






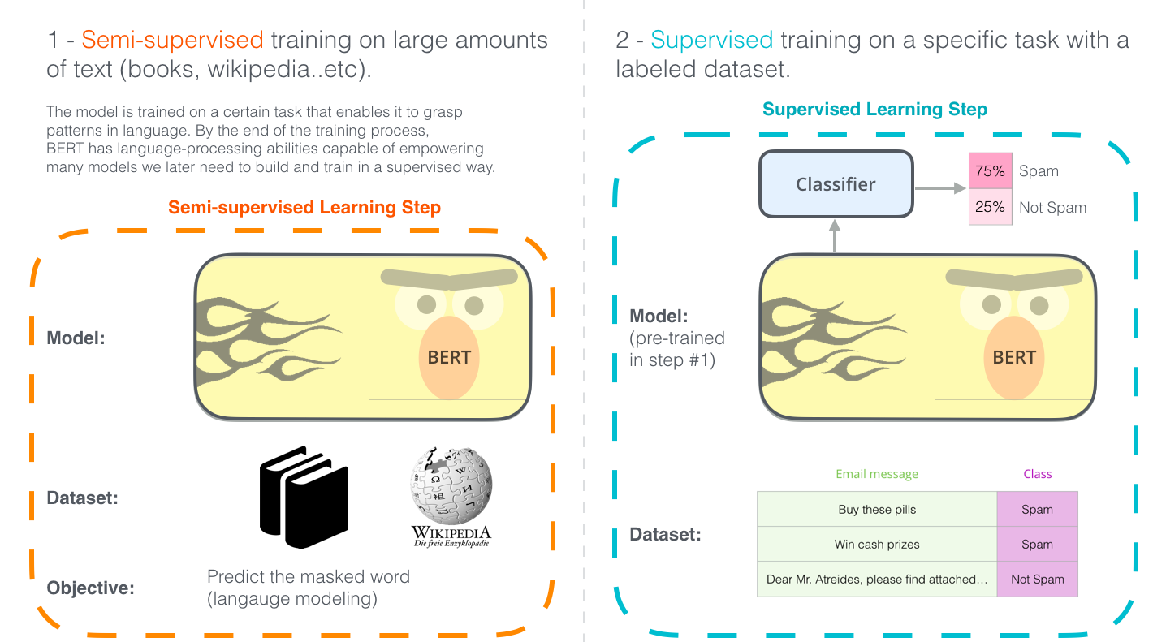
 本文概述了NLP中预训练模型的发展历程,从word2vec和GloVe的词向量表示,到ELMo引入上下文信息,再到BERT的双向动态表示。重点介绍了BERT如何结合双向上下文和微调策略,以及其在BERTBASE和LARGE规模上的应用。文章还详细讲解了BERT在下游任务中的不同输出策略,如pooleroutput和sequenceoutput,以及预训练任务MLM和NSP的实现方式。
本文概述了NLP中预训练模型的发展历程,从word2vec和GloVe的词向量表示,到ELMo引入上下文信息,再到BERT的双向动态表示。重点介绍了BERT如何结合双向上下文和微调策略,以及其在BERTBASE和LARGE规模上的应用。文章还详细讲解了BERT在下游任务中的不同输出策略,如pooleroutput和sequenceoutput,以及预训练任务MLM和NSP的实现方式。
NLP中的预训练模型
语言模型演变经历的几个阶段

- word2vec/Glove将离散的文本数据转换为固定长度的静态词向量,后根据下游任务训练不同的语言模型
- ELMo预训练模型将文本数据结合上下文信息,转换为动态词向量,后根据下游任务训练不同的语言模型
- BERT同样将文本数据转换为动态词向量,能够更好地捕捉句子级别的信息与语境信息,后续只需对BERT参数进行微调,仅重新训练最后的输出层即可适配下游任务
- GPT等预训练语言模型主要用于文本生成类任务,需要通过prompt方法来应用于下游任务,指导模型生成特定的输出。
BERT模型本质上是结合了ELMo模型与GPT模型的优势。
- 相比于ELMo,BERT仅需改动最后的输出层,而非模型架构,便可以在下游任务中达到很好的效果;
- 相比于GPT,BERT在处理词元表示时考虑到了双向上下文的信息;
Bert介绍
2018年Google发布了BERT(来自Transformer的双向自编码器)预训练模型,旨在通过联合左侧和右侧的上下文,从未标记文本中预训练出一个深度双向表示模型。因此,BERT可以通过增加一个额外的输出层来进行微调,就可以达到为广泛的任务创建State-of-the-arts 模型的效果,比如QA、语言推理任务。
当时将预训练模应用于下游任务的策略通常有两种:基于特征的(feature-based)和基于微调(fine-tuning);前者比如ELMo,后者比如OpenAI GPT;
这两种策略在预训练期间具有相同的目标函数,在预训练期间,它们使用单向语言模型来学习一般的语言表示。但当前对预训练方法的限制(尤其是对基于微调的方法)是标准语言模型是单向(unidirectional)的,所以限制了在预训练阶段可选的模型结构体系。
比如GPT是从左到右的,每个token只能关注到前一个token的self-attention layers。这种局限对于句子级任务(sentence-level tasks)来说还不是很打紧,但是对于token-level tasks(比如QA)就很致命,所以结合两个方向的上下文信息至关重要。
Bert Input
第一步:Tokenization, 输入的句子经过分词后,首尾添加[CLS]与[SEP]特殊字符,后转换为数字id
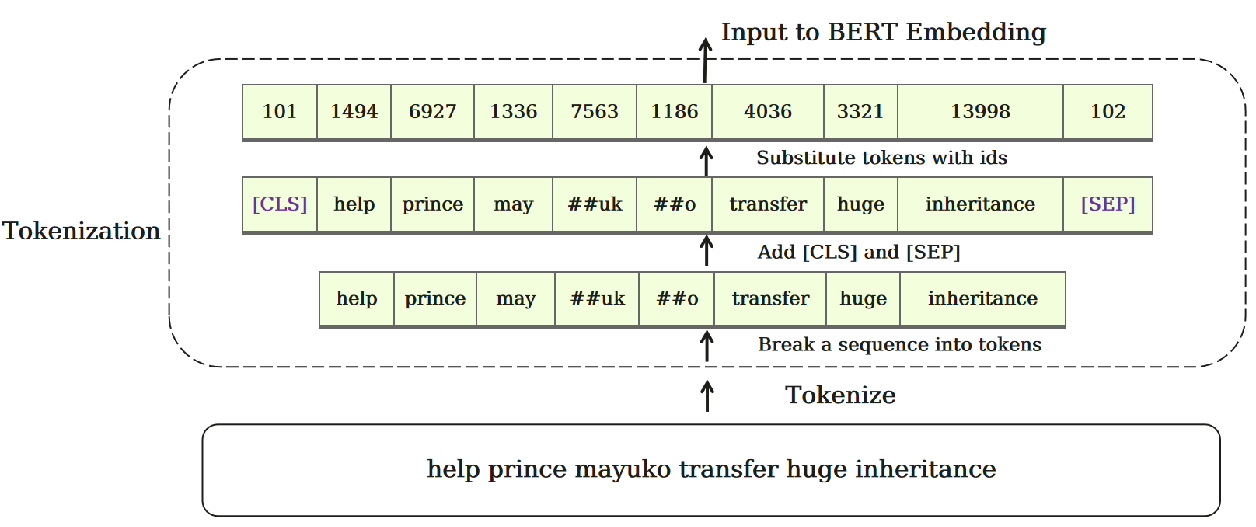
第二步:Embedding, 输入到BERT模型的信息由三部分内容组成:
- 表示内容的token ids
- 表示位置的position ids
- 用于区分不同句子的token type ids
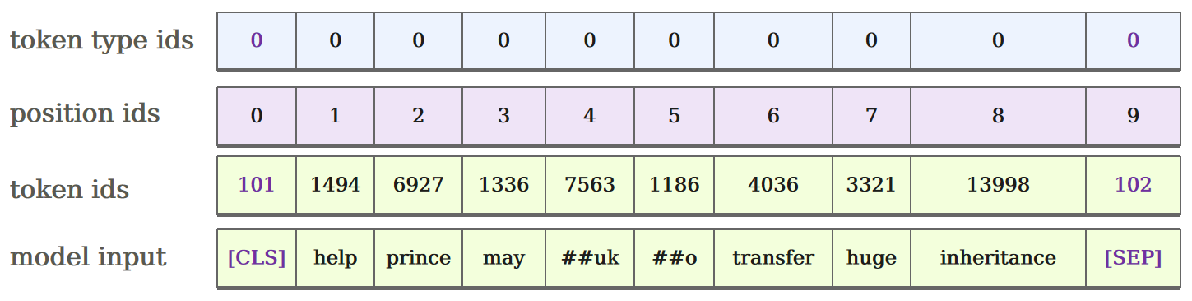
将三种信息分别输入Embedding层

如果出现输入是句子对的情况呢?

BERT Architecture
BERT由Encoder Layer堆叠而成,Encoder Layer的组成与Transformer的Encoder Layer一致:
- 自注意力层 + 前馈神经网络,中间通过residual connection和LayerNorm连接
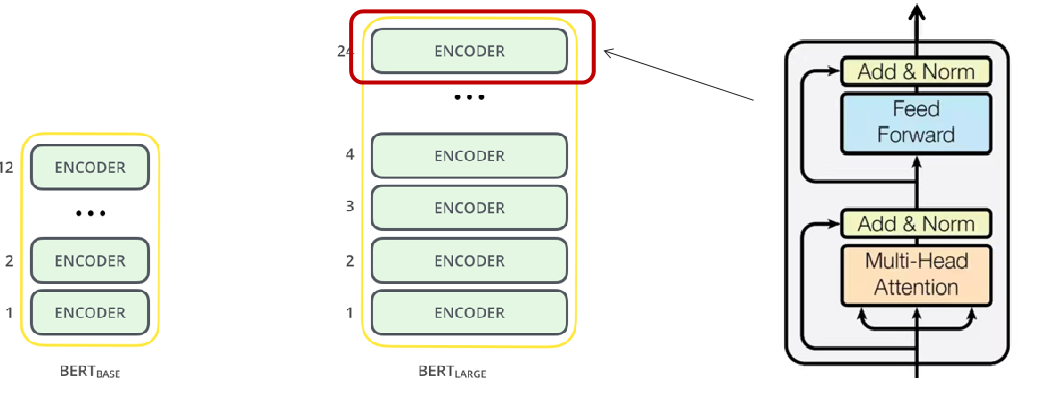
BERT(Bidirectional Encoder Representation from Transformers)是由Transformer的Encoder层堆叠而成,BERT的模型大小有如下两种: - BERT BASE:与Transformer参数量齐平,用于比较模型效果(110M parameters)
- BERT LARGE:在BERT BASE基础上扩大参数量,达到了当时各任务最好的结果(340M parameters)
BERT Output
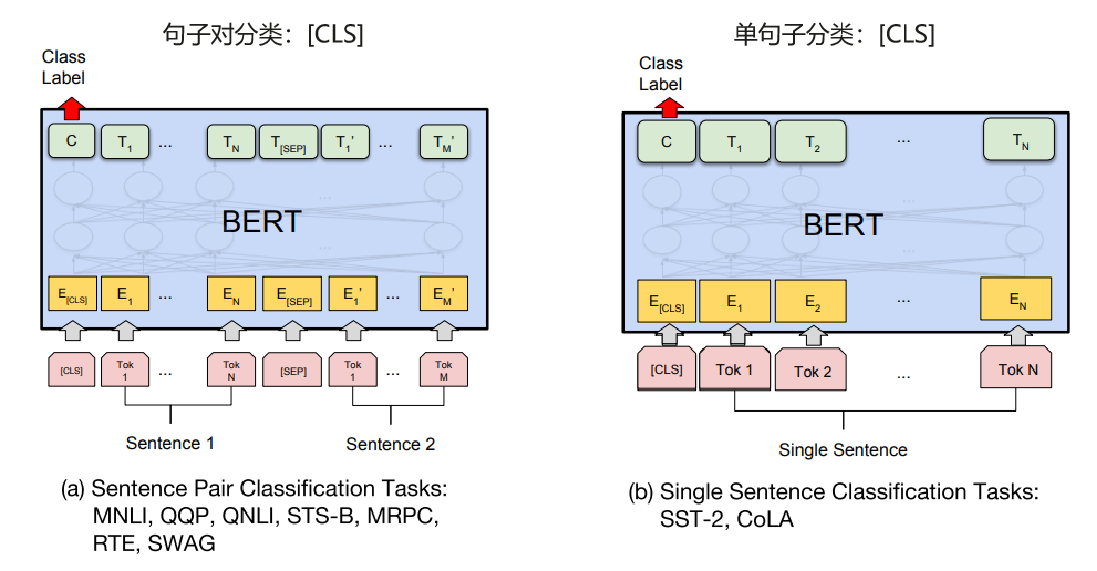
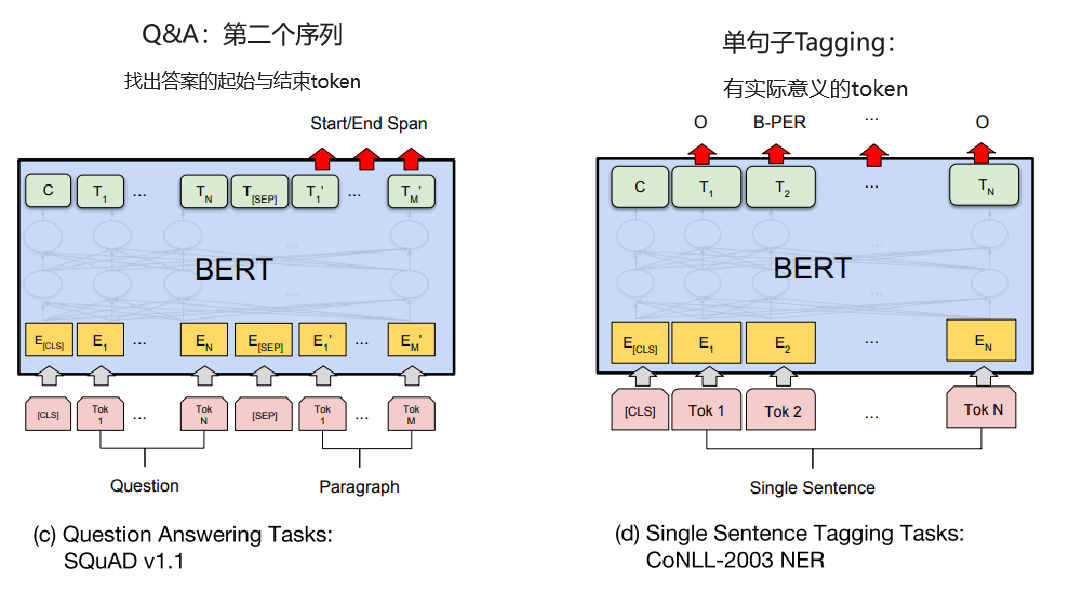
BERT会针对每一个位置输出大小为hidden size的向量,在下游任务中,会根据任务内容的不同,选取不同的向量放入输出层

pooler output
例如,在诈骗邮件分类任务中,我们会将表示句子级别信息的[CLS] token所对应的向量,经过Bert Pooler放入classfier中,得到对spam/not spam分类的预测。

我们一般称[CLS]经过线性层+激活函数tanh的输出为pooler output,用于句子级别的分类/回归任务
sequence output
例如,在词性标注任务(POS Tagging)中,我们需要获得每一个token所对应的类别,因此需要将[CLS]和[SEP]中有实际意义的token输出,分别输入对应的classifier中。

我们一般称BERT输出的每个位置对应的vector为sequence output
BERT的不同下游任务
BERT预训练
BERT预训练任务有两种:Masked Language Modelling(MLM) 和 Next Sentence Prediction (NSP)。
- MLM:随机遮盖输入句子中的一些词语,并预测被遮盖的词语是什么(完形填空)
- NSP:预测两个句子是不是上下文的关系

Masked Language Model(MLM)
Masked Language Modelling(MLM) 捕捉词语级别的信息
- 在输入中随机遮盖15%的token(即将token替换为[MASK])
- 将[MASK]位置对应的BERT输出放入输出层中,预测被遮盖的token

在将[MASK]位置所对应的BERT输出放入输出层后,本质上是在进行一个多分类任务


为了使得预训练任务和推理任务尽可能接近,BERT在随机遮盖的15%的tokens中又进行了进一步的处理:
- 80%的概率替换为[MASK]
- 10%的概率替换为文本中的随机词
- 10%的概率不进行替换,保持原有的词元

Next Sentence Prediction(NSP)
Next Sentence Prediction (NSP) 捕捉句子级别信息,简单来说是一个针对句子对的分类问题,判断一组句子中,句子B是否为句子A的下一句(IsNext or NotNext)


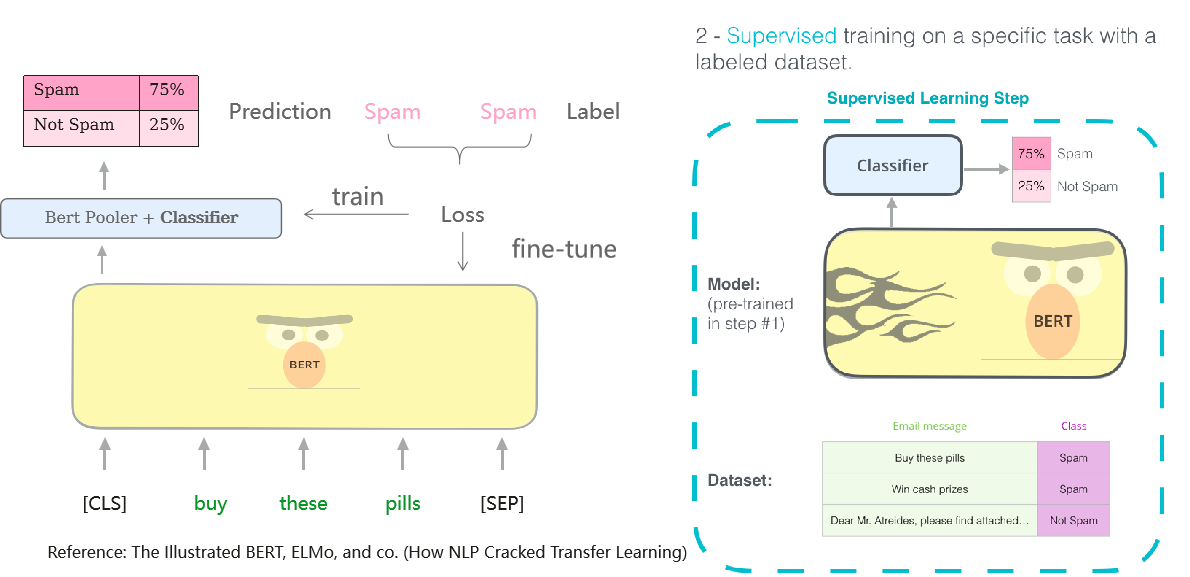
Bert微调
在下游任务中,我们使用少量的标注数据(labelled data)对预训练Transformer编码器的所有参数进行微调,额外的输出层将从头开始训练。















 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









