






将先介绍隐私,再介绍差分攻击,由差分攻击引出差分隐私保护,最后说明差分隐私保护在深度学习领域的应用。
一、什么是隐私?
较为官方的说法是:个人隐私是指公民个人生活中不愿为他人(一定范围以外的人)公开或知悉的秘密,且这一秘密与其他人及社会利益无关。
我的理解是个人隐私强调的是个人,是某一特定人的特定属性。这样以来,例如学校发布来自湖南省的学生人数为1000人是否是泄露隐私呢?我认为不是,这则信息不涉及特定的个人。但这是否意味着可以任意发布集体性的信息呢?答案是否定的。
二、差分攻击
为什么任意发布集体性的信息也会造成隐私泄露呢?
90年代,美国马萨诸塞州政府发布了员工的医疗数据用于研究,卡内基梅隆大学的一名研究生找到了选民登记表,虽然员工医疗数据被匿名化,但有其他属性与选民登记表中相吻合,最终该名研究生推出了马萨诸塞州州长的医疗信息。
差分隐私就是为了防范差分攻击,例如学校发布来自湖南省的学生人数为1000人,而黑客在别处获取了999人的信息,那么通过对比,黑客可以获取到最后一人的信息。
而差分隐私会使得黑客查询1000人和查询999人得到的信息时是一致的,或者说黑客无法确定第1000人是否在数据集中,这样第1000人的信息就被保护了。
三、差分隐私
1.定义
两个数据集 D和 D ′ 如果有且仅有一条记录 x不同,则这两个数据集称为相邻数据集。对于相邻数据集,查询它们获得相同值的概率十分的接近。定义为:
e
x
p
(
−
ε
)
≤
P
r
[
A
(
D
)
=
0
]
/
P
r
[
A
(
D
′
)
=
0
]
≤
e
x
p
(
ε
)
exp(-ε)≤Pr[A(D)=0]/Pr[A(D')=0]≤exp(ε)
exp(−ε)≤Pr[A(D)=0]/Pr[A(D′)=0]≤exp(ε)
对任意相邻的数据集D和D’和输出O都成立。
任何满足差分隐私定义的机制都可以认为是差分隐私。
2.如何做到差分隐私?
差分隐私给数据加入扰动,添加一定的噪声使得查询结果具有一定的随机性。
以Laplace为例,首先定义敏感度,形式化表示为:
△
f
=
M
A
X
∣
f
(
D
)
−
f
(
D
′
)
∣
△f=MAX |f(D)-f(D')|
△f=MAX∣f(D)−f(D′)∣
敏感度可以的理解为查询结果对于每个个体数据的依赖程度,还是以上面的例子举例,
select count(*) from data where hometown=‘湖南’
我修改一个用户数据对结果的最大影响为1,从非湖南人改为湖南人,因此该例子中敏感度为1。
我们可以往查询结果中加入服从拉普拉斯分布的噪声
p
d
f
(
x
)
=
1
/
2
λ
∗
e
x
p
(
−
∣
x
∣
/
λ
)
pdf(x)=1/2λ*exp(-|x|/λ)
pdf(x)=1/2λ∗exp(−∣x∣/λ)
在例子中,λ取1/ε便可满足ε-差分隐私。
3.差分隐私保护机器学习模型
研究表明机器学习模型也可能会泄露隐私,原因在于机器学习会在不经意间记住数据的特征,这也是为什么在深度学习中,用于训练和测试的数据集需要分开且不重复。因此机器学习在不同数据集上的表现会有所不同,可以根据模型的表现来判断数据是否是训练集的一部分。所以攻击者可以根据发布的模型来窃取隐私数据,如针对自然语言处理的攻击,可以反推出原文本中的敏感词。
因此对于机器学习模型的保护是必要的。对于深度学习模型的保护也是添加扰动,一般方式为输入扰动、中间参数扰动、目标扰动、输出扰动。
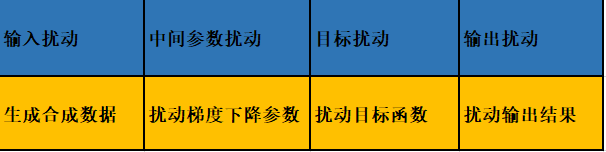
深度学习模型一般是非凸的,而且模型复杂,迭代次数多,使其满足差分隐私约束更加困难。因为保证严格意义的差分隐私(ε-DP)会导致巨额开销,因此引入宽松差分隐私(ε,δ-DP),并以此相继提出KL散度差分隐私、集中差分隐私、零式集中差分隐私、雷尼差分隐私;机器学习差分隐私定义为:
P
[
K
(
D
)
]
∈
S
]
≤
e
x
p
(
ε
)
+
P
[
K
(
D
′
)
]
∈
S
]
+
δ
P[K(D)]∈S]≤exp(ε)+P[K(D')]∈S]+δ
P[K(D)]∈S]≤exp(ε)+P[K(D′)]∈S]+δ
深度学习中使用差分隐私,如何均衡隐私保护与模型的可用性会是重难点。
















 2156
2156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











