







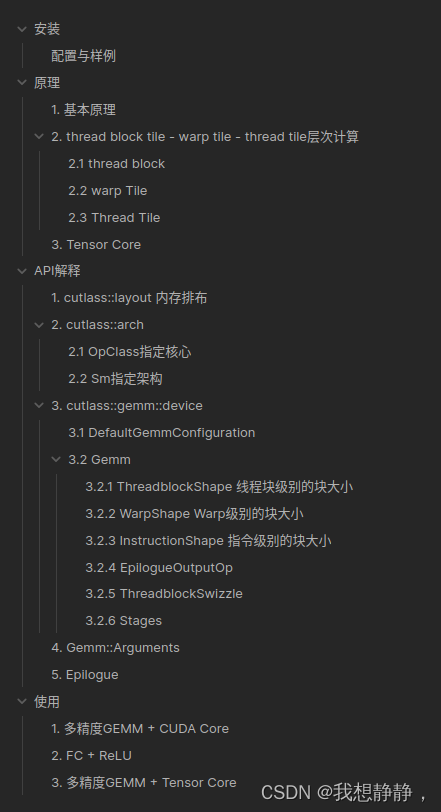
 本文介绍了如何在Ampere架构的GPU上使用Cutlass库实现GEMM(矩阵乘法),包括对TensorCore和CudaCore的支持,提供模板代码示例,以及Cutlass的安装步骤和原理解析。
本文介绍了如何在Ampere架构的GPU上使用Cutlass库实现GEMM(矩阵乘法),包括对TensorCore和CudaCore的支持,提供模板代码示例,以及Cutlass的安装步骤和原理解析。
欢迎关注微信公众号InfiniReach,这里有更多AI大模型的前沿算法与工程优化方法分享
 下面实现了两份支持tensorcore 与cudacore 的代码,具体cutlass的安装,api的解读,gemm的原理部分,可以看https://mp.weixin.qq.com/s/FXuFljYMc-8Zb8pHf–GPA
下面实现了两份支持tensorcore 与cudacore 的代码,具体cutlass的安装,api的解读,gemm的原理部分,可以看https://mp.weixin.qq.com/s/FXuFljYMc-8Zb8pHf–GPA
cutlass gemm + cuda core
使用cutlass实现一个ampere架构下的GEMM,通过模版支持多种精度,多种layout等配置,支持cuda core
/**
* @file m2.cu
* @author your name (you@domain.com)
* @brief
* @version 0.1
* @date 2024-03-27
*
* @copyright Copyright (c) 2024
* 多精度GEMM
*/
#include <cstdio>
#include <omp.h>
#include <Eigen/Core>
#include <cuda_runtime_api.h>
#include "cutlass/cutlass.h"
#include "cutlass/gemm/device/gemm.h"
/// Define a CUTLASS GEMM template and launch a GEMM kernel.
template<
typename ElementInputA=float,
typename ElementInputB=float,
typename ElementOutput=float,
typename ElementAccumulator=float,
typename Major=cutlass::layout::ColumnMajor,
typename OperatorClass=cutlass::arch::OpClassSimt,
typename ArchTag=cutlass::arch::Sm80>
cudaError_t CutlassGemmCUDA(
int M,
int N,
int K,
float alpha,
ElementInputA const *A,
int lda,
ElementInputB const *B,
int ldb,
float beta,
ElementOutput *C,
int ldc) {
using CutlassGemm = cutlass::gemm::device::Gemm<ElementInputA, Major,
ElementInputB, Major,
ElementOutput, Major,
ElementAccumulator,
OperatorClass,
ArchTag>;
CutlassGemm gemm_operator;
typename CutlassGemm::Arguments args({M, N, K}, // Gemm Problem dimensions
{A, lda}, // Tensor-ref for source matrix A
{B, ldb}, // Tensor-ref for source matrix B
{C, ldc}, // Tensor-ref for source matrix C
{C, ldc}, // Tensor-ref for destination matrix D (may be different memory than source C matrix)
{alpha, beta}); // Scalars used in the Epilogue
//
// Launch the CUTLASS GEMM kernel.
//
cutlass::Status status = gemm_operator(args);
if (status != cutlass::Status::kSuccess) {
return cudaErrorUnknown;
}
return cudaSuccess;
}
template<typename T1=float, typename T2=float>
void AllocateDevMatrix(T1 **matrix, const int rows, const int columns, const T2 *host_ptr=nullptr) {
cudaError_t result;
size_t sizeof_matrix = sizeof(T1) * rows * columns;
// Allocate device memory.
result = cudaMalloc(reinterpret_cast<void **>(matrix), sizeof_matrix);
if (result != cudaSuccess) {
std::cerr << "Failed to allocate matrix: "
<< cudaGetErrorString(result) << std::endl;
}
cudaMemset(*matrix, 0, sizeof_matrix);
if(host_ptr != nullptr)
cudaMemcpy(*matrix, host_ptr, sizeof_matrix, cudaMemcpyHostToDevice);
}
template<typename T=float, int Major=Eigen::RowMajor, bool init = true>
Eigen::Matrix<T, Eigen::Dynamic, Eigen::Dynamic, Major>
InitData(const int rows, const int columns){
Eigen::Matrix<T, Eigen::Dynamic, Eigen::Dynamic, Major> x;
x.resize(rows, columns);
if constexpr (init) {
x.setRandom();
}
return x;
}
template<typename T>
struct wrapper_{using type = T;};
template<>
struct wrapper_<float>{using type = float;};
template<>
struct wrapper_<double>{using type = double;};
template<>
struct wrapper_<cutlass::bfloat16_t>{using type = Eigen::bfloat16;};
template<>
struct wrapper_<cutlass::half_t>{using type = Eigen::half;};
template<typename T>
using wrapper = typename wrapper_<T>::type;
int main(int argc, char *argv[]) {
const int M = 128;
const int K = 512;
const int N = 1024;
omp_set_num_threads(omp_get_num_procs());
using OperatorClass = cutlass::arch::OpClassSimt;
using ArchTag = cutlass::arch::Sm80;
using ElementInputA = float;
using ElementInputB = float;
using ElementOutput = float;
using ElementAccumulator = float;
using Major = cutlass::layout::RowMajor;
ElementInputA *DevPtrA;
ElementInputB *DevPtrB;
ElementOutput *DevPtrC;
auto HostA = InitData<wrapper<ElementInputA>, Eigen::RowMajor, true>(M, K);
auto HostB = InitData<wrapper<ElementInputB>, Eigen::RowMajor, true>(K, N);
auto HostC = InitData<wrapper<ElementOutput>, Eigen::RowMajor, true>(M, N);
auto HostD = InitData<wrapper<ElementOutput>, Eigen::RowMajor, false>(M, N);
auto HostCutlassD = InitData<wrapper<ElementOutput>, Eigen::RowMajor, false>(M, N);
HostD = HostA * HostB + HostC;
AllocateDevMatrix<ElementInputA, wrapper<ElementInputA>>(&DevPtrA, M, K, HostA.data());
AllocateDevMatrix<ElementInputB, wrapper<ElementInputB>>(&DevPtrB, K, N, HostB.data());
AllocateDevMatrix<ElementOutput, wrapper<ElementOutput>>(&DevPtrC, M, N, HostC.data());
CutlassGemmCUDA<ElementInputA,
ElementInputB,
ElementOutput,
ElementAccumulator,
Major,
OperatorClass,
ArchTag>
(M, N, K,
1.,
DevPtrA, K,
DevPtrB, N,
1.,
DevPtrC, N
);
cudaDeviceSynchronize();
cudaMemcpy(HostCutlassD.data(), DevPtrC, HostCutlassD.size() * sizeof(ElementOutput),
cudaMemcpyDeviceToHost);
printf("Max error: %f\n", (float)((HostCutlassD - HostD).cwiseAbs().maxCoeff()));
cudaFree(DevPtrA);
cudaFree(DevPtrB);
cudaFree(DevPtrC);
return 0;
}
cmakelists.txt如下:
cmake_minimum_required(VERSION 3.22)
project(cutlassStudy CXX CUDA)
set(CMAKE_CUDA_STANDARD 17)
find_package(CUDA)
include(FindCUDA/select_compute_arch)
CUDA_DETECT_INSTALLED_GPUS(INSTALLED_GPU_CCS_1)
string(STRIP "${INSTALLED_GPU_CCS_1}" INSTALLED_GPU_CCS_2)
string(REPLACE " " ";" INSTALLED_GPU_CCS_3 "${INSTALLED_GPU_CCS_2}")
string(REPLACE "." "" CUDA_ARCH_LIST "${INSTALLED_GPU_CCS_3}")
message("-- nvcc generates code for arch ${CUDA_ARCH_LIST}")
SET(CMAKE_CUDA_ARCHITECTURES ${CUDA_ARCH_LIST})
find_package(Eigen3 REQUIRED)
find_package(OpenMP REQUIRED)
add_compile_options(-lineinfo)
add_executable(test test.cu)
target_link_libraries(test OpenMP::OpenMP_CXX)
cutlass gemm + tensor core
使用cutlass实现一个ampere架构下的GEMM,通过模版支持多种精度,多种layout等配置,支持tensor core
/**
* @file test.cu
* @author InfiniReach
* @brief
* @version 0.1
* @date 2024-03-27
*
* @copyright Copyright (c) 2024
*/
#include <cstdio>
#include <omp.h>
#include <Eigen/Core>
#include <cuda_runtime_api.h>
#include "cutlass/cutlass.h"
#include "cutlass/gemm/device/gemm.h"
#include "cutlass/util/command_line.h"
#include "cutlass/util/host_tensor.h"
#include "cutlass/util/reference/device/gemm.h"
#include "cutlass/util/reference/host/tensor_compare.h"
#include "cutlass/util/reference/host/tensor_copy.h"
#include "cutlass/util/reference/host/tensor_fill.h"
#include "cutlass/util/tensor_view_io.h"
#include "helper.h"
/// Define a CUTLASS GEMM template and launch a GEMM kernel.
template<
typename ElementInputA=float,
typename ElementInputB=float,
typename ElementOutput=float,
typename ElementAccumulator=float,
typename MajorA=cutlass::layout::RowMajor,
typename MajorB=cutlass::layout::ColumnMajor,
typename MajorC=cutlass::layout::RowMajor,
typename OperatorClass=cutlass::arch::OpClassSimt,
typename ArchTag=cutlass::arch::Sm80,
typename ShapeMMAThreadBlock=cutlass::gemm::GemmShape<128, 128, 16>,
typename ShapeMMAWarp=cutlass::gemm::GemmShape<64, 64, 16>,
typename ShapeMMAOp=cutlass::gemm::GemmShape<16, 8, 8>,
int NumStages=2>
cudaError_t CutlassGemmTensorOp(
int M,
int N,
int K,
float alpha,
ElementInputA const *A,
int lda,
ElementInputB const *B,
int ldb,
float beta,
ElementOutput *C,
int ldc) {
using ElementComputeEpilogue = ElementAccumulator;
// This code section describes how threadblocks are scheduled on GPU
using SwizzleThreadBlock = cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle<>; // <- ??
// This code section describes the epilogue part of the kernel
using EpilogueOp = cutlass::epilogue::thread::LinearCombination<
ElementOutput, // <- data type of output matrix
128 / cutlass::sizeof_bits<ElementOutput>::value, // <- the number of elements per vectorized
// memory access. For a byte, it's 16
// elements. This becomes the vector width of
// math instructions in the epilogue too
ElementAccumulator, // <- data type of accumulator
ElementComputeEpilogue>; // <- data type for alpha/beta in linear combination function
using Gemm = cutlass::gemm::device::Gemm<ElementInputA, MajorA,
ElementInputB, MajorB,
ElementOutput, MajorC,
ElementAccumulator,
OperatorClass,
ArchTag,
ShapeMMAThreadBlock,
ShapeMMAWarp,
ShapeMMAOp,
EpilogueOp,
SwizzleThreadBlock,
NumStages>;
cutlass::gemm::GemmCoord problem_size{M, N, K};
// Split K dimension into 1 partitions
int split_k_slices = 1;
// Create a tuple of gemm kernel arguments. This is later passed as arguments to launch
// instantiated CUTLASS kernel
typename Gemm::Arguments arguments{problem_size, // <- problem size of matrix multiplication
cutlass::TensorRef<ElementInputA const, MajorA>(A, lda), // <- reference to matrix A on device
cutlass::TensorRef<ElementInputB const, MajorB>(B, ldb), // <- reference to matrix B on device
cutlass::TensorRef<ElementOutput const, MajorC>(C, ldc), // <- reference to matrix C on device
cutlass::TensorRef<ElementOutput, MajorC>(C, ldc), // <- reference to matrix D on device
{alpha, beta}, // <- tuple of alpha and beta
split_k_slices}; // <- k-dimension split factor
// Using the arguments, query for extra workspace required for matrix multiplication computation
size_t workspace_size = Gemm::get_workspace_size(arguments);
// Allocate workspace memory
cutlass::device_memory::allocation<uint8_t> workspace(workspace_size);
// Instantiate CUTLASS kernel depending on templates
Gemm gemm_op;
// Check the problem size is supported or not
cutlass::Status status = gemm_op.can_implement(arguments);
CUTLASS_CHECK(status);
// Initialize CUTLASS kernel with arguments and workspace pointer
status = gemm_op.initialize(arguments, workspace.get());
CUTLASS_CHECK(status);
status = gemm_op();
CUTLASS_CHECK(status);
}
template<typename T1=float, typename T2=float>
void AllocateDevMatrix(T1 **matrix, const int rows, const int columns, const T2 *host_ptr=nullptr) {
cudaError_t result;
size_t sizeof_matrix = sizeof(T1) * rows * columns;
// Allocate device memory.
result = cudaMalloc(reinterpret_cast<void **>(matrix), sizeof_matrix);
if (result != cudaSuccess) {
std::cerr << "Failed to allocate matrix: "
<< cudaGetErrorString(result) << std::endl;
}
cudaMemset(*matrix, 0, sizeof_matrix);
if(host_ptr != nullptr)
cudaMemcpy(*matrix, host_ptr, sizeof_matrix, cudaMemcpyHostToDevice);
}
template<typename T=float, int Major=Eigen::RowMajor, bool init = true>
Eigen::Matrix<T, Eigen::Dynamic, Eigen::Dynamic, Major>
InitData(const int rows, const int columns){
Eigen::Matrix<T, Eigen::Dynamic, Eigen::Dynamic, Major> x;
x.resize(rows, columns);
if constexpr (init) {
x.setRandom();
}
return x;
}
template<typename T>
struct wrapper_{using type = T;};
template<>
struct wrapper_<float>{using type = float;};
template<>
struct wrapper_<double>{using type = double;};
template<>
struct wrapper_<cutlass::bfloat16_t>{using type = Eigen::bfloat16;};
template<>
struct wrapper_<cutlass::half_t>{using type = Eigen::half;};
template<typename T>
using wrapper = typename wrapper_<T>::type;
template<typename T>
struct major_{static constexpr int type = -1;};
template<>
struct major_<cutlass::layout::RowMajor>{static constexpr int type = static_cast<int>(Eigen::RowMajor);};
template<>
struct major_<cutlass::layout::ColumnMajor>{static constexpr int type = static_cast<int>(Eigen::ColMajor);};
template<typename T>
static constexpr int major = major_<T>::type;
int main(int argc, char *argv[]) {
const int M = 128;
const int K = 512;
const int N = 1024;
omp_set_num_threads(omp_get_num_procs());
using OperatorClass = cutlass::arch::OpClassTensorOp;
using ArchTag = cutlass::arch::Sm80;
using ElementInputA = float;
using ElementInputB = float;
using ElementOutput = float;
using ElementAccumulator = float;
using MajorA = cutlass::layout::ColumnMajor;
using MajorB = cutlass::layout::RowMajor;
using MajorC = cutlass::layout::ColumnMajor;
using ShapeMMAThreadBlock=cutlass::gemm::GemmShape<128, 128, 16>;
using ShapeMMAWarp=cutlass::gemm::GemmShape<64, 64, 16>;
using ShapeMMAOp=cutlass::gemm::GemmShape<16, 8, 8>;
constexpr int NumStages=4;
auto HostA = InitData<wrapper<ElementInputA>, major<MajorA>, true>(M, K);
auto HostB = InitData<wrapper<ElementInputB>, major<MajorB>, true>(K, N);
auto HostC = InitData<wrapper<ElementOutput>, major<MajorC>, true>(M, N);
auto HostD = InitData<wrapper<ElementOutput>, major<MajorC>, false>(M, N);
auto HostCutlassD = InitData<wrapper<ElementOutput>, major<MajorC>, false>(M, N);
HostD = HostA * HostB + HostC;
ElementInputA *DevPtrA;
ElementInputB *DevPtrB;
ElementOutput *DevPtrC;
int lda = HostA.outerStride();
int ldb = HostB.outerStride();
int ldc = HostC.outerStride();
AllocateDevMatrix<ElementInputA, wrapper<ElementInputA>>(&DevPtrA, M, K, HostA.data());
AllocateDevMatrix<ElementInputB, wrapper<ElementInputB>>(&DevPtrB, K, N, HostB.data());
AllocateDevMatrix<ElementOutput, wrapper<ElementOutput>>(&DevPtrC, M, N, HostC.data());
CutlassGemmTensorOp<ElementInputA,
ElementInputB,
ElementOutput,
ElementAccumulator,
MajorA,
MajorB,
MajorC,
OperatorClass,
ArchTag,
ShapeMMAThreadBlock,
ShapeMMAWarp,
ShapeMMAOp,
NumStages>
(M, N, K,
1.,
DevPtrA, lda,
DevPtrB, ldb,
1.,
DevPtrC, ldc
);
cudaDeviceSynchronize();
cudaMemcpy(HostCutlassD.data(), DevPtrC, HostCutlassD.size() * sizeof(ElementOutput),
cudaMemcpyDeviceToHost);
printf("Max error: %f\n", (float)((HostCutlassD - HostD).cwiseAbs().maxCoeff()));
cudaFree(DevPtrA);
cudaFree(DevPtrB);
cudaFree(DevPtrC);
return 0;
}















 5724
5724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









