









以下内容翻译自:CUTLASS 中的 Efficient GEMM in CUDA

Efficient GEMM in CUDA
CUTLASS 实现了 CUTLASS: Fast Linear Algebra in CUDA C++ 和 CUTLASS GTC2018 talk 中描述的分层分块结构。
Hierarchical Structure
基本的三重嵌套循环计算矩阵乘法可以应用分块和拼贴,以匹配硬件、内存局部性和并行编程模型中的并发性。CUTLASS 中 GEMM 映射到 NVIDIA GPU 的结构如以下嵌套循环所示。
for (int cta_n = 0; cta_n < GemmN; cta_n += CtaTileN) { // for each threadblock_y } threadblock-level concurrency
for (int cta_m = 0; cta_m < GemmM; cta_m += CtaTileM) { // for each threadblock_x }
for (int cta_k = 0; cta_k < GemmK; cta_k += CtaTileK) { // "GEMM mainloop" - no unrolling
// - one iteration of this loop is one "stage"
//
for (int warp_n = 0; warp_n < CtaTileN; warp_n += WarpTileN) { // for each warp_y } warp-level parallelism
for (int warp_m = 0; warp_m < CtaTileM; warp_m += WarpTileM) { // for each warp_x }
//
for (int warp_k = 0; warp_k < CtaTileK; warp_k += WarpTileK) { // fully unroll across CtaTileK
// - one iteration of this loop is one "k Group"
//
for (int mma_k = 0; mma_k < WarpTileK; mma_k += MmaK) { // for each mma instruction } instruction-level parallelism
for (int mma_n = 0; mma_n < WarpTileN; mma_n += MmaN) { // for each mma instruction }
for (int mma_m = 0; mma_m < WarpTileM; mma_m += MmaM) { // for each mma instruction }
//
mma_instruction(d, a, b, c); // TensorCore matrix computation
} // for mma_m
} // for mma_n
} // for mma_k
} // for warp_k
} // for warp_m
} // for warp_n
} // for cta_k
} // for cta_m
} // for cta_n
这种拼贴嵌套循环的目标是线程块、线程束以及 CUDA 和张量核心之间的并发性。
它利用共享内存和寄存器内的内存局部性。
下图说明了该结构中的数据流。这就是 CUTLASS 所体现的分层 GEMM 计算。每个阶段描述了一个嵌套层次的拼贴,它对应于 CUDA 执行模型内的一层并发性和内存层次结构内的一个层次,从左向右移动变得越来越精细。
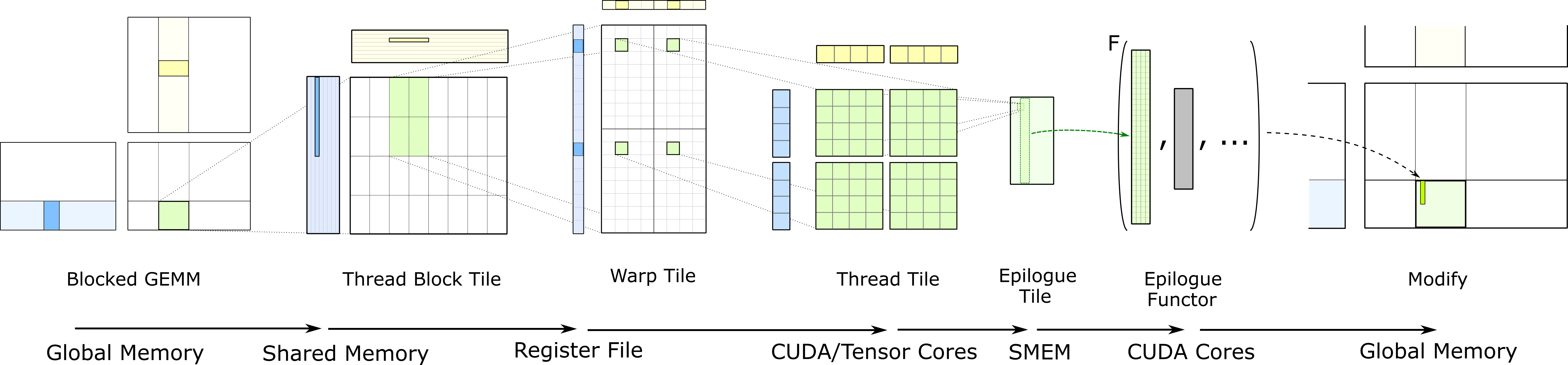
Threadblock-level GEMM
每个线程块通过迭代加载输入矩阵的图块并计算累积矩阵乘积来计算其输出 GEMM 的部分。在线程块级别,数据从全局内存加载。一般而言,分块策略是实现效率的关键。然而,程序员必须平衡多个相互冲突的目标:
- 更大的线程块意味着从全局内存中获取的数据更少,从而确保 DRAM 带宽不会成为瓶颈。
- 然而,大的线程块图块可能无法很好地匹配问题的维度:
- 如果 GEMM 的 M 或 N 维度较小,则线程块内的某些线程可能无法执行有意义的工作,因为线程块可能部分超出问题的范围。
- 如果 M 和 N 都较小而 K 较大,则该方案可能会启动相对较少的线程块,并且无法充分利用 GPU 内的所有多处理器。针对这种情况,优化性能的策略,如 Parallelized Reductions 部分所述,跨多个线程块或多个线程束对 GEMM 的 K 维度进行划分:
- 这些线程块或线程束并行地计算矩阵积;
- 然后对产品进行归约以计算结果。
在 CUTLASS 中,线程块图块的维度由ThreadblockShape::{kM, kN, kK}指定,并且可以进行调整以专门针对目标处理器和 GEMM 问题的维度进行 GEMM 计算。
Warp-level GEMM
线程束级 GEMM 映射到 CUDA 执行模型内的线程束级并行。线程块内的多个线程束将数据从共享内存提取到寄存器中并执行计算。Warp 级 GEMM 可以通过以下两种方法来实现:
为了获得最大性能,对共享内存的访问应该是无 bank 冲突的。为了最大限度地提高线程束内的数据重用,应选择大的线程束级 GEMM 切片。
Thread-level GEMM
在最低级别的分块中,每个线程负责处理一定数量的元素。线程无法访问彼此的寄存器,因此我们选择一种组织方式,能够重用寄存器中保存的值来执行多条数学指令。这会在线程内产生2D 图块结构,其中每个线程向 CUDA 核发出一系列独立的数学指令并计算累积的外积。
SGEMM、IGEMM、HGEMM 和 DGEMM 由线程级矩阵乘法程序发出的 SIMT 数学指令进行计算。
Epilogue
上述代码仅关注矩阵乘法运算 C = AB,其结果保存在线程块内每个线程的寄存器中。选择输出块中的逻辑元素到每个线程的映射以最大化矩阵乘法计算的性能,但不会导致高效、合并的加载和存储到全局内存。
收尾是一个单独的阶段,其中线程通过共享内存交换数据,然后使用高效的条带访问模式协同访问全局内存。这也是可以使用矩阵乘积结果作为输入来方便地计算线性缩放和其他元素运算的阶段。
CUTLASS 定义了几种典型的收尾操作,例如线性缩放和截断,但也可以使用其他设备端函数调用运算符来执行自定义操作。
Optimizations
上述分层结构可有效映射到 NVIDIA GPU 中的 CUDA 执行模型和 CUDA/TensorCore。以下各节描述了在设计空间的所有角落获得最佳性能、最大化并行性并尽可能利用数据局部性的策略。
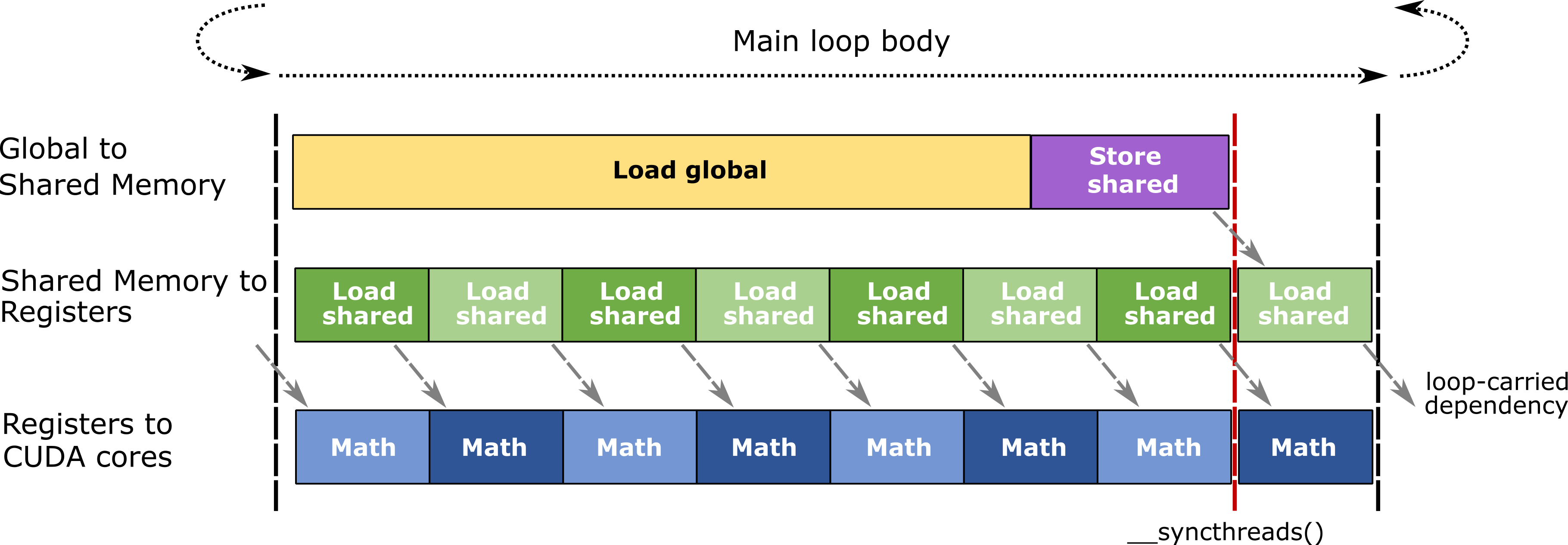
Pipelining
分块结构需要在每个 CUDA 线程的寄存器内分配大量存储空间。累加器元素通常占据线程的总寄存器预算的至少一半。因此,与其他类别的 GPU 工作负载相比,占用率(并发线程、线程束和线程块的数量)相对较低。这限制了 GPU 通过上下文切换到 SM 内其他并发线程来隐藏内存延迟和其他停顿的能力。
为了减轻内存延迟的影响,CUTLASS 使用软件流水线将内存访问与线程内的其他计算重叠。 CUTLASS 通过在以下范围内进行双缓冲来实现这一点。
-
线程块范围的共享内存块:在共享内存中分配两个块。一个用于加载当前矩阵运算的数据,而另一个图块用于缓冲从全局内存加载的数据以供下一个主循环迭代使用。
-
线程束范围的矩阵分片:寄存器内分配两个分片。在当前矩阵计算期间,将一个分片传递给 CUDA 和 TensorCore,而另一个分片用于接收共享内存取回来的数据,用于下一步的线程束级矩阵操作。
下图说明了 CUTLASS 的 GEMM 中使用的高效、流水线式主循环体。
Threadblock Rasterization
为了最大限度地重用最后一级缓存中的数据,CUTLASS 定义了几个函数来影响线程块到 GEMM 问题的逻辑分区的映射。这些函数将连续启动的线程块映射到分区 GEMM 问题的打包二维区域,以增加这些线程块在大约同一时间访问相同的全局内存块的概率。
在 cutlass/gemm/threadblock_swizzle.h 中定义了几个函数。
Parallelized Reductions
Split K - reduction across threadblocks
矩阵乘积计算揭示了_O(MN)_ 独立内积计算之间的并行性。对于足够大的问题规模,CUTLASS 中的 GEMM 内核可以逼近理论上的最大计算吞吐量。但对于较小的问题,线程块太少,无法有效地占用整个 GPU。
作为一种手段,并行化内积计算期间执行的归约可以让更多线程块同时执行,同时仍然能利用大型线程块级 GEMM 切片的吞吐量优势。
CUTLASS 通过对 GEMM 的 K 维度进行划分,并为每个分区启动一组额外的线程块来实现跨线程块的并行归约。因此,我们在 CUTLASS 中将这种策略称为“并行归约 splitK”。 “并行归约 splitK”策略需要执行 2 个内核:partitionedK GEMM 和批量归约。
PartitionedK GEMM 类似于批量跨步 GEMM 的一种风格。PartitionedK GEMM 不要求用户指定每个批次的问题规模,而是要求总体问题规模以及将沿操作数 A 和 B 的 K 维度应用的分区数量。 例如,参数 m=128,n =128、k=4096 和 partition=16 将产生16个批次的跨步 GEMM,每个批次 m=128、n=128、k=256。
PartitionedK 还允许 k 不能被分区数整除的情况。例如,参数 m=128、n=128、k=4096 和 partition=20 将产生 20 个批量跨步 GEMM。前19个批次将具有 m=128、n=128 和 k=4096/20=204,最后一个批次将具有 m=128、n=128 和 k=220。
批量归约内核将 partitionedK GEMM 的输出(C)作为输入,并沿 K 维进行归约。用户必须管理工作区内存来存储此中间结果。
Sliced K - reduction across warps
与 split-k 场景类似,sliced-k 旨在提高 M 和 N 维度较小但 K 维度较大时内核的效率。
在线程块级别,参数 CtaTileN 和 CtaTileM 通过在 warp 之间划分工作来公开并行性。较大的 warpTiles 具有更好的指令级并行性 (ILP) 和重用性,但也限制了每个线程块运行的 warp 数量,从而降低了效率。
为了提高此类场景中的效率,同样沿 ctaTileK 划分 warpTiles,通过允许更多线程束在 CTA 中同时运行来更有效地使用硬件。
Sliced-k 内核不仅在 CtaTileN、CtaTileM 维度之间,而且还在 CtaTileK 维度上分解线程块计算到参与的线程束。
因此,sliced-k 带来了一个小的归约形式的开销,这种归约必须出现在参与线程束的末尾。这是因为每个线程束仅使用 CtaTileK 的“切片”进行计算,因此每个线程束在归约之前仅具有部分和。
Warp Specialization
从 Hopper 开始,CUTLASS 3.0 将 Warp Specialization 的概念纳入内核设计的一部分。将线程块划分为两个线程束集合,producer warp group and consumer warp group:
- 生产者线程束组使用新的 Tensor Memory Accelerator (TMA) 将数据从全局内存加载到共享内存缓冲区中。
- 一旦数据写入共享内存,TMA 也会更新与该阶段关联的屏障,以通知受影响的线程已填充缓冲区。
- 另一方面,Consumer warp group (MMA) 等待生产者线程束组发出缓冲区已满的信号,然后启动张量核心 MMA 操作。
- 之后,消费者线程束组释放缓冲区以便发生下一组 TMA 加载。
- Producer warp group (DMA) 等待消费者线程束组使用新添加的 Async Pipeline 类(请参阅)发出共享内存缓冲区为空的信号。
Warp-Specialized Persistent Cooperative kernel design
从 Hopper 开始引入的另一种 Warp 专用内核设计是 Warp-Specialized Persistent Cooperative 内核。与 Warp-Specialized 内核一样,线程束组和线程束组之间的屏障同步的概念在协作设计中保持不变。Warp-Specialized Persistent Cooperative 内核的显著特征如下:
- 启动持久线程块以占用 KernelHardwareInfo 结构中所提数量的 SM。这些持久线程块用于拼块输出,从而(可能)在其生命周期内计算多个输出块。 这增加的主要好处是分摊了所有内核中典型的线程块启动和内核序幕开销。
- 通过在 M 维度上将图块一分为二,在同一输出块上存在两个协同工作的消费者线程束组。存在两个消费者线程束组通过在 M 维度上将图块分成两半来在同一输出图块上进行合作。这允许启用更大的图块尺寸——因为每个消费者线程束组的寄存器压力降低了——从而提高性能。
由于每个线程块现在计算多个输出块,因此网格启动的形状以及线程块的图块调度使用新的 Tile Scheduler 进行管理。Tile Scheduler 考虑集群的形状以及可用 SM 的数量,以计算输出图块到已启动线程块的有效调度。
Warp-Specialized Persistent Ping-Pong kernel design
第三种内核设计是 Warp-Specialized Persistent Ping-Pong 内核。
与 Warp Specialized Persistent Cooperative 一样,线程束组的核心概念、线程束组之间的屏障同步以及网格发射的形状在持久乒乓设计中保持不变。 Warp-Specialized Persistent Ping-Pong 内核的显著特征如下:
- 使用 Tile Scheduler 为两个消费者线程束组分配不同的输出图块。这允许一个消费者线程束组的收尾与另一消费者线程束组的数学运算重叠——从而最大化张量核心利用率。
- 生产者线程束组使用 Ordered Sequence Barrier 进行同步,以按顺序依次填充两个消费者线程束组的缓冲区。
Resources
以下附加资源描述了针对 NVIDIA GPU 的 GEMM 的设计和实现细节。
- Developing CUDA Kernels to Push Tensor Cores to the Absolute Limit on NVIDIA A100. (SR 21745)
- CUTLASS: Fast Linear Algebra in CUDA C++
- CUTLASS: SOFTWARE PRIMITIVES FOR DENSE LINEAR ALGEBRA AT ALL LEVELS AND SCALES WITHIN CUDA
- Programming Tensor Cores: NATIVE VOLTA TENSOR CORES WITH CUTLASS
- CUDA Programming Guide: warp matrix functions
- Matrix Multiply Accumulate Instructions
Copyright
Copyright © 2017 - 2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
SPDX-License-Identifier: BSD-3-Clause
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.















 763
763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









