







随着数据量的爆炸性增长,如何高效、可靠地处理这些数据成为了企业和研究机构面临的一大挑战。Hadoop MapReduce,作为Hadoop生态系统中的核心组件,为大数据处理提供了强大的分布式计算能力。本文将介绍Hadoop MapReduce的基本原理、应用场景以及如何使用它来处理大数据。
目录
一、 MapReduce概述
定义:MapReduce是一个分布式运算程序的编程框架,其核心功能是将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。一个基本完整的MapReduce程序流程,包括:数据分片-数据映射-数据混洗-数据归约-数据输出
Map阶段
Map函数以键值对作为输入,并产生一系列新的键值对作为输出。这些输出键值对随后会按照键进行排序和分组。
Shuffle阶段
在Shuffle阶段,MapReduce框架会自动将Map阶段输出的键值对按照键(用户ID)进行排序和分组,确保具有相同键的值被发送到同一个Reducer
Reduce阶段
Reduce函数以排序后的键值对作为输入,对具有相同键的值进行归约操作,并产生最终的输出结果。
二、MapReduce应用场景
MapReduce广泛应用于各种大数据处理场景,包括但不限于:
1.日志分析
处理和分析网站日志、应用日志等,以发现用户行为模式、系统性能瓶颈等。
2.数据挖掘
从大规模数据集中挖掘有价值的信息,如关联规则挖掘、聚类分析等。
3.机器学习
利用MapReduce进行分布式机器学习算法的训练和预测。
4.图像处理
处理和分析大规模图像数据,如图像识别、图像分类等。
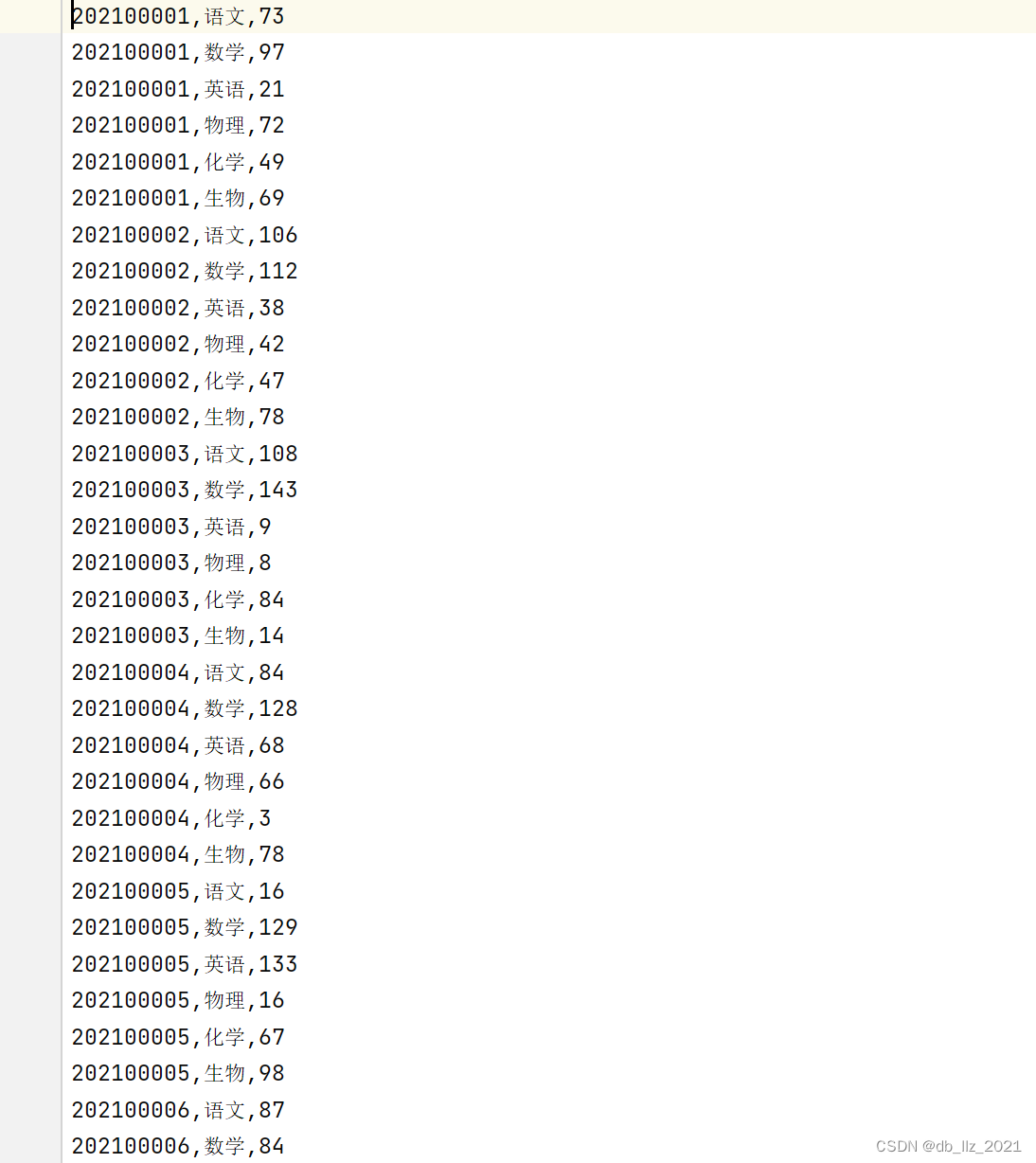
三、MapReduce案例:求平均数
数据如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









