







背景
分组计算指标是使用pandas进行数据分析的常用操作,今天分享一下groupby+apply
/agg/rank这套组合拳的用法。
数据
数据是学生id、周末参加的辅导班名称、考试成绩:
df=pd.DataFrame({‘id’:[1,1,2,2,1,1,1],‘class’:[‘a’,‘a’,‘c’,‘c’,‘b’,‘b’,‘b’],‘score’:[100,90,80,70,60,50,40]})
groupby+apply
现在想统计每个id参加的class个数(剔除重复),那么我们就可以使用groupby+apply完成这个单指标的计算。
res=df.groupby('id').apply(lambda x: x['class'].drop_duplicates().shape[0])
注意上面的x是一个dataframe:
id class
0 1 a
1 1 a
4 1 b
5 1 b
6 1 b
返回的res是series,res[id]可以得到对应的值,series有些像list+dict复合体。
#将series结果保存为dataframe
res2=pd.DataFrame()
res2['id']=res.index
res2['cnt']=res.values
groupby+agg
如果我们想统计多个指标,并且每个指标都仅仅依赖于某列,那么就非常适用于使用groupby+agg。比如统计每个id参加的class个数(剔除重复),以及其中class出现次数的最小最大值。代码如下:
def get_cnt(df):
return df.drop_duplicates().shape[0]
def get_min(df):
return df.value_counts().min()
def get_max(df):
return df.value_counts().max()
res=df.groupby('id').agg({'class': [get_cnt, get_min, get_max]})
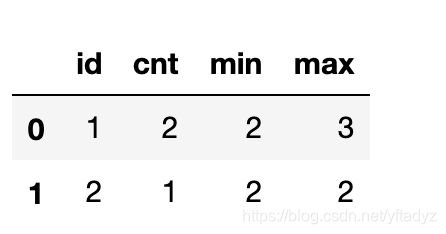
得到的res如下:

res的index是id,所以我们需要重置index,并重新对列进行命名。
res=res.reset_index()
res.columns=['id','cnt','min','max']
groupby+rank
这个组合用于分组排序。
df=pd.DataFrame({'id':[1,1,2,2,1,1,1],'class':['a','a','c','c','b','b','b'],'score':[100,90,80,70,60,50,40]})
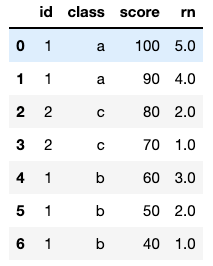
df['rn']=df['score'].groupby(df['id']).rank()
输出结果:
大功告成!
总结
| 场景 | groupby+apply | groupby+agg |
|---|---|---|
| 基于单列计算单特征 | O | O |
| 基于单列计算多特征 | O | O |
| 基于多列计算单特征 | O | X |
| 基于多列计算多特征 | O | X |
本文原创,转载请注明本文出处。

















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









