










文章目录
具体方法
监督学习 + 强化学习 + MCTS
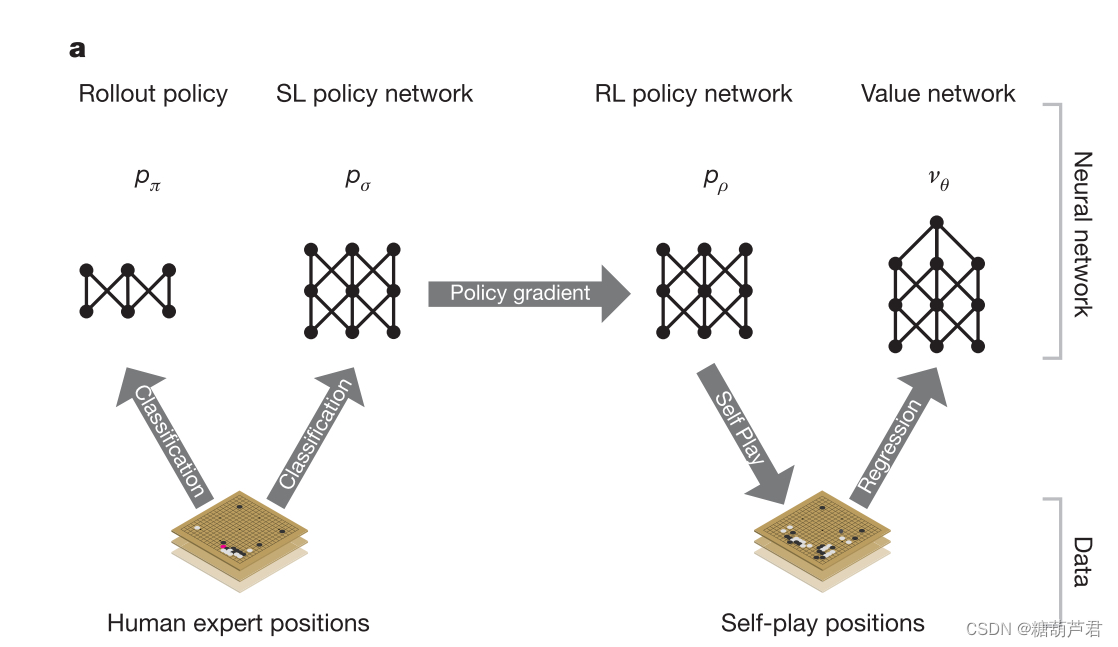
网络结构:policy-nework + value-network
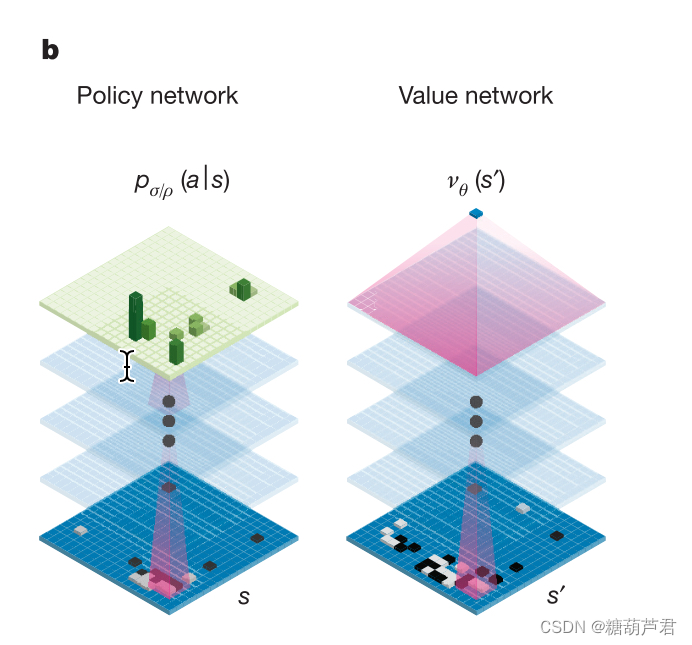
监督学习阶段
走棋网络(Policy Network)
SL-policy network
p
ρ
(
a
∣
s
)
p_{\rho}(a|s)
pρ(a∣s):
采用监督学习的方式来学习人类数据,输入棋盘特征,输出落子的概率,通过最大化似然的方式优化
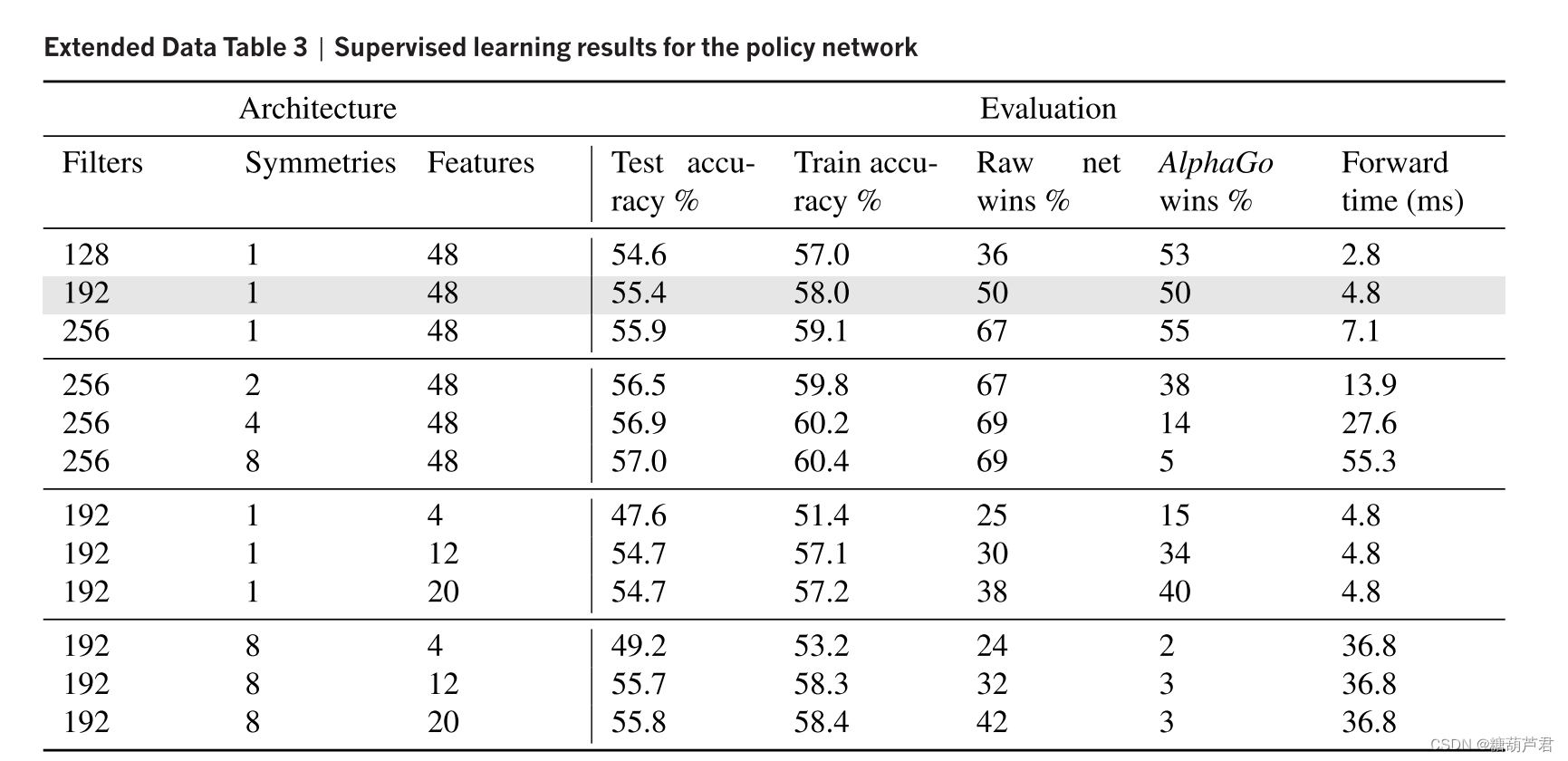
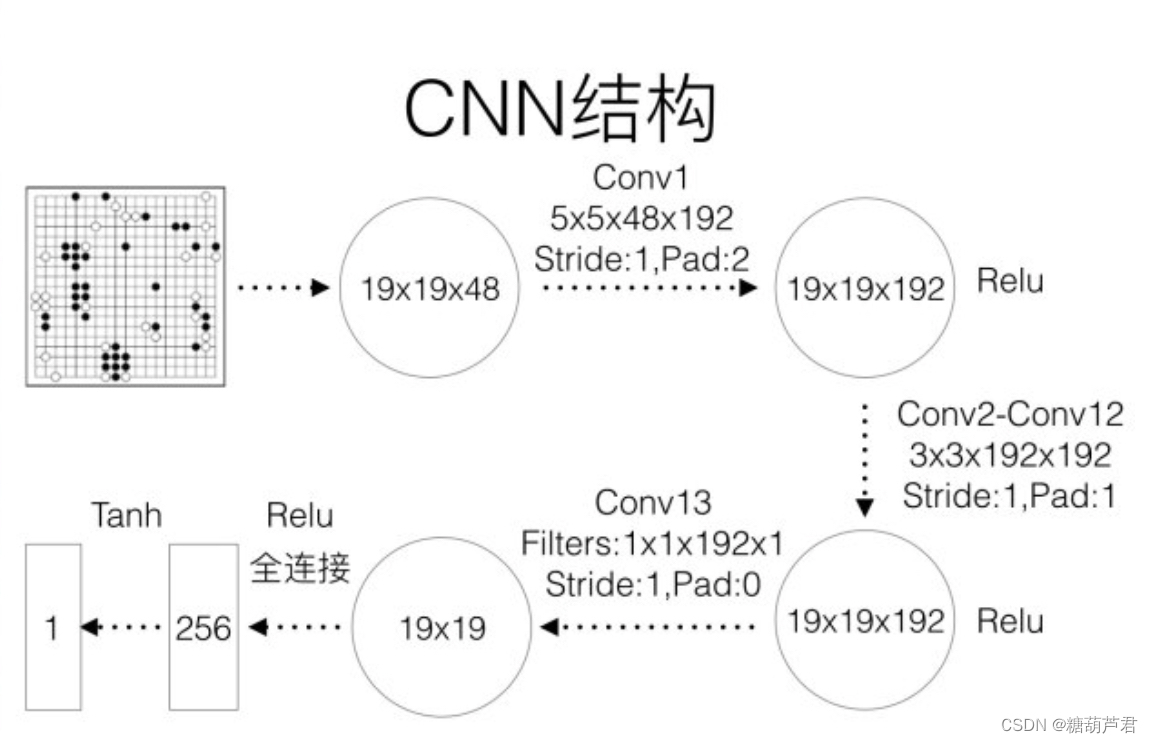
网络结构 13-layer CNN:
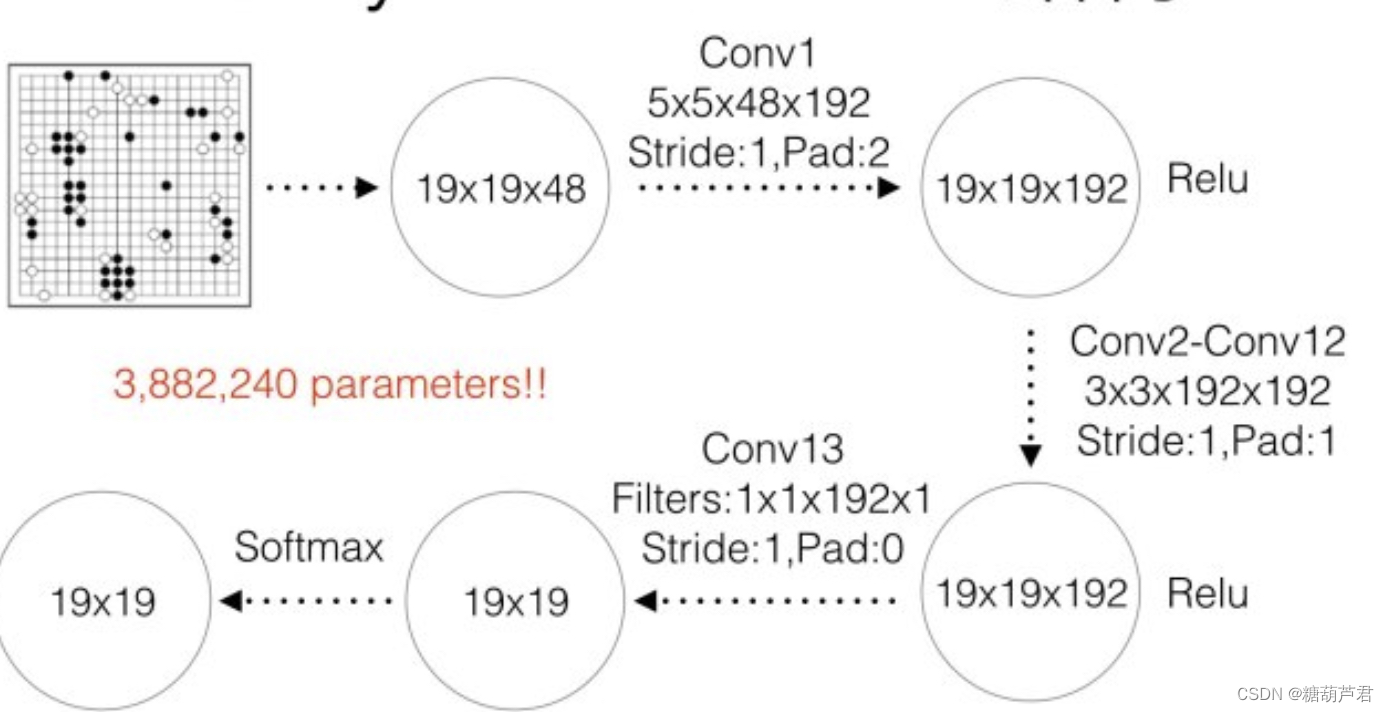
棋盘特征:
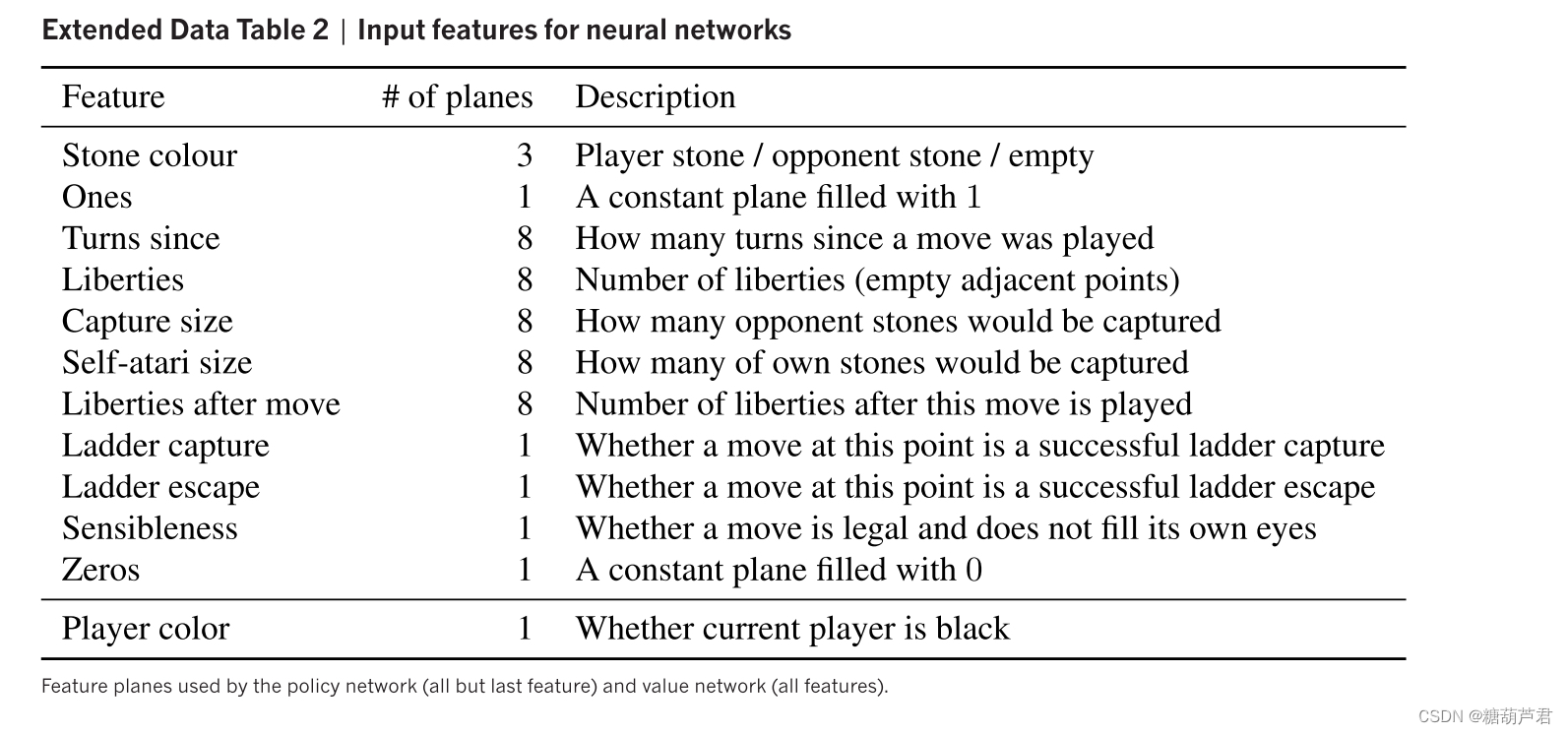
liberties:气(每个落子气的数量,临近空的点)
准确率:57% (3毫秒)
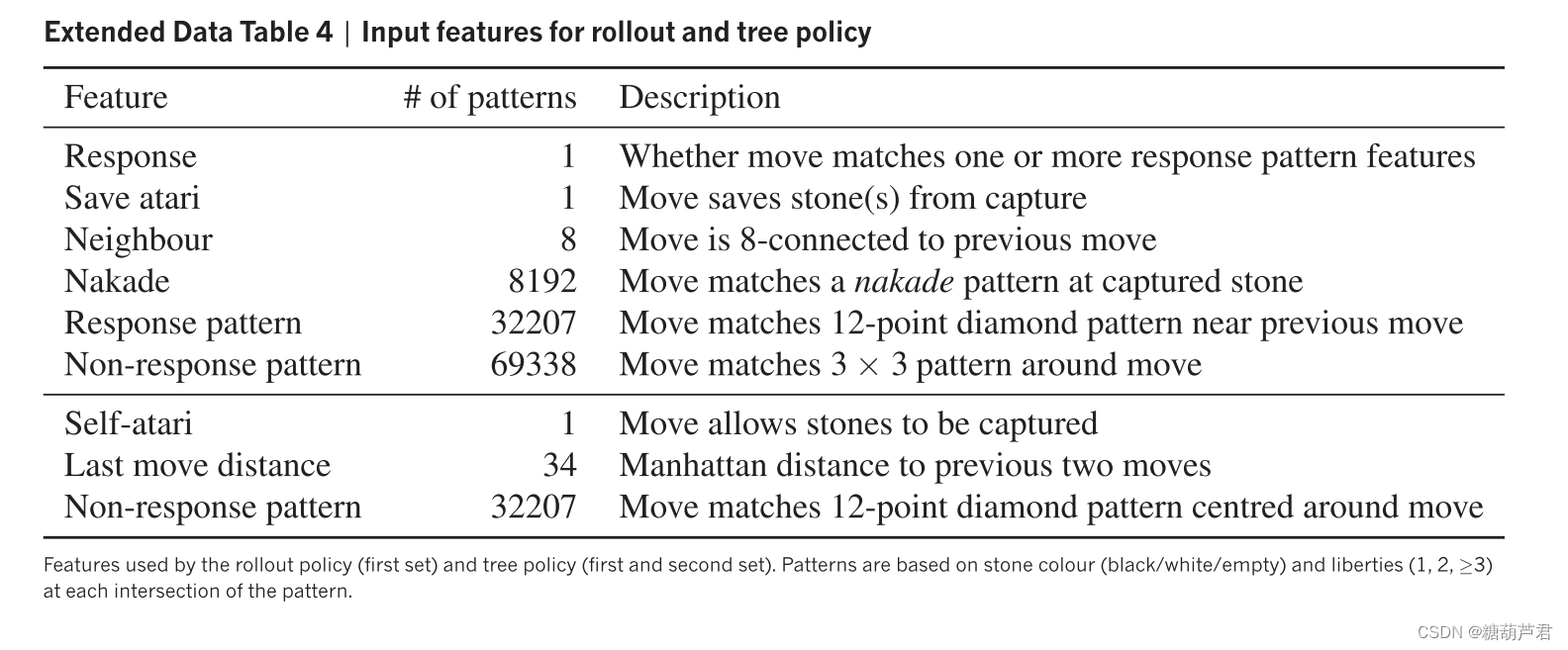
快速走子(Fast rollout)
rollout policy
p
π
(
a
∣
s
)
p_{\pi}(a|s)
pπ(a∣s):
线性softmax, 采用人工提取的围棋特征进行输入:
效果:24.2% (2微秒)
强化学习阶段
RL Policy Network + Value-Network
RL Policy Network(自我博弈过程)
在进行完监督学习之后,虽然策略网络已经有一部分模仿人类下棋的能力,但由于围棋的状态空间巨大,在监督学习时使用的数据只是冰山一角,从而可能导致策略网络在面对一个以前从未看到过的状态时做出错误的动作预测。使用基于策略梯度的强化学习,则在不需要改变策略网络结构的基础上,可以对策略网络进行进一步的优化。强化学习中的探索机制可以探索到新的状态,从而增加策略网络在状态空间上的泛化性能。
训练步骤:
-
将SL-policy network作为该阶段的初始网络RL Policy Network
-
将RL Policy Network与之前某个随机版本进行对决(防止过拟合),得到输赢结果
-
根据输赢结果使用PG算法对参数进行更新:
-
目标函数:
J ( θ ) = V π θ ( s 1 ) = Ξ π θ [ v 1 ] J(\theta) = V^{\pi_{\theta}}(s_1) = \Xi_{\pi_{\theta}}[v_{1}] J(θ)=Vπθ(s1)=Ξπθ[v1] -
Policy Gradient:
▽ θ J θ = Ξ π θ [ ▽ θ l o g π θ ( s , a ) Q π θ ( s , a ) ] \bigtriangledown_{\theta}J_{\theta} =\Xi_{\pi_{\theta}}[\bigtriangledown_{\theta}log_{\pi_{\theta}}(s,a)Q^{\pi_{\theta}}(s,a)] ▽θJθ=Ξπθ[▽θlogπθ(s,a)Qπθ(s,a)] -
reward G t G_t Gt:
其中reward函数为期望回报: z t = r ( s T ) z_t = r(s_T) zt=r(sT),当游戏终止时,赢了reward=1,输了reward = -1) -
△ θ t = α ▽ θ l o g π θ ( s t , a t ) G t \bigtriangleup\theta_{t} = \alpha\bigtriangledown_{\theta}log_{\pi_{\theta}}(s_t,a_t)G_{t} △θt=α▽θlogπθ(st,at)Gt
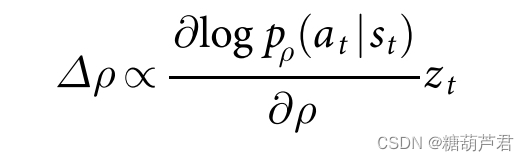
-
效果: 与SL-policy network相比取得80%的胜率
Value Network
作用:评估当前棋局的质量。
求解当前策略之下的价值函数,预测在给定策略 p 下的状态价值函数
v
p
(
s
)
v^p(s)
vp(s),其期望的形式表达为:

与 之前的网络结构相同,不同之处是最终输出一个预测值,采用MSE作为目标函数:

训练方式:
效果:

蒙特卡罗树搜索
思想:模拟人类下棋的思路,将树搜索与policy,value-network相结合,多次模拟未来的棋局,最后选择次数最多的走法:
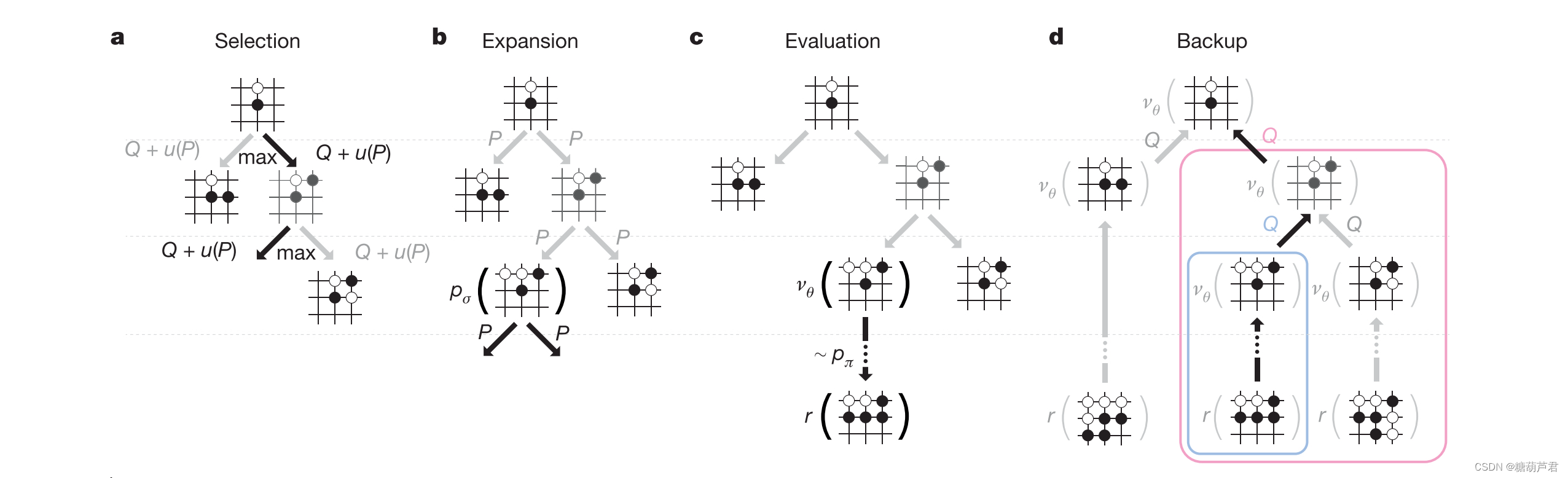
整体流程:
1.选择action:贪心选择
Q:exploit term
μ
\mu
μ: explore term
P:先验概率
![]()

其中
P
(
s
,
a
)
=
p
ρ
(
a
∣
s
)
P(s,a) =p_{\rho}(a|s)
P(s,a)=pρ(a∣s)
2. 扩展:在扩展树时,记录每条边的先验概率P

-
评估状态:value network + fast rollout p π p_{\pi} pπ共同评估节点的质量


4. 回溯:每次模拟结束之后,利用simulation过程中得到的平均访问次数与value-function对N和Q进行更新:

5. 重复该遍历🌲,最后选择被访问概率最高的节点作为下一个action:
a t ∗ = a r g m a x a N ( s t , a ) a_t* = arg max_a N (s_t, a) at∗=argmaxaN(st,a)
实验:

- 即使在 λ = 0 \lambda=0 λ=0,只使用value-network的情况下,也比其他go算法更强,这表明value-network为围棋中的蒙特卡洛评估提供了可行的替代方案。
- 当 λ = 0.5 \lambda=0.5 λ=0.5,效果最好,相互补充的作用:the value network approximates the outcome of games played by the strong but impractically slow pρ, while the rollouts can precisely score and evaluate the outcome of games played by the weaker but faster rollout policy pπ.
Q:
- fast rollout的作用是为了在MCTS中进行快速扩展simulation,训练Value-network的目的是什么呢, 为什么能够加快MCTS的搜索速度 ?
- 训练value-network为什么要使用self-play的数据?
- 为什么在MCTS结束后使用访问次数最大的,而不是value-function最大的?
- MCTS搜索细节?
- 为什么CNN没有使用池化层?–特征消失?
参考资料:
- Mastering the game of Go with deep neural networks and tree search
- https://www.leiphone.com/category/zhuanlan/Q1cWFZjnGl1wc4m1.html
- https://zhuanlan.zhihu.com/p/423253822

















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









