









一、熟悉你要爬取的页面
1,按键盘上的:F12 打开
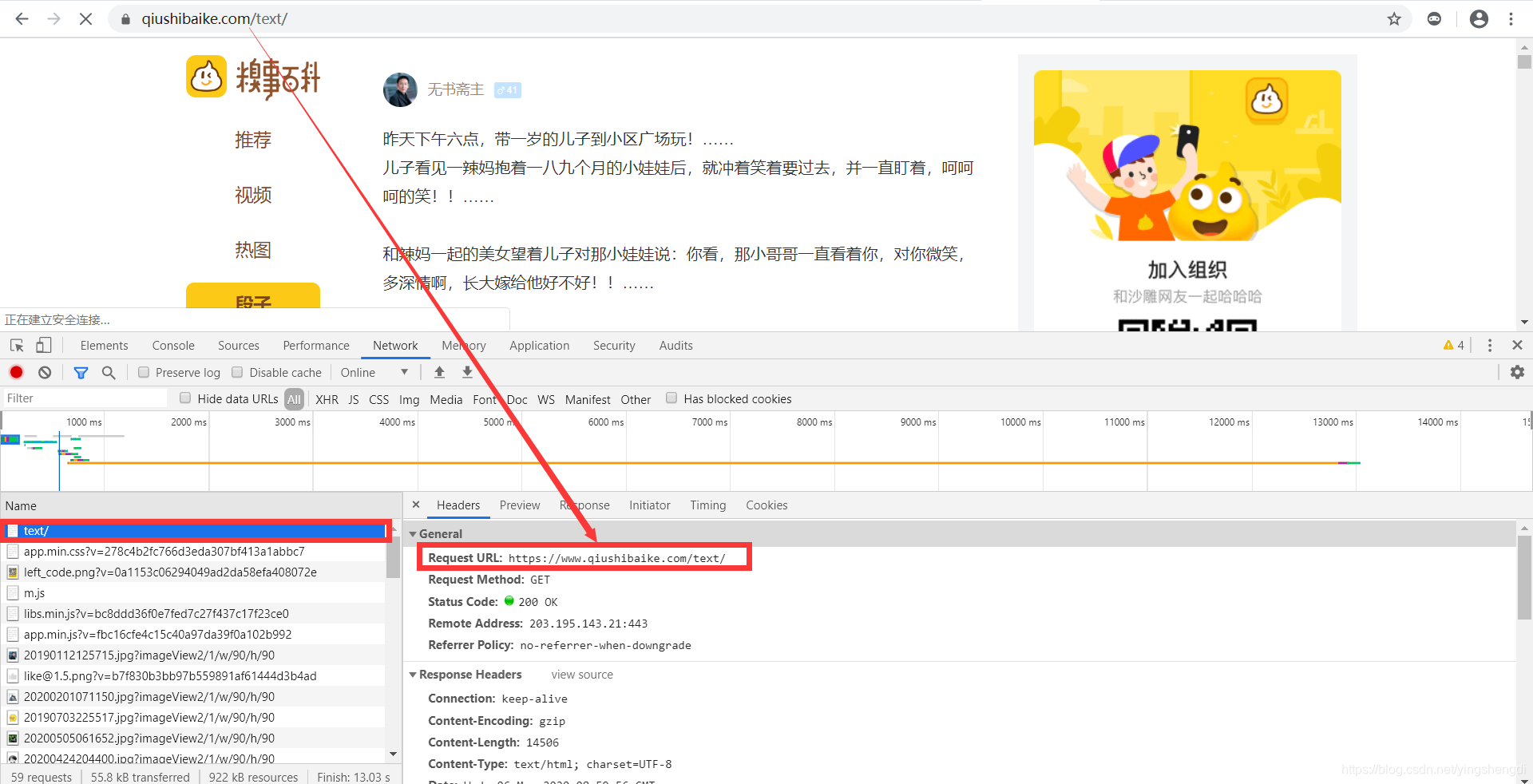
2,选择All刷新界面,F5刷新。
3,复制下面的 Request URL的数据 也就是我们要访问的url地址;
4,获取页面的请求头

前段代码如下:
import requests
import re
url = 'https://www.qiushibaike.com/text/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'
}
response = requests.get(url,headers=headers)
info = response.text
print(info)
二,使用re这个正则表达式获取我们想要的数据

右键点击检查,可以看到

所有得到正则表达式为:
infos = re.findall(r'<div class="content">\s*<span>\s*(.+)\s*</span>',info)
三、保存数据即可
所有完整的代码如下:
import requests
import re
urls = 'https://www.qiushibaike.com/text/page/{}/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'
}
i = 0
#使用死循环,获取页数
while True:
url = urls.format(i +1)
response = requests.get(url,headers=headers)
info = response.text
# print(info)
infos = re.findall(r'<div class="content">\s*<span>\s*(.+)\s*</span>',info)
# print(infos)
for info in infos:
#保存数据
with open('qiushi.txt','a',encoding='utf-8') as f:
f.write(info + "\n\n\n")
i += 1
print('已经打印了',i,"页")















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









