









Efficiently Solving the Practical Vehicle Routing Problem: A Novel Joint Learning Approach(GCN-NPEC)
KDD2020
使用GCN + 强化学习解决VRP问题
1.
1.1 目标函数:
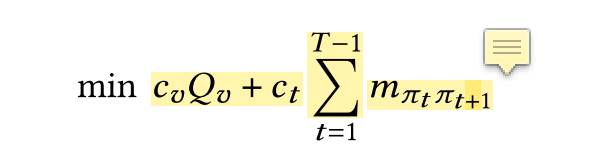
每辆车的花费 + 行驶距离
最终生成
π
\pi
π 为每个车辆的行驶路径
1.2 Graph Convolutional Networks with Node Sequential Prediction and Edge Classification
两个decoder:
3.2.1
初始化图
G
=
(
V
,
E
)
G = (V, E)
G=(V,E):
点特征(
x
i
c
,
x
i
d
x_i^c, x_i^d
xic,xid)为经纬度坐标点
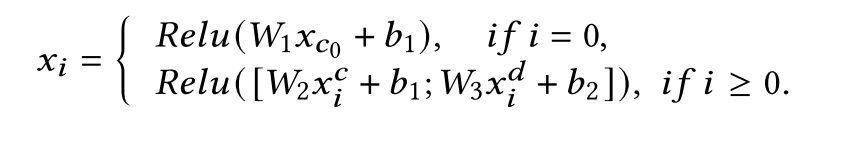
边特征:
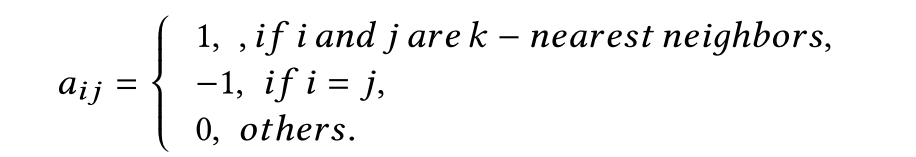

m
i
j
m_{ij}
mij两者之间距离
3.2.2 GCNEncoder
首先初始化边和点的特征embedding:
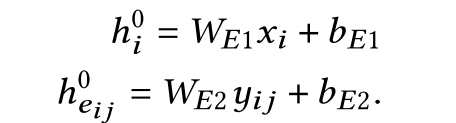
接着,假设GCN 有
L
L
L层, 每层都对node embedding做aggregation and combination :
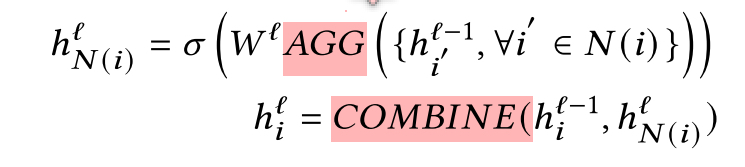
AGG:对节点i与其近邻集合
N
N
N做聚合:such as max-pooling, mean-pooling or attention based weighted summation
Aggregation sub-layer:
对于每个点:


ATTN:将节点v与其近邻做加权和
对于每个边, 与其相邻的点视为近邻,边与与其相邻的定点做聚合:
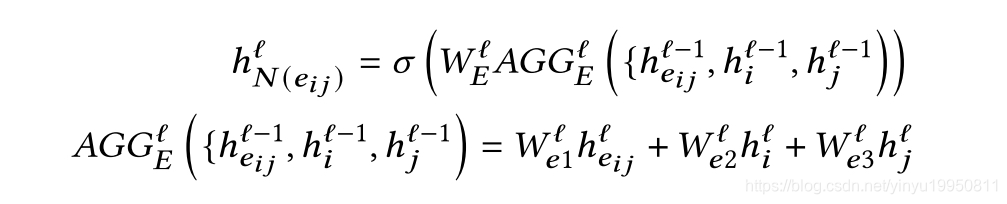
COMBINE:聚合self embedding and the aggregated embeddings
Combination sub-layer:
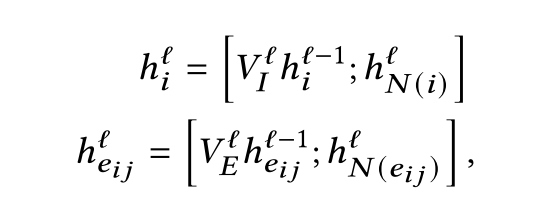
与其他GCN模型不同的是,该方法同时将边和点的特征作为输入
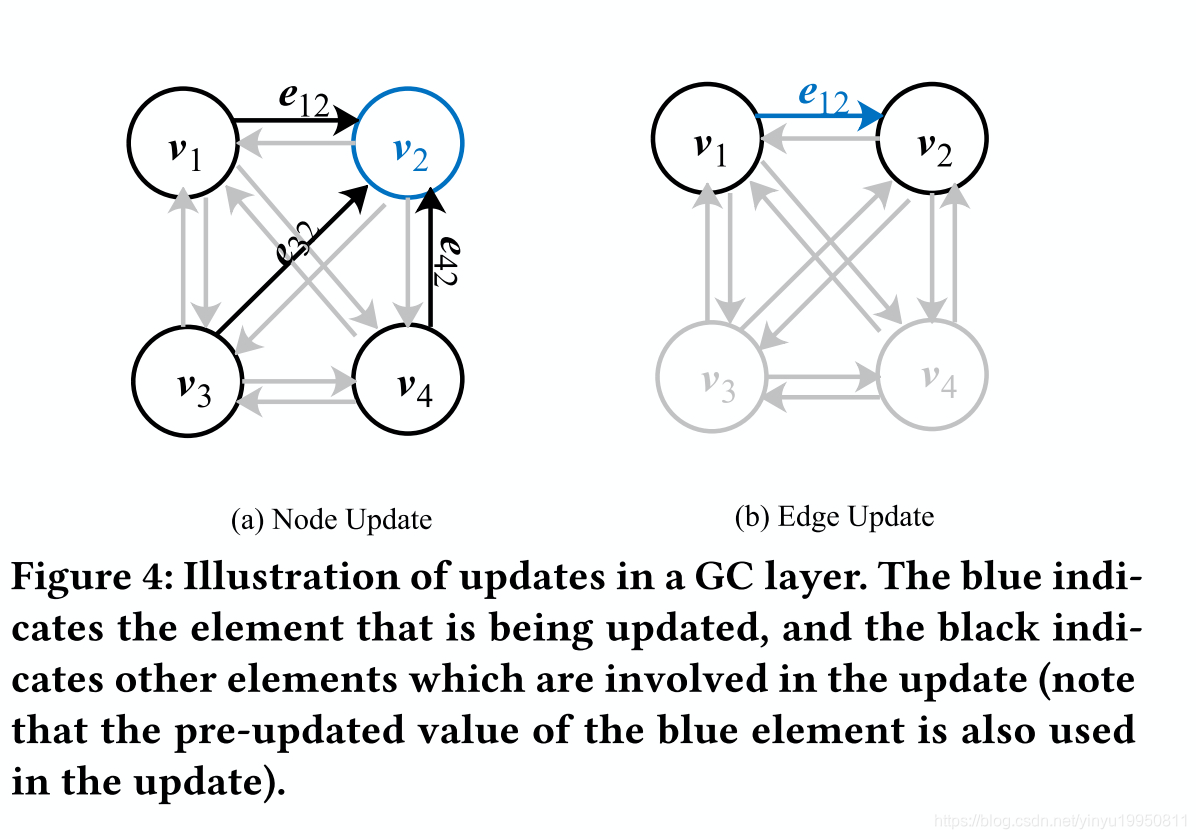
3.2.3 Decoders
给定GCN的节点和边的embedding,分别使用两个网络decode:
Sequential prediction decoder
每次生成一个序列
π
\pi
π,s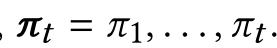
希望找打一个随机策略
P
P
P,每次最小化目标函数同时满足限制来生成
π
\pi
π
随机策略是联合概率,可以由链式规则分解:
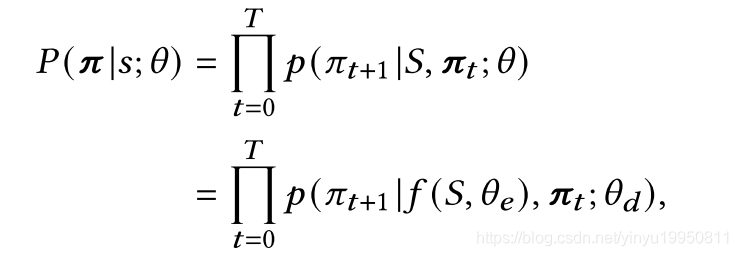
其中
f
f
f是encoder, 使用一个GRU单元引入一个状态向量
z
t
z_t
zt来将已经生成的
π
t
−
1
\pi_{t-1}
πt−1进行embedding.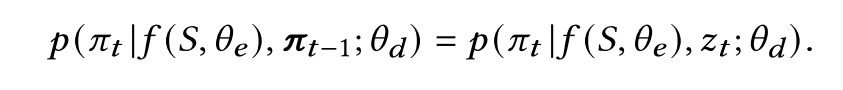
这样,每次decode根据GCN输出的node embedding 和状态向量
z
t
z_t
zt来生成
π
t
\pi_t
πt

通过attention机制 Pointer, 在应用softmax函数获得概率分布之前,它将关注编码图中的每个节点并计算注意力得分,会使得decoder关注整个输入图

其中
N
m
t
N_{mt}
Nmt为被遮挡的点(被遮挡的点不会被decoded,依赖于问题限制)
decoder过程不能超过条件限制:为此更新车剩余的容量和被访问过的节点的容量:

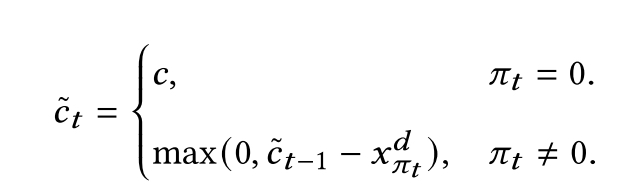
节点不允许被访问如果其容量超出当前车容量,或已经被访问,仓库不允许在t=1及其后续两个时间点被访问
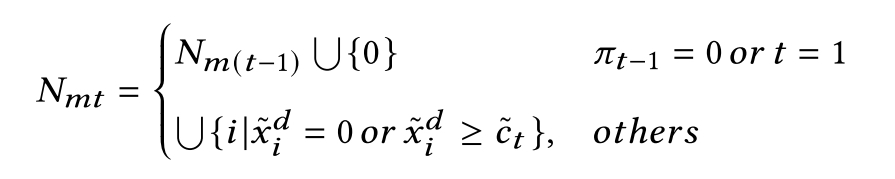
最终根据softmax函数获取point 概率分布
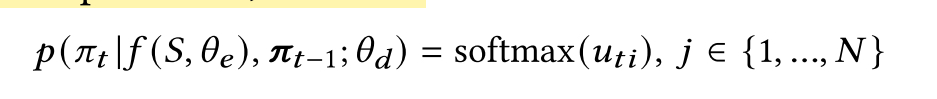
Classification decoder.
之前的方法使用最优解作为label来训练decoder,但是本文使用的是真实世界数据,最优解很难获取,这个方法并不适用。
所以一个新的想法是node和edge embedding都包含图信息和交互信息。sequence decoder生成的解和classifier decoder生成的解应该是一样的,当方法是收敛的。所以我们使用sequence decoder生成的解
π
\pi
π作为classifier decoder的label, 它们中的任何一个都可以表示VRP实例的解决方案。例如,一个序列{0,4,5,1,0}, 其对应的边为
e
04
,
e
45
,
e
51
,
e
10
{e_{04}, e_{45}, e_{51}, e_{10}}
e04,e45,e51,e10.将出现的边设为1,未出现的边设为0,可以获得一个0-1矩阵对应于一个序列,
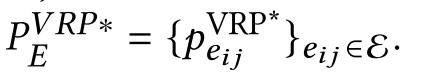
将其作为label, 在GCN的输出边embedding
h
e
i
j
L
h_{e_{ij}^L}
heijL上使用一个多层感知机(MLP),获得一个softmax分布,可以看做边
e
i
j
e_{ij}
eij是否present的概率:
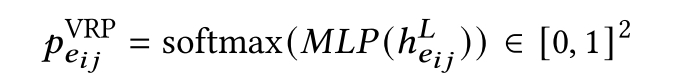
两个解码器的良性循环:
将edge embedding作为输入,分类decoder应该输出尽可能与label相近的概率矩阵
p
e
i
j
V
P
R
{p_{e_{ij}}^{VPR}}
peijVPR, 通过一个well-predicted序列, 分类器的效果会提升
通过边特征的整合,sequential prediction decoder会被提升。
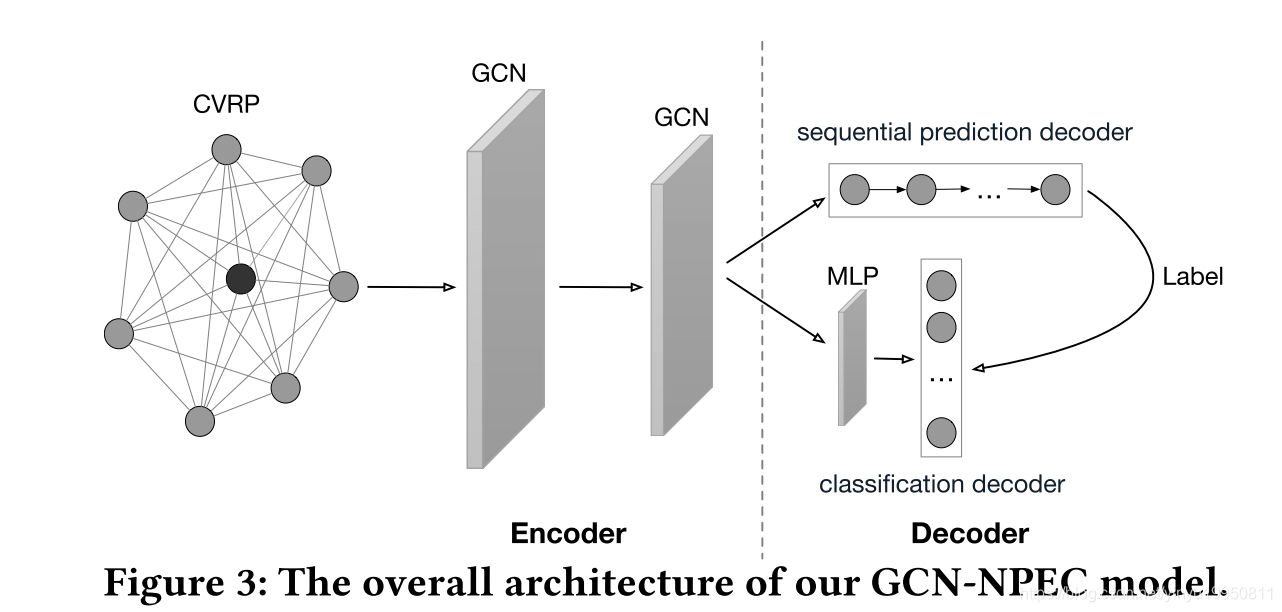
3.2.4 A Joint Learning Strategy
联合强化学习+监督学习
REINFORCE with rollout baseline
首先定义序列预测decoder的强化版loss作为期望的cost:
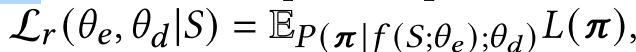
其中
π
\pi
π是解的total cost,使用策略梯度方法来训练policy:
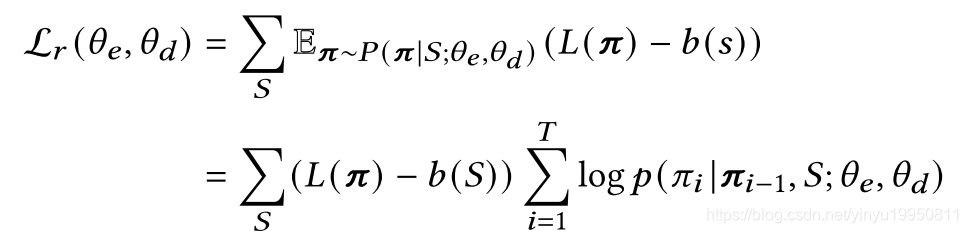
其中
b
(
S
)
b(S)
b(S)是一个确定性贪心rollout策略的cost(baseline), greedy rollout policy在每个epoch是固定的,在每个epoch截止时,如果当前policy提升显著,那么baseline policy的参数会被更新,baseline会被更新
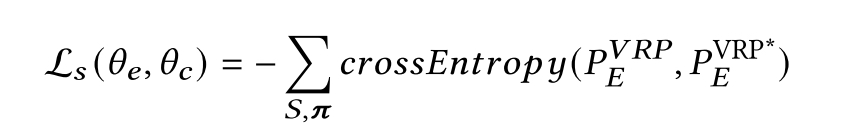
SUPERVISE with policy-sampling
训练分类decoder,给定sequential prediction decoder,输出的
π
\pi
π,
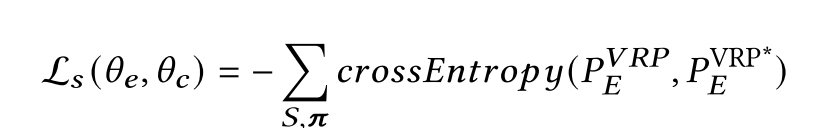
为了结合REINFORCE and SUPERVISE,将他们的损失做组合:

算法过程:
- 首先定义一个baseline policy作为trained policy
- 训练过程中baseline policy固定,直到提升是显著的
- 基于两个策略,使用sequential prediction decoder生成两个解















 1321
1321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









