







A股上市公司年报,是我们分析上市公司财务状况和经营状况,并进行股票估值和行情预测的重要依据。那么,我们应该如何爬取这些上市公司的财报数据,并用于数据分析和可视化呢?今天我们以东方财富网为例,来介绍一下基本的步骤。
一、操作环境
1. 浏览器:Safari浏览器(版本:17.31)
2. Python版本:Python3.12
3. 开发环境:Pycharm 2023.3(Community Edition)
4. 操作系统:MacOS 14.3(Sonoma)
二、网页解析
1. 点击如下网址,进入数据页面
2. 页面空白处“点击右键”——“检查元素”,进入开发者工具。
选择”网络“标签页,然后刷新网页,获取所有网页加载项。
3. 对列表中的所有加载项依次进行预览,寻找数据源地址。
以本次操作为例,数据源的网址为(数据源网址是动态生成的):
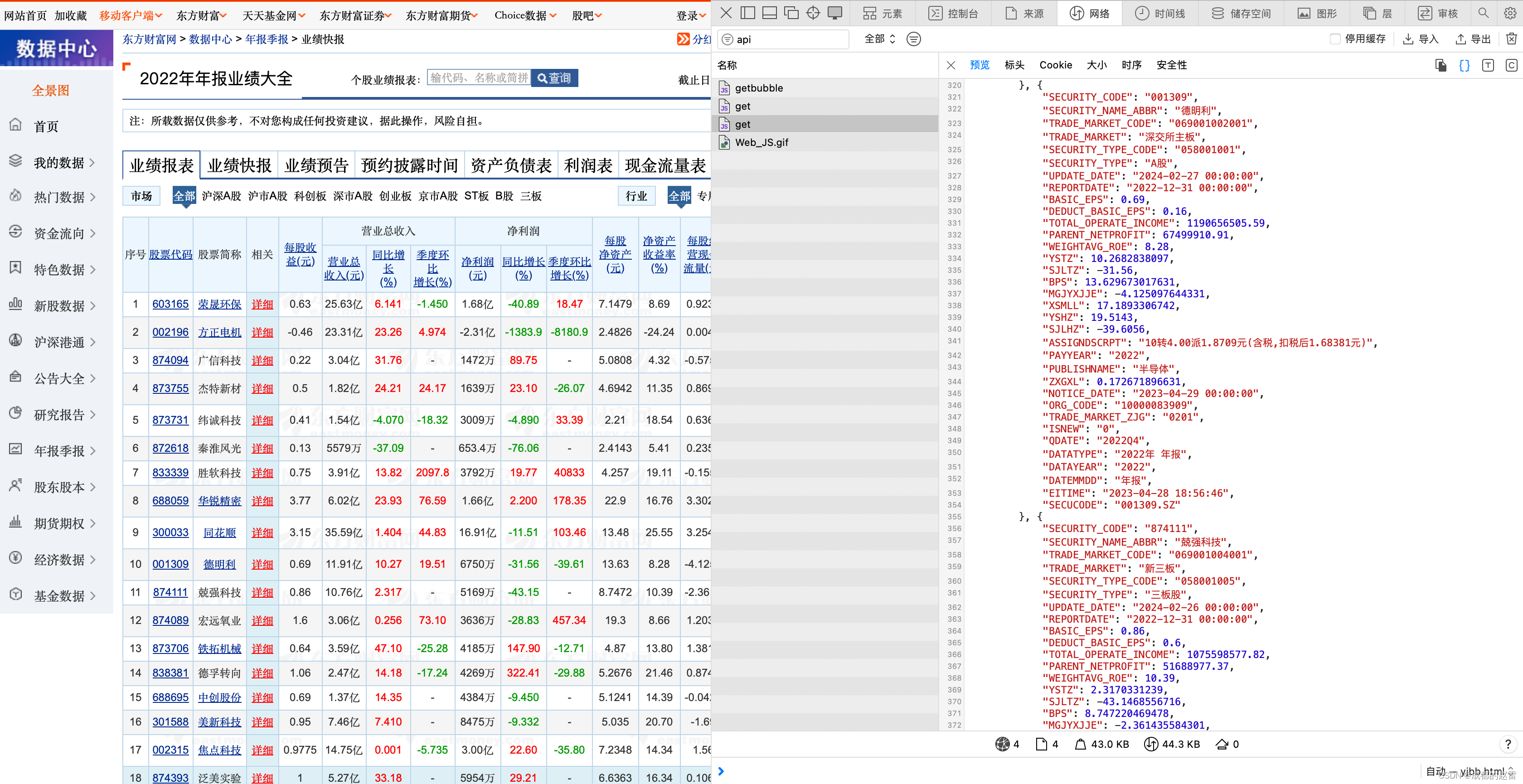
4. 分析数据源网址,找出真正的数据源接口
一般网址的基本结构为:
协议://域名(IP:端口)/资源路径?查询条件(结构:key1=value1&ke
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 257
257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









