







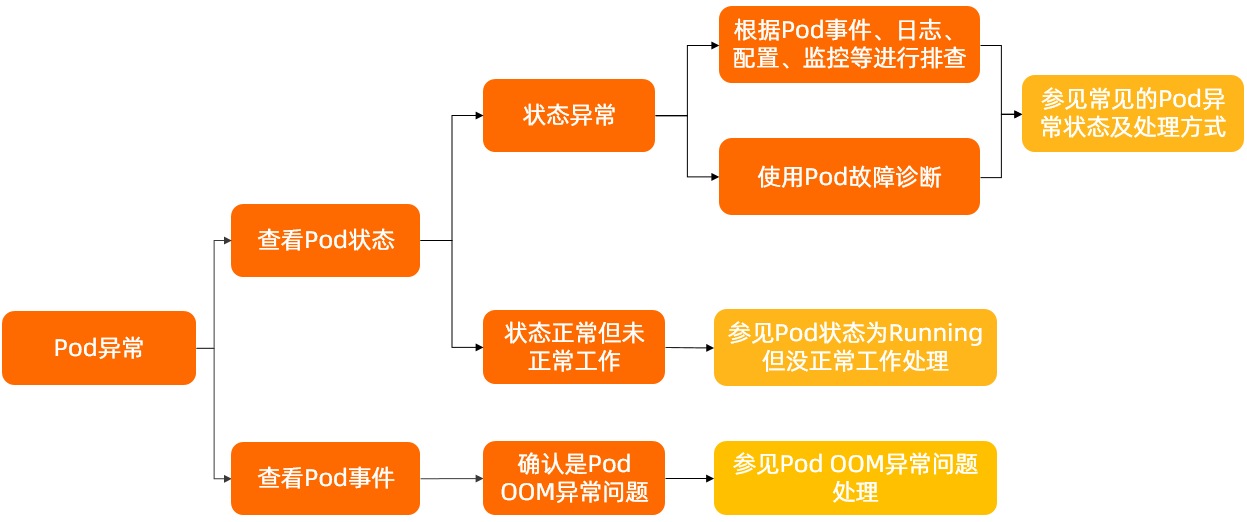
pod是业务运行的基础环境,但是在不同阶段,pod会因为某种事件发生状态变更,那么当pod状态异常时,应该如何排查呢?排查思路如下图。
Pod状态大全:Kubernetes系列-pod状态大全_kubernetes pod状态大全-CSDN博客
1. 前置条件
pod运行在node实例中,那么可能引起pod异常的原因就是node异常,因此首先需要排出node节点异常。
kubectl get nodes如果存在非reday状态,那么确认异常pod是否在一场node上部署,如果是,则需要将pod迁移至正状态正常的node上,一般情况,k8s集群会自动调度pod至正常状态的node上,不需要手动迁移。
2. pod异常状态分析
2.1 CrashLoopBackOff
参考:pod状态CrashLoopBackOff排查处理-CSDN博客
2.2 Pending
如果 Pod 一直处于 Pending 状态,通常表示 Pod 尚未被调度到节点上,或者虽然已调度到节点上但容器尚未开始运行。
排查方式
-
查看 Pod 事件:
-
使用
kubectl describe pod <pod-name>查看 Pod 的事件信息,这通常会提供导致Pending状态的具体原因。
-
-
检查节点状态:
-
使用
kubectl get nodes和kubectl describe node <node-name>查看节点的状态和资源使用情况。
-
-
检查镜像和存储卷:
-
确保镜像地址正确,PV 和 PVC 配置无误。
-
常见原因及解决方案
常见原因及解决方法
1. 节点资源不足
-
原因:集群中的节点没有足够的资源(如 CPU、内存)来满足 Pod 的资源请求。
-
解决方法:
-
使用
kubectl top nodes查看节点的资源使用情况。 -
如果资源不足,可以增加节点数量或升级节点规格。
-
2. 镜像拉取失败
-
原因:Pod 的容器镜像无法从镜像仓库中拉取,可能是因为镜像地址错误、私有仓库认证失败或网络问题。
-
解决方法:
-
检查镜像地址是否正确,确保镜像仓库可达。
-
如果是私有仓库,确保 Pod 的服务账号具有正确的镜像拉取权限。
-
3. 调度策略问题
-
原因:
-
节点选择器(NodeSelector)或亲和性(Affinity)配置错误:Pod 无法满足节点选择器或亲和性规则。
-
节点污点(Taints)和容忍(Tolerations)不匹配:节点有污点,而 Pod 没有相应的容忍。
-
-
解决方法:
-
检查并修改 Pod 的
nodeSelector或affinity配置。 -
检查节点的污点,通过
kubectl describe node <node-name>查看节点的污点。 -
在 Pod 配置中添加相应的容忍,或者删除节点上的污点。
-
4. 存储卷绑定问题
-
原因:如果 Pod 使用了持久卷(PV)和持久卷声明(PVC),但 PV 和 PVC 没有正确绑定。
-
解决方法:
-
检查 PVC 的状态,确保 PV 和 PVC 已正确绑定。
-
如果 PVC 未绑定,检查 PV 的配置是否正确。
-
5. kube-scheduler 问题
-
原因:
kube-scheduler未正常运行,或者调度器版本存在已知问题。 -
解决方法:
-
检查
kube-scheduler的状态,确保其正常运行。 -
如果调度器版本有问题,尝试升级到最新版本。
-
6. 其他问题
-
原因:Pod 配置错误(如资源限制配置不合理)、节点状态异常(如节点未就绪)。
-
解决方法:
-
检查 Pod 的配置文件,确保资源限制等配置合理。
-
检查节点状态,确保节点状态为
Ready。
-
2.3 Init:0/1
当Pod长时间处于Init:0/1状态时,表示其初始化容器(Init Container)未能成功完成。
通过kubectl get pod <podname> -n <namespace> -o yaml查pod的Init Containers,并找到init_container_name。
排查方式
查看Pod详细信息
kubectl describe pod <pod-name> -n <namespace>-
关注
Events部分:检查是否有错误事件(如镜像拉取失败、资源不足、调度失败等)。 -
检查Init Container状态:确认初始化容器是否处于
Waiting、CrashLoopBackOff或Error状态。
查看初始化容器日志
# 查看Init Container的日志
kubectl logs -n <namespace> <podname> -c <init_container_name>-
直接查看初始化容器的日志,定位脚本错误、依赖缺失或权限问题。
-
如果容器已退出,日志仍可查看;若未启动,需结合
describe结果分析。
常见原因及解决方案
原因1:镜像拉取失败
-
现象:
Events中提示Failed to pull image或ImagePullBackOff。 -
解决方案:
-
确认镜像名称、标签正确。
-
检查私有镜像的
imagePullSecrets配置。 -
确保节点有访问镜像仓库的权限(如网络策略、安全组规则)。
-
原因2:资源不足
-
现象:
Events中提示Insufficient cpu/memory或Pod卡在Pending状态。 -
解决方案:
-
调整初始化容器的资源请求(
resources.requests),降低CPU/内存需求。 -
扩容集群或释放节点资源。
-
原因3:初始化容器执行失败
-
现象:日志显示脚本错误、依赖服务不可用(如数据库连接超时)。
-
解决方案:
-
检查初始化容器中的命令或脚本逻辑,确保其能成功退出(返回码为0)。
-
验证依赖服务(如数据库、API)的可用性及网络连通性。
-
添加重试机制或超时处理到初始化脚本。
-
原因4:持久化存储问题
-
现象:
Events中提示PersistentVolumeClaim not found或挂载失败。 -
解决方案:
-
检查Pod中
volumes和volumeMounts配置是否正确。 -
确认PVC(PersistentVolumeClaim)已存在且处于
Bound状态。
-
原因5:安全权限限制
-
现象:日志提示权限被拒绝(如
Permission denied)。 -
解决方案:
-
检查Pod的
securityContext配置(如runAsUser,fsGroup)。 -
确认容器需要的Linux权能(Capabilities)是否已添加。
-
检查集群的安全策略(如PodSecurityPolicy、OPA Gatekeeper)。
-
原因6:节点调度问题
-
现象:Pod卡在
Pending状态,Events提示No nodes available。 -
解决方案:
-
检查节点污点(Taint)与Pod的容忍(Toleration)是否匹配。
-
确认节点资源充足且处于
Ready状态。
-
原因7:网络策略限制
-
现象:初始化容器无法访问外部服务或内部依赖。
-
解决方案:
-
检查NetworkPolicy是否允许流量到目标服务。
-
使用临时Pod测试网络连通性:
kubectl run -it --rm test-pod --image=alpine -- sh。
-
2.4 Terminating
2.4.1 pod或其控制器被删除
解决方案:
1)查看pod控制器类型和控制器名称,查看其控制器是否正常。
2)如果正常pod将会被重建,如果pod没有被重建,查看controller-manager是否正常
2.4.2 pod所在节点状态NotReady导致
解决方法:
1)检查该节点的网络,cpu,内存,磁盘空间等资源是否正常。
2)检查该节点的kubelet、docker服务是否正常。
3)检查该节点的网络插件pod是否正常。
2.4.3 正常变更,强制删除
kubectl delete pods -n <namespace> <name> --grace-period=0 --force2.5 Evicted
2.5.1 node节点资源达到指定阈值
原因:kubelet服务启动时存在驱逐限制当节点资源可用量达到指定阈值。资源阈值如下:
- magefs.available<15%
- memory.available<300Mi
- nodefs.available<10%
- nodefs.inodesFree<5%
当podnode资源达到以上限制会优先驱逐Qos级别低的pod以保障Qos级别高的pod可用
解决方法:增加节点资源或将被驱逐的pod迁移到其他空闲资源充足的节点上
2.5.2 node被设置污点
原因pod所在节点上被打上了NoExecute的污点,此种污点会将该节点上无法容忍此污点的pod进行驱逐
解决方法:查看该节点上的NoExecute污点是否必要,或对pod是否可以迁移到其他节点。
2.5.3 pod所在的节点为NotReady状态
通常可以通过的底部的Events信息来找到一些问题的原因。例如下面例子中可以看到DiskPressure信息,说明跟磁盘相关。
Events:
---- ------ ---- ---- -------
Warning Evicted 61s kubelet, acs.deploy The node had condition: [DiskPressure]kubectl describe pods <pod> -n <namespace>批量删除状态Evicted的pod,此操作会删除集群里面所有状态为Evicted的pod。
ns=`kubectl get ns | awk 'NR>1 {print $1}'`
for i in $ns
do
kubectl get pods -n $i | grep Evicted| awk '{print $1}' | xargs kubectl delete pods -n $i
done2.5.4 pod状态为Unknown
通常该状态为pod对应节点的为NotReady
kubectl get node2.5.5 pod为running,但是Not Ready状态
argo-ui-56f4d67b69-8gshr 0/1 Running
猜测是pod的readiness健康检查没过导致的。
kubectl get pods -n <namespace> <name> -o yaml找到健康检查部分,关键字为readiness,然后进入pod中执行健康检查命令确认。
2.5.6 pod为ContainerCreating状态
kubectl describe pods -n <namespace> <name> 查看输出的events事件部分
2.6 ImagePullBackoff
ImagePullBackoff 是一个 Kubernetes 中常见的错误状态,它表示 Kubernetes 试图从容器镜像仓库拉取容器镜像,但出现了一些问题,导致暂时无法完成这个操作。这个状态通常是临时的,Kubernetes 将会按退避算法(即逐渐增加间隔时间)重试拉取操作。
2.6.1 常见原因
- 镜像不存在:指定的镜像名或标签在镜像仓库中不存在。
- 拼写错误:在
image字段中镜像名称或标签拼写错误。 - 私有镜像仓库凭证问题:对于存储在私有仓库中的镜像,可能是因为 Kubernetes 没有正确配置访问私有镜像仓库的凭证。
- 网络问题:Kubernetes 节点无法访问或连接到镜像仓库,可能是由于网络配置或者代理设置的问题。
- 仓库限流或访问限制:一些公共镜像仓库(如 Docker Hub)对拉取频率有限制,可能触发了这些限制。
2.6.2 处理方式
- 检查镜像名称和标签:确认
image字段中的名称和标签是否正确,且镜像确实存在于镜像仓库中。 - 检查仓库凭证:
- 确认是否已为 Kubernetes 集群提供了私有仓库的访问凭证。
- 检查 Kubernetes 的 Secret 是否正确创建,并且被 Pod 引用。
- 网络连接检查:
- 检查 Kubernetes 集群的网络配置,确认节点可以访问外部网络。
- 如果使用了代理,请确保代理配置正确。
- 检查镜像仓库限制:
- 如果使用的是公共镜像仓库,如 Docker Hub,检查是否有拉取次数限制或是否需要认证。
- 查看日志和事件:
- 使用
kubectl describe pod <pod-name>查看 Pod 的事件,了解更多错误信息。 - 使用
kubectl logs <pod-name>查看 Pod 日志,获取额外的错误细节。
- 使用
2.7 ImageInspectError
ImageInspectError 是 Kubernetes 在尝试检查镜像时遇到的一个错误状态,这通常发生在 Kubernetes 在拉取镜像后,尝试读取镜像的元数据时遭遇问题。这种错误可能由多种原因导致。
2.7.1 常见原因
- 损坏的镜像:镜像文件可能在传输过程中被损坏,或者镜像本身存在问题。
- 错误的镜像格式:有时候镜像可能并不符合 Docker 或 Kubernetes 所支持的格式。
- 存储问题:节点上的存储系统出现问题,如磁盘满、文件系统损坏等,可能会导致无法正确读取镜像文件。
- 镜像拉取后的权限问题:可能是因为节点上的 Docker 或容器运行时的配置问题,导致拉取下来的镜像无法被正确读取。
- 运行时组件问题:容器运行时(如 Docker、containerd)存在问题,可能是软件缺陷或配置错误。
2.7.2 处理方式
-
重新拉取镜像:
- 删除有问题的 Pod,让 Kubernetes 尝试重新创建并拉取镜像。
- 在有问题的节点上手动尝试拉取镜像,以查看是否存在相同问题。
-
检查镜像完整性和兼容性:
- 确保镜像没有损坏,可以在其他环境中测试该镜像。
- 确认镜像格式正确,并且兼容 Kubernetes 所使用的容器运行时。
-
检查节点存储:
- 检查节点的磁盘空间,确保有足够的空间用于存储镜像。
- 检查文件系统是否完好,没有损坏或错误。
-
检查权限和配置:
- 确认容器运行时和节点上的安全策略是否允许正常访问和处理这些镜像。
- 检查是否存在与 SELinux、AppArmor 相关的安全限制问题。
-
检查和重启容器运行时:
- 检查 Docker 或其他容器运行时的状态,必要时进行重启。
- 检查容器运行时的日志,寻找可能的错误信息或警告。
-
查看 Kubernetes 事件和日志:
- 使用
kubectl describe pod <pod-name>命令查看 Pod 的状态和相关事件。 - 查看相关节点和容器运行时的日志以获得更多诊断信息。
- 使用
2.8 ErrImagePull
ErrImagePull 是 Kubernetes 中遇到的一种常见错误,它发生在 Kubernetes 尝试从容器镜像仓库拉取容器镜像时失败。这个错误可能由多种原因引起,包括但不限于网络问题、认证错误、镜像名称或标签错误等。
2.8.1 常见原因
- 镜像不存在:在仓库中找不到指定的镜像或标签。
- 拼写或路径错误:镜像名称或标签拼写错误,或者路径指定不正确。
- 认证失败:对于私有仓库,可能是因为没有提供正确的认证凭据。
- 网络问题:拉取镜像的节点无法访问镜像仓库,可能是因为网络配置或者代理设置的问题。
- 镜像仓库问题:镜像仓库服务器可能宕机或无法处理请求。
2.8.2 处理方式
-
检查镜像名称和标签:
- 确保在 Pod 定义中指定的镜像名称和标签完全正确。
- 在不同的环境中测试镜像名称,比如在本地 Docker 环境中。
-
确认认证信息:
- 如果镜像存储在私有仓库中,确保已在 Kubernetes 集群中创建了正确的 Secret,并在 Pod 定义中使用
imagePullSecrets引用该 Secret。 - 检查 Secret 中的认证信息是否正确,例如 Docker 登录凭据。
- 如果镜像存储在私有仓库中,确保已在 Kubernetes 集群中创建了正确的 Secret,并在 Pod 定义中使用
-
检查网络连接:
- 确认 Kubernetes 集群内的节点可以访问外部的镜像仓库。可以在节点上手动尝试拉取镜像。
- 如果集群使用代理,检查相关的代理设置是否正确。
-
检查镜像仓库状态:
- 确认镜像仓库是否运行正常,特别是当使用私有或自托管的仓库时。
-
检查 Kubernetes 集群和节点状态:
- 使用
kubectl describe pod <pod-name>来获取 Pod 的状态和事件信息,这通常能提供关于为什么镜像拉取失败的线索。 - 检查集群中相关节点的状态,确保它们运行正常且资源不是过度紧张。
- 使用
-
查看日志:
- 查看相关的 Kubernetes 组件(如 kubelet)的日志以获取详细的错误信息。
2.8.3 ErrImagePull 和 ImagePullBackOff区别
| 状态 | 含义 | 触发原因 | 重试行为 |
|---|---|---|---|
| ErrImagePull | 拉取镜像失败,未进入退避状态 | 镜像不存在、仓库不可达、权限问题等 | 失败后 Kubernetes 会立即重试 |
| ImagePullBackOff | 拉取镜像失败且多次重试后进入退避状态,表示 Kubernetes 会暂停一段时间再重试 |
详细解释
-
ErrImagePull
-
含义:表示 Kubernetes 在尝试拉取镜像时失败了,但还没有进入退避状态。
-
触发原因:可能是镜像名称或标签错误、镜像仓库不可达、网络问题、私有仓库的认证信息错误等。
-
重试行为:Kubernetes 会立即重试拉取镜像,不会等待。
-
-
ImagePullBackOff
-
含义:表示 Kubernetes 在多次尝试拉取镜像失败后,进入了退避状态。系统会暂停一段时间后再尝试拉取镜像。
-
触发原因:通常是由于多次
ErrImagePull状态持续发生,导致 Kubernetes 触发了退避机制。 -
重试行为:为了避免过于频繁的重试,Kubernetes 会按照退避算法(逐渐增加间隔时间)来重试拉取镜像。
-
2.9 ErrImageNeverPull
ErrImageNeverPull 是 Kubernetes 在处理容器镜像时遇到的一个特定错误。这个错误表明 Kubernetes 被配置为不去拉取镜像。
2.9.1常见原因
- Pod 配置了 ImagePullPolicy 为 Never:在这种情况下,Kubernetes 期望容器镜像已经存在于节点上,而不会去尝试从镜像仓库中拉取它。
- 使用本地开发环境:在本地开发环境(如 Minikube 或 Docker Desktop 的 Kubernetes 集群)中,可能会预先加载或构建镜像到本地环境中,而不需要从远程仓库拉取。
- 离线环境或策略限制:在某些离线环境中,可能不允许或无法从外部镜像仓库中拉取镜像。
2.9.2 处理方式
-
检查 ImagePullPolicy:
- 确认 Pod 定义中的
imagePullPolicy设置。如果设为Never,Kubernetes 将不会尝试拉取镜像。 - 如果需要 Kubernetes 从远程仓库拉取镜像,应将
imagePullPolicy设置为Always或IfNotPresent。
- 确认 Pod 定义中的
-
确保镜像在节点上存在:
- 如果
imagePullPolicy设为Never,确保需要的镜像已经在所有可能运行该 Pod 的节点上预先加载。 - 在节点上使用类似
docker images的命令来检查镜像是否存在。
- 如果
-
调整开发或部署策略:
- 在本地开发环境中,如果使用如 Minikube 或 Docker Desktop,可以通过构建镜像直接到本地 Kubernetes 环境中,或者将镜像手动加载到这些环境里。
- 在离线或受限环境中,需要将所需的所有镜像事先加载到所有节点上。
2.10 RegistryUnavailable
RegistryUnavailable 是 Kubernetes 或其他容器编排工具中的一个错误,表示无法访问或连接到指定的容器镜像仓库。这个错误通常表明 Kubernetes 集群的节点无法访问用于拉取容器镜像的注册中心(registry)。
2.10.1 常见原因
- 镜像仓库服务器宕机:容器镜像仓库可能由于各种原因(如维护、配置错误、网络问题)而暂时不可用。
- 网络问题:Kubernetes 集群的节点可能因为网络配置错误或连通性问题无法访问镜像仓库。
- DNS 解析问题:如果 Kubernetes 集群的节点无法正确解析镜像仓库的 DNS 名称,可能会导致无法访问仓库。
- 认证失败:对于需要认证的私有仓库,如果没有提供正确的凭据或凭据过期,也可能导致无法访问。
2.10.2 处理方式
-
检查镜像仓库的状态:
- 确认仓库服务器是否运行并且可以正常访问。这可能涉及检查仓库的状态页面、服务健康检查或尝试手动从仓库拉取镜像。
-
检查网络连接:
- 确保 Kubernetes 集群的节点可以访问镜像仓库的网络。可以在节点上手动尝试 ping 或 traceroute 到镜像仓库的地址。
- 如果使用了网络策略或防火墙,确保它们没有阻止对镜像仓库的访问。
-
验证 DNS 配置:
- 检查 Kubernetes 集群的 DNS 解析是否正常工作。你可以在 Pod 中尝试解析仓库的 DNS 名称来测试这一点。
-
检查认证信息:
- 如果你的镜像仓库需要登录,确保 Kubernetes 集群中正确设置了镜像拉取的 Secret,并且它们没有过期。
- 检查
imagePullSecrets是否已被正确应用到 Pod 配置中。
-
检查仓库的配置和证书:
- 对于使用 HTTPS 的仓库,确保相关的 SSL/TLS 证书是有效的,并且 Kubernetes 集群的节点信任这些证书。
- 如果你的环境有特殊的证书要求(如自签名证书),确保这些证书已被正确导入和配置。
2.11 InvalidImageName
InvalidImageName 错误在 Kubernetes 中通常指的是 Pod 无法启动,因为其定义中的容器镜像名称不符合预期格式或包含了不正确的字符。这种问题通常发生在 Kubernetes 的 Pod 配置中,特别是在 image 字段。
2.11.1 常见原因
- 格式错误:镜像名称、标签(tag)或者域名(registry domain)的格式可能不正确。例如,镜像名称可能缺少了必要的部分(如域名或标签),或者包含了非法字符。
- 使用了不存在的标签或镜像:在指定的仓库中,镜像标签可能不存在,或者整个镜像可能不存在。
- 拼写错误:简单的拼写错误,如将
latest错误地写作latset,也会导致这个问题。 - 不完整或缺少仓库地址:如果没有指定完整的仓库地址或者使用了错误的仓库地址(例如私有 Docker Registry 的地址),可能会导致此错误。
2.11.2 处理方式
-
检查镜像名称的格式:
- 确保镜像名称完整,包括仓库地址、镜像名和标签(如
registry.example.com/myimage:tag)。 - 镜像名称和标签应只包含合法字符。
- 确保镜像名称完整,包括仓库地址、镜像名和标签(如
-
验证镜像和标签的存在:
- 确认你试图使用的镜像和标签在 Docker Registry 中确实存在。
- 通过运行
docker pull <image_name>或相应的命令来本地测试。
-
检查拼写和空格:
- 确认镜像名称、仓库地址和标签的拼写正确,没有不必要的空格或拼写错误。
-
使用默认仓库(如适用):
- 如果你使用的是 Docker Hub 的公共镜像而没有指定仓库地址,可以省略仓库地址。例如,使用
ubuntu:latest而不是docker.io/ubuntu:latest。
- 如果你使用的是 Docker Hub 的公共镜像而没有指定仓库地址,可以省略仓库地址。例如,使用
-
更新和重试:
- 一旦镜像名称被更正,更新你的 Kubernetes 配置(如 Deployment、Pod 等),然后重新部署。
2.12 RunContainerError
RunContainerError 在 Kubernetes 环境中出现时,通常意味着 Kubelet 在尝试运行容器时遇到了问题。这种错误可能是由各种原因造成的,包括容器镜像、网络配置、存储问题或其他环境设置的问题。
2.12.1 常见原因
- 镜像问题:无法拉取镜像(比如镜像不存在或私有仓库认证失败),或者镜像损坏。
- 配置错误:Pod定义中的错误,比如命令行参数错误、环境变量问题等。
- 资源限制:请求的资源超过了节点的可用资源。
- 存储/卷挂载问题:无法挂载配置的卷,例如由于权限问题、不存在的路径、网络存储问题等。
- 网络问题:容器网络配置错误,或者网络策略限制了所需的连接。
- 系统级问题:节点问题(如 Docker daemon 故障、节点上其他服务占用了必要资源等)。
2.12.2 处理方式
-
检查事件日志:
使用kubectl describe pod <pod-name>查看与 Pod 相关的事件日志,这通常提供了失败的具体原因。 -
验证容器镜像:
- 确认指定的镜像是否存在,并且可以从运行节点上拉取。
- 检查是否有私有镜像仓库认证问题。
-
检查 Pod 配置:
- 确保 Pod 定义中的所有参数都是正确的。
- 检查容器的启动命令和参数。
-
检查资源请求和限制:
- 确认 Pod 的资源请求(CPU、内存)是否过高,导致无法在节点上调度。
-
检查存储和卷:
- 检查 Pod 定义的卷是否都可以正确挂载。
- 检查是否存在权限问题或路径错误。
-
网络配置:
- 确认网络策略和容器的网络配置是否正确。
- 检查是否有防火墙或安全组限制通信。
-
节点健康状况:
- 检查节点的健康状况,包括 Docker 或容器运行时的状态。
- 确认是否有足够的资源来运行容器。
-
查看 kubelet 日志:
- 如果以上步骤都无法解决问题,可以在相应的节点上查看 kubelet 的日志,获取更深入的信息。
-
重启 Pod:
- 在某些情况下,简单地重启 Pod 可能解决问题(例如,在解决了底层资源限制问题后)。
2.13 KillContainerError
KillContainerError 在 Kubernetes 环境中通常指 Kubelet 在尝试停止一个容器时遇到了错误。这个问题可能是由于底层容器运行时的问题、资源问题、或与特定容器有关的特定状态或配置问题导致的。
2.13.1 常见原因
- 容器运行时问题:例如 Docker 或其他容器运行时出现问题或不响应。
- 节点问题:节点上的资源不足(如内存、CPU),或者节点的磁盘空间不足。
- 系统级问题:例如,操作系统层面的问题,比如内核错误或者资源紧张。
- 网络问题:网络延迟或中断可能导致管理命令无法及时传达到容器。
- Kubernetes 错误:Kubernetes 自身的错误或 Bug 有时也会导致这种情况。
2.13.2 处理方式
-
查看容器和节点日志:
- 用
kubectl describe pod <pod-name>查看 Pod 的状态和相关事件。 - 检查节点(如 Docker 节点)上的日志,以确定是否有与停止容器相关的错误信息。
- 用
-
检查容器运行时:
- 检查容器运行时的状态和日志(例如 Docker 的状态和日志)。
- 尝试手动停止容器,看是否有详细的错误信息。
-
资源使用情况:
- 检查节点的资源使用情况(CPU、内存、磁盘空间)。
- 如果资源使用率过高,考虑扩容或优化应用以减少资源消耗。
-
系统和网络健康状况:
- 确认节点的系统健康状况和网络连接状态。
-
重启相关组件:
- 在某些情况下,重启 kubelet 或 Docker 服务可以恢复正常状态。
- 但这应该是最后的手段,因为它可能影响到节点上的其他容器。
2.14 VerifyNonRootError
VerifyNonRootError 是 Kubernetes 中的一个错误,指示 Pod 的容器因为某些原因无法以非 root 用户身份启动。这通常与 Pod 的安全上下文设置有关,特别是当在 Pod 或容器规范中明确要求以非 root 用户运行时。
2.14.1 常见原因
- 安全上下文配置:在 Pod 定义中的
securityContext配置要求容器以非 root 用户运行,但实际上容器尝试以 root 用户启动。 - 容器镜像配置:容器镜像可能默认以 root 用户运行,与 Kubernetes 的安全要求冲突。
- 权限或文件系统问题:容器中的应用可能需要以 root 用户权限来访问某些文件或执行特定操作,但 Kubernetes 的安全策略阻止了这一行为。
2.14.2 处理方式
-
检查和修改 Pod 安全上下文:
- 查看 Pod 或容器的
securityContext设置,确保runAsNonRoot: true和runAsUser: <non-root-user-id>配置正确。 - 如果设置了
runAsNonRoot但没有指定runAsUser,确保容器镜像以非 root 用户作为默认用户。
- 查看 Pod 或容器的
-
检查和修改容器镜像:
- 确认容器镜像的默认用户。你可以通过检查 Dockerfile 中的
USER指令来了解这一点。 - 如果需要,更改镜像以使用非 root 用户运行,或者创建一个新的镜像版本,确保以非 root 用户启动。
- 确认容器镜像的默认用户。你可以通过检查 Dockerfile 中的
-
调整应用程序的权限需求:
- 如果应用确实需要特定的权限,请仔细评估这些权限是否必要,以及是否可以通过修改应用逻辑或配置来避免这些需求。
- 有时候,你可能需要调整文件系统的权限,使非 root 用户也能访问必要的文件或目录。
-
测试和验证:
- 在进行更改后,确保在一个安全的测试环境中验证这些更改,以确保应用程序仍然按预期工作。
2.15 RunInitContainerError
RunInitContainerError 在 Kubernetes 环境中出现时,表示初始化容器(Init Container)启动失败。初始化容器是在 Pod 的应用容器启动之前运行的,通常用于设置环境、初始化配置或等待外部依赖。
2.15.1 常见原因
- 配置错误:Init 容器的配置或命令行指令有误,导致容器无法正确启动或执行所需任务。
- 镜像问题:Init 容器使用的镜像无法拉取,或镜像本身有问题(例如损坏或不包含所需的执行文件)。
- 资源限制:资源限制太严格,导致容器无法获取足够的 CPU 或内存来启动。
- 权限问题:权限设置不当,使得容器无法访问所需的文件系统或网络资源。
- 外部依赖问题:容器可能在等待外部资源或服务(如数据库、配置服务等),而这些依赖项未能按预期提供服务。
2.15.2 处理方式
-
检查 Init 容器的定义和日志:
- 使用
kubectl describe pod <pod-name>查看 Pod 详细信息和事件日志。 - 使用
kubectl logs <pod-name> -c <init-container-name>查看 Init 容器的日志。
- 使用
-
检查和修改容器配置:
- 确保 Init 容器的配置(如执行命令、环境变量等)正确无误。
- 检查 Init 容器使用的镜像是否正确且可访问。
-
调整资源限制:
- 如果怀疑资源限制问题,可尝试增加 Init 容器的 CPU 或内存限制。
-
检查权限和安全策略:
- 确保 Init 容器拥有执行其任务所需的权限,包括对文件系统、网络和其他 Kubernetes 资源的访问。
-
处理外部依赖:
- 如果 Init 容器依赖于外部服务或资源,确保这些服务可用且网络通畅。
-
查看 Kubernetes 系统日志:
- 如果上述方法都无法解决问题,可以检查 Kubernetes 节点上的系统日志,查找可能的系统级错误信息。
2.16 CreatePodSandboxError
CreatePodSandboxError 是 Kubernetes 中出现的错误,通常指在创建 Pod 的沙盒环境时发生了问题。在 Kubernetes 中,"沙盒"通常是指容器运行时的环境,这个环境为容器提供了隔离和资源控制。该错误表明在设置这个基础环境时遇到了障碍。
2.16.1 常见原因
- 网络问题:创建 Pod 沙盒时,可能会因为网络配置或网络插件问题导致失败。
- 容器运行时问题:容器运行时(如 Docker、containerd)可能遇到内部错误或配置问题。
- 资源不足:节点上的 CPU、内存或存储资源不足,无法满足 Pod 的需求。
- 系统错误:底层系统(如操作系统、内核)的问题可能导致无法正常创建沙盒。
- 安全策略限制:如 PodSecurityPolicy 或其他安全框架设置的限制导致 Pod 无法创建。
- Kubernetes 组件错误:Kubernetes 自身的组件(如 kubelet 或 API 服务器)存在问题或配置错误。
2.16.2 处理方式
-
检查网络配置:
- 确认集群的网络插件(如 Calico、Flannel)正常运行。
- 检查 Pod 的网络策略或相关的网络设置是否正确。
-
检查容器运行时:
- 确认容器运行时服务(如 Docker)正在运行并且健康。
- 检查容器运行时的日志,了解可能的错误信息。
-
检查节点资源:
- 使用
kubectl describe node <node-name>检查节点的资源使用情况。 - 确认节点上有足够的 CPU、内存和存储资源可供 Pod 使用。
- 使用
-
检查系统日志和状态:
- 查看节点上的系统日志(如
/var/log/messages、/var/log/syslog),找寻可能的错误信息。 - 确认操作系统和内核状态正常,没有出现相关的错误或故障。
- 查看节点上的系统日志(如
-
检查安全策略:
- 如果你的集群中启用了 PodSecurityPolicy 或其他安全框架,请检查相关策略是否阻止了 Pod 的创建。
-
检查 Kubernetes 组件:
- 查看 kubelet 和 Kubernetes API 服务器的日志,寻找可能的错误信息。
- 确认 Kubernetes 的组件配置正确,无误配置或兼容性问题。
-
重新调度或重启 Pod:
- 有时,简单的重新调度(删除后重新创建)Pod 或重启 kubelet 服务可以解决问题。
2.17 ConfigPodSandboxError
ConfigPodSandboxError 在 Kubernetes 环境中出现,表明在配置 Pod 的沙盒环境时出错。沙盒环境是指为 Pod 创建的隔离环境,这包括网络、存储、安全设置等。此错误通常意味着在 Pod 初始化阶段,设置这些基本组件时出现了问题。
2.17.1 常见原因
- 网络配置问题:错误的网络配置或网络插件故障可能导致配置失败。
- 容器运行时配置错误:容器运行时(如 Docker、containerd)的配置错误或故障。
- 安全设置或策略错误:例如,错误的安全上下文、权限设置或 PodSecurityPolicy 配置错误。
- 资源限制:节点的 CPU、内存限制或者其他资源限制可能导致配置失败。
- 系统级错误:底层操作系统或 Kubernetes 自身的错误,如系统调用失败、内核问题等。
2.17.2 处理方式
-
检查网络配置:
- 审核集群的网络配置,确保网络插件(如 Calico、Flannel 等)运行正常。
- 检查相关的网络策略和设置,确保它们符合集群和 Pod 的需求。
-
审核容器运行时配置:
- 确保容器运行时服务(如 Docker)正常工作。
- 检查容器运行时的配置文件和日志,寻找潜在的配置错误或警告。
-
检查安全设置:
- 检查 Pod 定义中的安全上下文设置,确保它们正确无误。
- 如果使用 PodSecurityPolicy,确保相应的策略允许所需的配置。
-
评估资源限制:
- 检查 Pod 所在节点的资源使用情况,包括 CPU、内存和磁盘空间。
- 适当调整 Pod 的资源请求和限制,确保其不超出节点可提供的范围。
-
检查系统和 Kubernetes 组件:
- 查看底层主机的系统日志(如
/var/log/messages、/var/log/syslog)和内核日志(dmesg),找出可能的错误或告警。 - 确认 Kubernetes 组件(特别是 kubelet)运行正常,检查其日志以了解更多细节。
- 查看底层主机的系统日志(如
2.18 KillPodSandboxError
KillPodSandboxError 在 Kubernetes 环境中出现时,表明在尝试终止或清理 Pod 的沙盒环境(基础的隔离环境,包括网络、存储等)时发生了错误。这种错误通常出现在 Pod 正在被删除或重启的过程中。
2.18.1 常见原因
- 容器运行时问题:问题可能出现在底层的容器运行时(例如 Docker、containerd),例如进程卡死、响应超时或内部故障。
- 资源释放问题:Pod 相关资源(如网络接口、存储卷)清理不彻底或失败。
- 节点问题:节点硬件故障、操作系统问题、或是资源极度紧张(如 CPU、内存不足)可能导致操作失败。
- 系统调用失败:底层的系统调用(如与网络或存储相关的调用)可能因权限不足、配置错误或系统问题而失败。
- Kubernetes 组件问题:kubelet 或 Kubernetes API 服务本身的故障或错误配置可能导致操作无法正确执行。
2.18.2 处理方式
-
检查容器运行时日志:
- 查看容器运行时(如 Docker、containerd)的日志,寻找任何错误或异常信息。
- 重启容器运行时服务可能有助于解决挂起或死锁问题。
-
审查资源清理:
- 检查与 Pod 相关的网络接口和存储卷,确认它们是否已经被正确释放和清理。
- 如果发现资源泄露或清理不彻底,可能需要手动介入清理或调整自动清理流程。
-
节点健康检查:
- 检查节点的 CPU、内存、磁盘空间等资源使用情况。
- 检查节点的系统日志(如
/var/log/messages、/var/log/syslog)和内核日志(dmesg)。
-
系统配置和权限:
- 确保系统配置正确,特别是与网络和存储相关的配置。
- 检查是否有任何安全策略或权限设置阻碍了正常操作。
-
Kubernetes 组件状态:
- 检查 kubelet 和 Kubernetes API 服务的状态和日志。
- 如果 kubelet 出现问题,考虑重启 kubelet 服务。
2.19 SetupNetworkError
SetupNetworkError 在 Kubernetes 环境中通常指 Pod 在设置网络(如分配 IP、设置网络路由等)过程中遇到错误。这可能导致 Pod 无法与其他 Pod 或服务正常通信。
2.19.1 常见原因
- 网络插件故障:如果使用的 CNI(容器网络接口)插件出现问题或配置错误,可能导致网络设置失败。
- IP 地址耗尽:如果集群中可分配的 IP 地址耗尽,新的 Pod 将无法获得 IP 地址。
- 主机网络问题:节点上的网络问题(如 DNS 问题、路由问题、网络接口问题)也会影响 Pod 网络。
- 资源限制:例如,安全策略(如 SELinux)或网络策略可能阻止网络的正常配置。
- 系统错误:底层操作系统或网络堆栈中的错误、驱动问题或硬件故障。
2.19.2 处理方式
-
检查 CNI 插件:
- 确保 CNI 插件正常运行并且配置正确。
- 检查 CNI 插件的日志以寻找任何错误或警告信息。
-
IP 地址管理:
- 检查 IP 地址池,确保还有足够的 IP 地址可供分配。
- 如果 IP 地址耗尽,考虑清理未使用的 IP 或扩展地址池。
-
节点网络状态:
- 检查涉及的节点上的网络配置,包括 DNS、路由和网络接口。
- 使用命令如
ip addr,ip route,nslookup等检查网络状态。
-
审查资源限制和安全策略:
- 检查是否有任何网络策略或安全策略(如 SELinux)影响 Pod 网络设置。
- 确保这些策略正确配置,允许所需的网络流量和操作。
-
操作系统和硬件检查:
- 检查操作系统的日志和状态,查看是否有与网络相关的错误或警告。
- 如果怀疑是硬件问题,如网络适配器故障,检查相应的硬件状态和日志。
2.20 TeardownNetworkError
TeardownNetworkError 在 Kubernetes 中通常表示在拆除或清理 Pod 的网络设置时遇到了问题。这种错误发生在 Pod 生命周期的末尾,当 Pod 被删除或重启时,其网络配置需要被清理。
2.20.1 常见原因
- CNI 插件问题:容器网络接口(CNI)插件可能因为内部错误或配置不当导致无法正确拆除网络。
- 资源释放问题:IP 地址或其他网络资源可能没有被正确释放回网络池。
- 节点通信问题:拆除网络时,如果节点间的通信存在问题,可能导致网络设置无法正确拆除。
- Pod 状态异常:如果 Pod 在拆除网络时处于非正常状态,可能会导致清理过程失败。
- 权限不足:执行网络拆除操作的进程可能因权限不足无法执行必要的步骤。
2.20.2 处理方式
-
检查 CNI 插件日志:
- 检查 CNI 插件的日志文件以寻找相关的错误信息。
- 验证 CNI 插件是否正确安装和配置。
-
资源释放检查:
- 检查 IP 地址和网络资源是否被正确释放。
- 在网络池中查看是否有僵尸 IP 地址或未正确清理的资源。
-
节点间通信检查:
- 确保涉及的节点间可以互相通信。
- 使用网络诊断工具(如 ping、traceroute)检查节点间网络连接。
-
检查 Pod 状态:
- 使用
kubectl get pods和kubectl describe pod <pod-name>查看 Pod 的当前状态和事件日志。 - 如果 Pod 处于异常状态,尝试解决这些问题后再进行网络拆除。
- 使用
-
权限检查:
- 确保执行网络拆除的进程具有足够的权限。
- 检查与安全策略相关的设置,如 SELinux、AppArmor 等。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











