM的架构设计允许模型进行有效的微调。通过指令调整和参数高效微调(PEFT),模型能够快速适应特定的任务和应用场景,进一步提升其性能。这种灵活性使得OpenELM不仅在预训练阶段表现出色,而且在微调后也能在各种下游任务中发挥出色的性能。
OpenELM的架构和训练过程是完全开放的。研究者和开发者可以访问所有的训练日志、检查点和配置,这种开放性促进了社区的协作和创新,使得OpenELM成为一个强大的、不断进化的语言模型平台。
预训练
OpenELM的预训练使用了多个公共数据集,包括RefinedWeb、去重后的PILE、RedPajama的一个子集以及Dolma v1.6的一个子集,总共约有1.8万亿个token。这些数据的详细情况在表2中进行了总结。

OpenELM的变体使用了CoreNet进行了350,000次迭代(或训练步)的训练,并采用了AdamW优化器。训练使用了余弦学习率调度策略,预热5,000次迭代,最终学习率衰减至最大学习率的10%。此外,还使用了权重衰减0.1和梯度裁剪1.0。
OpenELM的性能评估涵盖了不同的任务,并使用了LM Evaluation Harness。评估包括标准零样本任务、OpenLLM排行榜任务和LLM360排行榜任务。这些评估框架允许我们全面评估OpenELM在推理(例如ARC-c、HellaSwag和PIQA)、知识理解(例如MMLU和RACE)以及错误信息和偏见(例如TruthfulQA和CrowS-Pairs)方面的表现。

实验
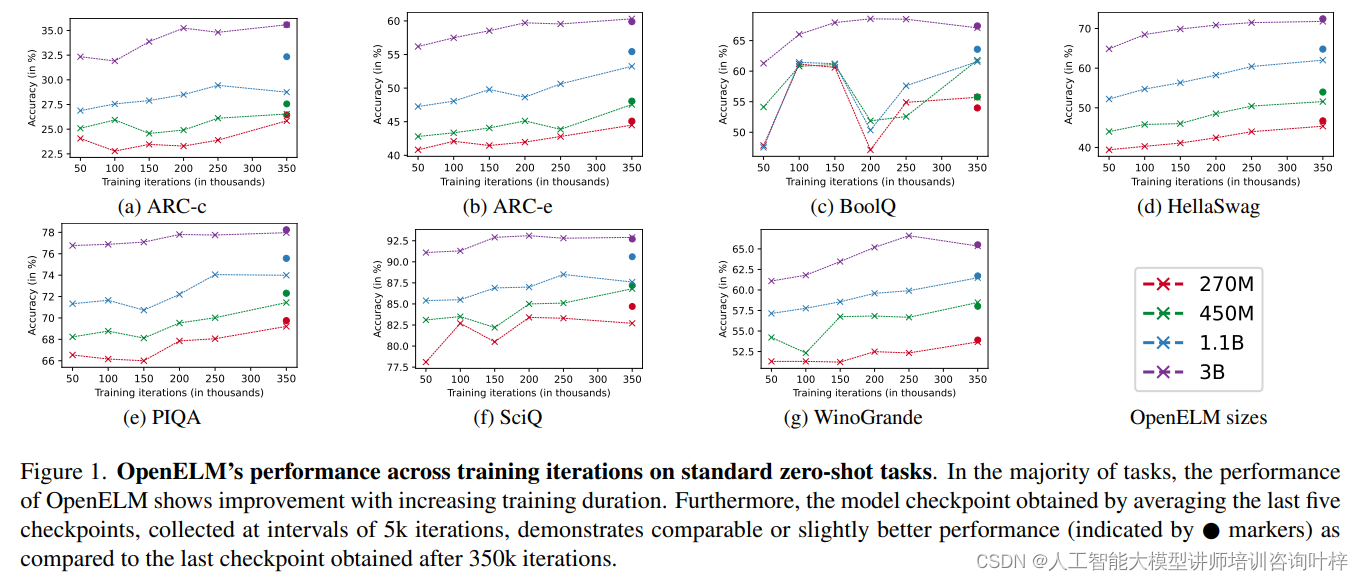
OpenELM在零样本和少样本设置下的性能表现尤为突出。与其他公开可用的大型语言模型相比,例如PyThia、Cerebras-GPT、TinyLlama、OpenLM、MobiLlama和OLMo,OpenELM显示出了其优越性。图1展示了OpenELM在七个标准零样本任务上的准确率随训练迭代次数的变化情况。研究团队观察到,随着训练时间的增加,大多数任务的准确率呈现出整体上升的趋势。

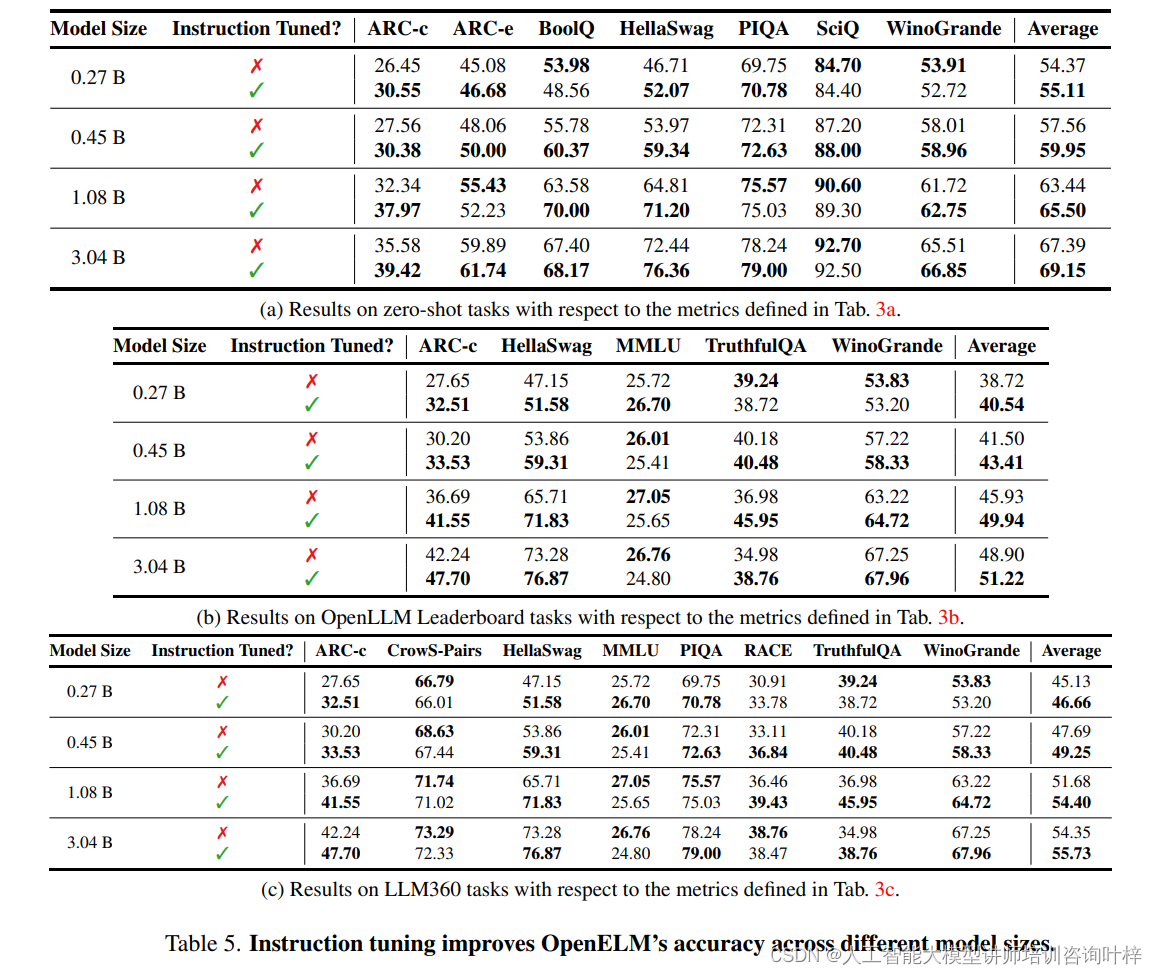
研究团队还使用经过清洗的UltraFeedback数据集的变体,该数据集包含60k个提示,用于指令调整。通过使用Alignment Handbook库进行指令调整,OpenELM的平均准确率在不同评估框架中一致提高了1-2%。
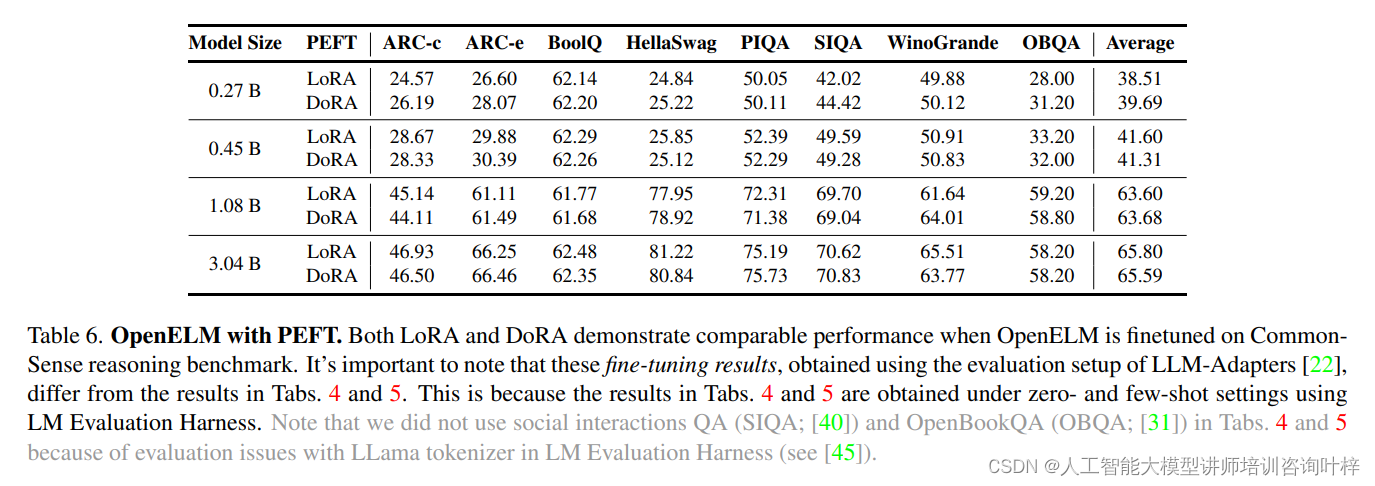
在CommonSense推理训练和评估设置中,研究团队使用了170k个训练样本,这些样本跨越了8个多项选择数据集。通过将OpenELM与LoRA和DoRA等方法集成,并使用8个NVIDIA H100 GPU进行微调,表6显示了参数高效微调(PEFT)方法可以应用于OpenELM,并且LoRA和DoRA在给定的CommonSense推理数据集上平均准确率相似。
基准测试
研究团队在现代消费级硬件上对OpenELM进行了基准测试,使用了BFloat16数据类型。具体的测试平台包括配备Intel i9-13900KF CPU、64 GB DDR5 4000 DRAM、NVIDIA RTX 4090 GPU的Linux工作站,以及搭载Apple M2 Max系统芯片、64GiB RAM的macOS MacBook Pro。这些基准测试涵盖了模型在不同硬件平台上的推理效率。
基准测试中,研究团队提供了两个独立的性能指标:(1) 提示处理(预填充)的token吞吐量;(2) token生成的吞吐量。此外,还报告了总的组合吞吐量。所有模型的测试都是顺序执行的,并且在每个模型的测试前,执行了一次完整的“干运行”,以生成1024个token,这有助于提高后续模型的生成吞吐量。

基准测试的结果分别在表7a和7b中展示。尽管OpenELM在类似参数规模下展现出了更高的准确性,但在推理速度上却比OLMo慢。通过对模型进行综合分析,研究团队发现OpenELM的大部分处理时间可以归因于其对RMSNorm的简单实现。特别是,与优化过的LayerNorm相比,RMSNorm的简单实现导致了大量的独立核启动,每个核处理的输入量很小,而不是像LayerNorm那样通过单个融合核启动来处理。

表8进一步展示了归一化层对性能的影响。将OLMo中的LayerNorm替换为RMSNorm后,生成吞吐量显著下降。这表明,尽管Apex的RMSNorm实现相比简单实现在吞吐量上有所提升,但与LayerNorm相比仍存在显著的性能差距。这一发现突出了未来工作在提高OpenELM推理效率方面的优化潜力。
实验结果证明OpenELM作为一种新型的开放语言模型,以其创新的架构和高效的参数分配策略,在自然语言处理领域展现出了卓越的性能和准确性。它所采用的解码器仅变换器架构、层级缩放策略以及一系列先进技术组件,不仅提升了模型的语言理解与生成能力,还保证了模型训练的稳定性和推理的高效率。OpenELM的全面开放性,包括训练日志、检查点和配置的共享,进一步促进了研究社区的协作与知识共享,为未来的技术进步和应用创新奠定了坚实的基础。
论文链接:https://arxiv.org/abs/2404.14619
GitHub地址:https://github.com/apple/corenet
















 500
500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









