







向量化 Logistic 回归 (Vectorizing Logistic Regression)
我们已经讨论过向量化是如何显著加速你的代码,在本次视频中我们将讨论如何实现逻辑回归的向量化计算,使其能用于处理整个训练集,甚至不会用一个明确的for循环就能实现对于整个数据集梯度下降算法的优化。
让我们开始吧,首先我们回顾一下逻辑回归的前向传播步骤。假设你有个样本,为了预测第一个样本(第二个样本、第三个样本以此类推),所需的计算公式如下图:
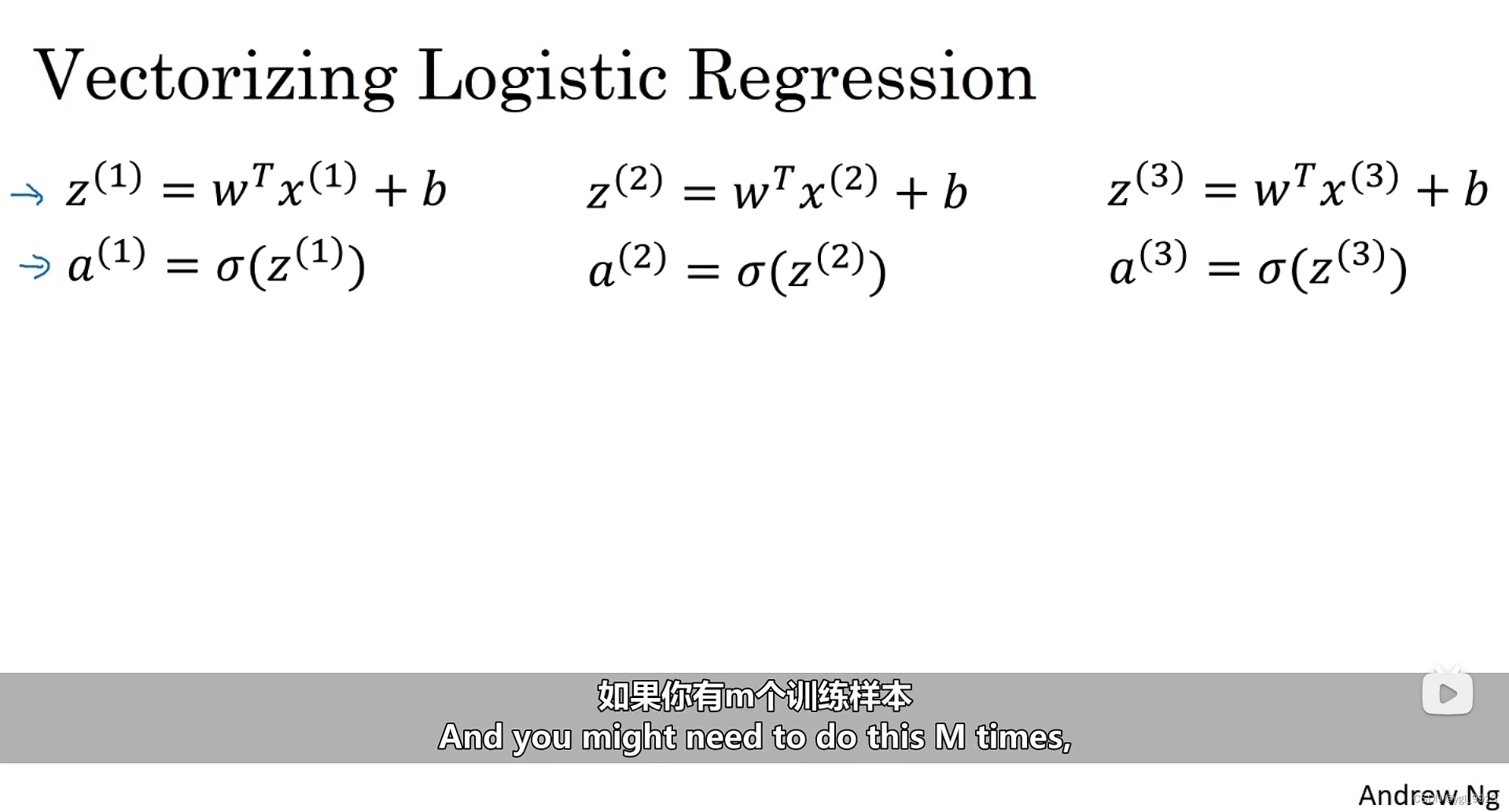
为了完成前向传播步骤,即对我们的 个样本都计算出预测值。有一个办法可以不需要任何一个显式的for循环。
首先,回忆一下我们曾经定义了一个矩阵 作为你的训练输入(一个
的矩阵),如下图,现在将它写为Python numpy的形式
。

首先我先构建一个 维的矩阵,实际上它是一个行向量,用来计算
。然后,我们再将其表示为
为了实现代码计算,在Numpy中命令,Z=np.dot(w.T,x)+b
在Python中,其实b是一个实数(当向量+实数时候,python会自动处理把b扩展为一个向量),但是可以实现它们的相加(或者把b看出一个1x1的矩阵)。这个操作在python中叫做广播(Broadcasting)
其实值得学习的就是用上面的代码来实现计算大写Z(是个矩阵)
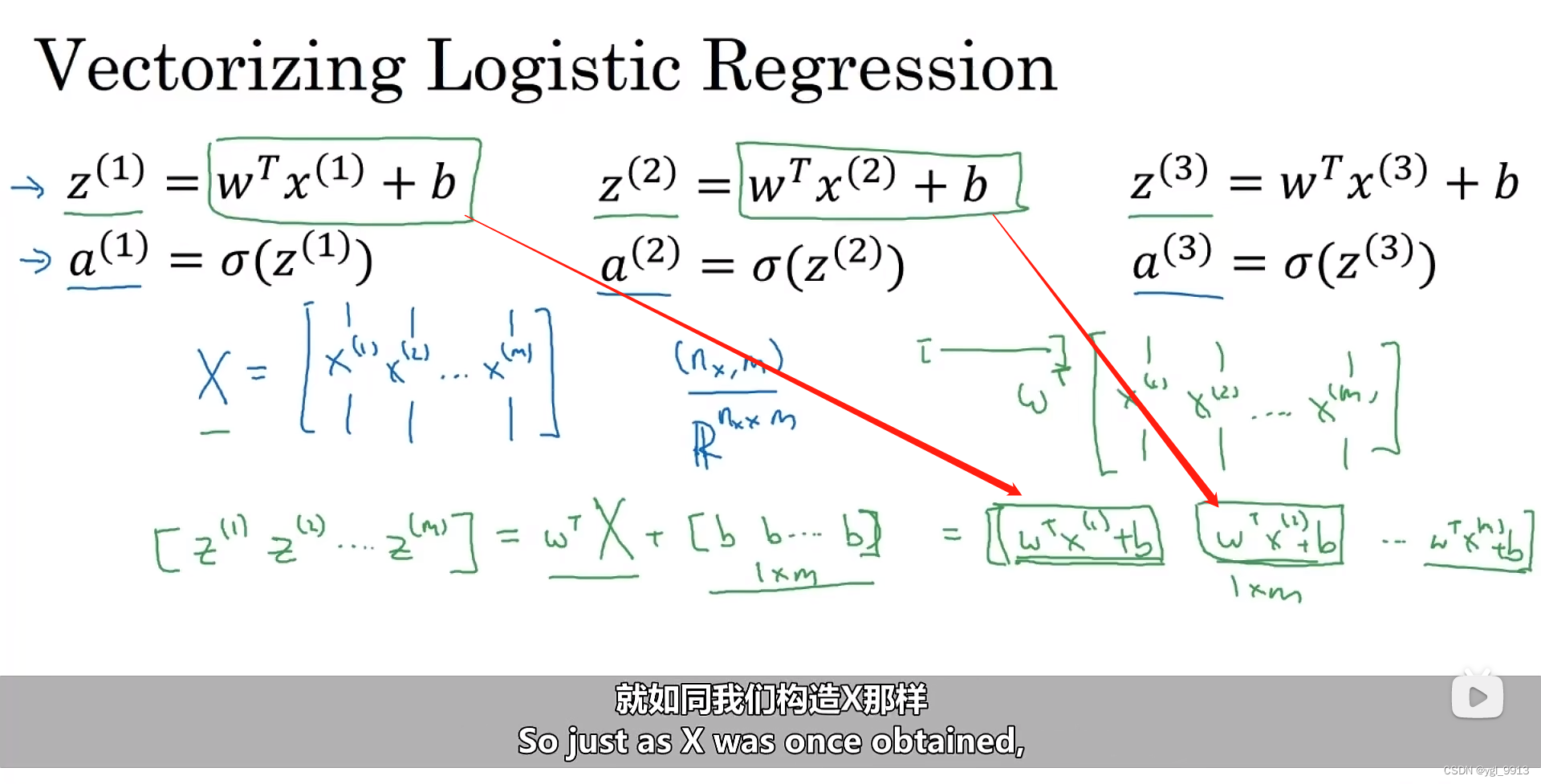
上面是就是求大写Z的过程,那如何求a的值呢?
我们下一步要做的就是找到一个同时计算 的方法。(就像我们构造X,Z一样)即
。在编程作业中,你将看到怎样用一个向量在sigmoid函数中进行计算。
总结一下,在这张幻灯片中我们已经看到,可以不需要for循环来一遍遍计算z,a,可以用一行代码 Z = np.dot(w.T,X) + b 实现同时计算所有的z或a,以及通过恰当地运用 次性计算所有 a 。这就是在同一时间内你如何完成一个所有
个训练样本的前向传播向量化计算。
概括一下,你刚刚看到如何利用向量化在同一时间内高效地计算所有的激活函数的所有 ,接下来,可以证明,你也可以利用向量化高效地计算反向传播并以此来计算梯度。让我们在下一个视频中看该如何实现。
















 28万+
28万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









