









摘要
本文介绍HBase在CentOS下的安装部署,以及基于Scala语言在Spark上读写HBase的简单实例。
1.HBase简介
Hbase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。Hbase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。
那么关系型数据库已经流行了很多年,并且Hadoop已经有了HDFS和MapReduce,为什么还需要Hbase?原因有以下三点:
- 为Hadoop可以很好地解决大规模数据的离线批量处理问题,但是,受限于Hadoop MapReduce编程框架的高延迟数据处理机制,使得Hadoop无法满足大规模数据实时处理应用的需求。
- 是HDFS面向批量访问模式,不是随机访问模式。
- 是传统的通用关系型数据库无法应对在数据规模剧增时导致的系统扩展性和性能问题。
2.HBase安装部署
2.1部署结构
如图下所示为Hbase的部署示意图。Hbase必须依赖Zookeeper,可以使用HBase本身自带的Zookeeper,也可以自行安装,我们选择自行安装,不使用HBase自带的。Zookeeper选用分布式集群模式,按照奇数个zk进程的原则部署,因此选择在node01、node02、node03三个节点上部署。Hbase同样采用分布式集群模式,在node01、node02、node03、node04四个节点上,配置node01为HMaster,其他节点为HRegionServer。

2.2 Zookeeper安装配置
zookeeper安装主要分为如下三步:
1.配置bashrc文件,将zookeeper路径添加到环境变量中,如图4-2所示。

2.修改zookeeper_home/conf/zoo.cfg配置文件,如下图所示。

3.将上述修改同时应用的node02,node03节点上,使三个节点zookeeper配置均保持一致。
最后,在三个节点上启动zookeeper后,查看各节点zk运行情况如下图所示。

2.3 Hbase部署安装
Hbase安装主要分为三步:
1.配置bashrc文件,将hbase路径添加到环境变量中,如下图所示

2.配置hbase-env.sh文件,设置jdk路径,并配置使用外部zookeeper,如下图所示。

3.配置hbase-site.xml文件,如下图所示。

4.配置regionservers文件,在regionservers文件中指定区域服务器地址,如下图所示。

2.4 Hbase启动异常分析
Hbase启动异常分析
在启动Hbase时遇到如下图所示的错误,从错误提示可以看出由于主从节点的时钟相差超过Hbase设置的阈值30000ms,导致这个错误。

解决方法很简单,使用时钟校对命令更正各节点的时间即可,命令如图所示。

完成时钟同步后,启动Hbase,使用Jps命令查看启动结果如图所示。

3.park读写Hbase数据库
Hbase中user表结构
我们在hbase中创建一个user表,该表有一个info1的列族,该列族有name,subject,scores三个列,结构如表所示。
| 列族 | info1 | ||
| 列 | name | subject | scores |
3.1从HDFS读入数据写入Hbase
代码解析
代码主要分为三块内容:
(1)指定zookeeper及hbase的表名
(2)从hdfs读入待写入user表的文本数据,该数据格式为每行分别为序号,姓名,课程,分数,按逗号分隔
(3)将读入的文本每行按逗号分割,创建put对象,设置每行的行键及列数据,并写入数据表user

运行结果
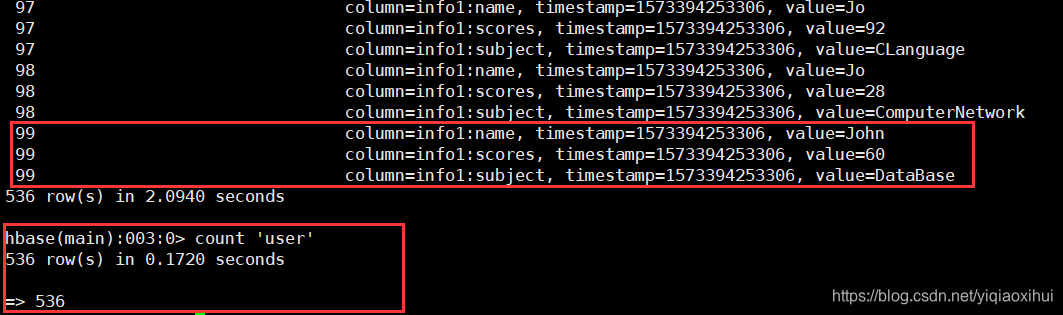
将上述程序通过maven打成jar包,使用spark-shell命令执行该程序后,通过hbase shell命名可以查看是否写入成功,结果如图所示,从图中可以看出一共写入了536行,与预期写入数据量相符。
3.2 从Hbase中读取user表
1.代码解析
代码主要分为三块内容:
(1)指定zookeeper及hbase的表名
(2)从hbase读取数据并转化成RDD
(3)提取每行数据,并打印输出结果

运行结果
将上述程序通过maven打成jar包,使用spark-shell命令执行该程序后,通过hbase shell命名可以查看是否读取成功,结果如图4-16所示,从图中可以看出一共读取了536行,与预期读取入数据量相符。

3.3遇到的问题及解决方案
Maven打包时报错
(1)打包时首先遇到如图4-17所示的错误,大概意思是SparkSession不是某个jar包里的对象,很可能是该程序缺少相应的jar包,在pom.xm文件中添加spark-sql_2.11依赖解决。

(2)打包时另一个错误是提示存在多版本的scala的错误,通过删除bulid模块下的maven-scala-plugin版本信息解决问题。

程序运行时报错
(1)缺少各种jar包依赖
由于spark缺少hbase的各种jar包,产生了各种不明的错误,通过查阅资料,将hbase中的hbase-*.jar, htrace-core-*.jar, "hbase-protocol*.jar, metrics-*.jar复制到spark_home/jars文件夹下即可解决各种错误,常见错误如图所示。


程序代码错误
在写入hbase数据库实验中,还出现了如图4-20所示的错误,在网上没有查到相关的错误解决方法,后来仔细考虑错误提示,意思是指未指定表名,再次查看代码发现hbaseConf设置表模式时写成了读取模式,而不是写入模式,如图4-21所示。这一错误原因首先是对hbase编程不熟悉,不了解两种模式的区分,事实上在参考网上相关代码时,直接把读取的部分复制过来,没有看清两者在参数的区别。


参考资料
4. spark将数据写入hbase以及从hbase读取数据
8. 深入了解HBase架构
9. 什么是列式存储数据库?
10. Spark整合Hbase遇到"java.lang.IllegalStateException: unread block data"错误














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









