








以下内容翻译自:Automatic Kernel Optimization for Deep Learning on All Hardware Platforms
对于 AI 开发人员来说,在各种硬件平台上优化深度神经网络的性能仍然是一个难题。在系统支持方面,我们面临着一个多对多的问题:将多个前端(例如 Tensorflow、ONNX、MXNet)的训练模型部署到多个硬件平台(例如 CPU、GPU、加速器)。此问题中性能最关键的部分是为不断增加的模型结构和硬件平台获取高性能内核实现。
为了应对这一挑战,TVM 采用了全栈编译器方法。TVM 整合了代码生成和自动程序优化,能够生成与手工优化库性能相当的内核,在包括 ARM CPU、Intel CPU、Mali GPU、NVIIDA GPU 和 AMD GPU 在内的硬件平台上获得了最先进的推理性能。
在这篇博文中,我们展示了 TVM 编译器堆栈中自动内核优化的工作流程以及在若干硬件平台上的基准测试结果。

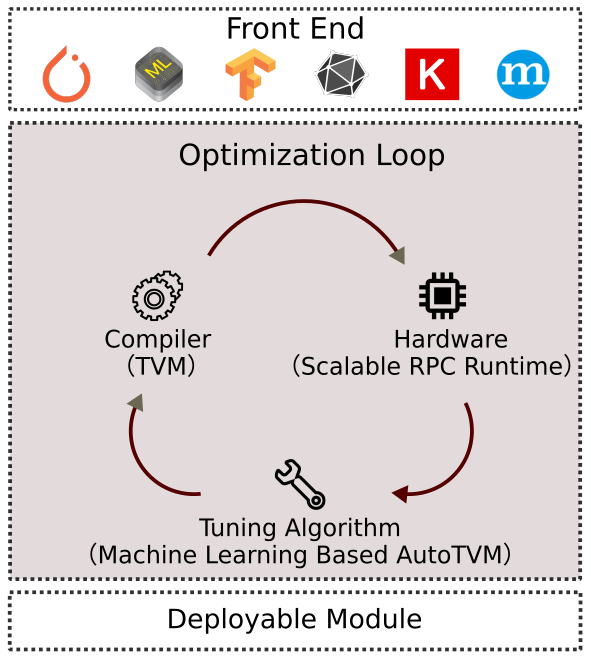
图1. 系统总览
TVM 中的内核优化以迭代循环方式完成。如图1所示,自动内核优化采用来自前端框架的神经网络(通常以计算图表示)作为输入,并为该网络中的所有操作符生成内核。
内部循环使用可伸缩的 RPC 运行时,基于机器学习的调优器和张量编译器。在循环的每一轮中,调优器从巨大的搜索空间中挑选一批有潜力的候选内核实现,并在真实硬件上对它们进行分析。然后调优器获得分析结果。这些分析结果用作训练数据以适应预测模型。在拟合预测模型之后,调优器根据预测选择下一个有潜力的候选者,循环继续执行。这样,我们迭代地搜索快速内核。
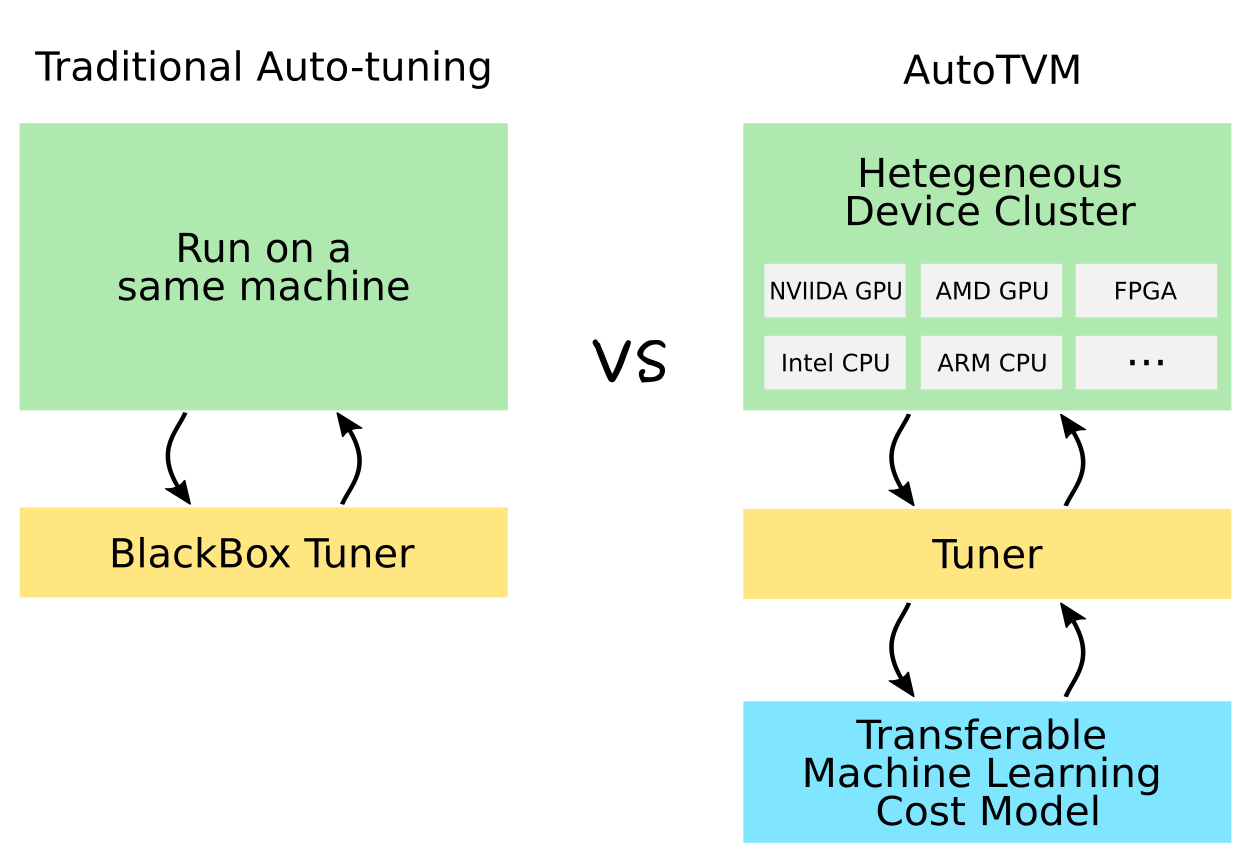
下图比较了传统的自动调优和 AutoTVM。主要区别在于 AutoTVM:
- 可扩展到异构设备集群
- 学习使用可转移的机器学习成本模型优化张量程序
您可以参考我们的论文来了解更多详情。

图2.传统自动调优和 AutoTVM 的比较
开始调优
为了演示,我们在 ARM 开发板 RK3399 上运行 resnet-18的优化。由于博文的篇幅限制,省略了详细说明。本博客最后提供了ARM CPU、Mali GPU、NVIDIA GPU 和 AMD GPU 教程的链接。
首先,我们从 MXNet 模型园地获得预先训练的模型,并从中提取调优任务。
from mxnet.gluon.model_zoo.vision import get_model
block = get_model('resnet18_v1', pretrained=True)
net, params = nnvm.frontend.from_mxnet(block)
tasks = autotvm.extract_from_graph(net)
tune_tasks(tasks, **tuning_option)
resnet-18中有12个不同的 conv2d 层,因此我们启动了12个调优任务。对于其中每一个来说,调优器进行了数百次试验,并选择了最好的一个。完成所有调优任务后,我们编译整个网络并生成一个可部署的最小库。一个事例输出为:
Extract tasks...
Tuning...
[Task 1/12] Current/Best: 22.37/ 52.19 GFLOPS | Progress: (544/1000) | 406.59 s Done.
[Task 2/12] Current/Best: 6.51/ 18.77 GFLOPS | Progress: (608/1000) | 325.05 s Done.
[Task 3/12] Current/Best: 4.67/ 24.87 GFLOPS | Progress: (480/1000) | 372.31 s Done.
[Task 4/12] Current/Best: 11.35/ 46.83 GFLOPS | Progress: (736/1000) | 602.39 s Done.
[Task 5/12] Current/Best: 1.01/ 19.80 GFLOPS | Progress: (448/1000) | 262.16 s Done.
[Task 6/12] Current/Best: 2.47/ 23.76 GFLOPS | Progress: (672/1000) | 563.85 s Done.
[Task 7/12] Current/Best: 14.57/ 33.97 GFLOPS | Progress: (544/1000) | 465.15 s Done.
[Task 8/12] Current/Best: 1.13/ 17.65 GFLOPS | Progress: (576/1000) | 365.08 s Done.
[Task 9/12] Current/Best: 14.45/ 22.66 GFLOPS | Progress: (928/1000) | 724.25 s Done.
[Task 10/12] Current/Best: 3.22/ 15.36 GFLOPS | Progress: (864/1000) | 564.27 s Done.
[Task 11/12] Current/Best: 11.03/ 32.23 GFLOPS | Progress: (736/1000) | 635.15 s Done.
[Task 12/12] Current/Best: 8.00/ 21.65 GFLOPS | Progress: (1000/1000) | 1111.81 s Done.
Compile...
Upload...
Evaluate inference time cost...
Mean inference time (std dev): 162.59 ms (0.06 ms)
如果您的模型有一些奇怪的形状或您的硬件是自定义的,调优特别有用,并且值得一试,因为手动优化的静态库无法考虑所有情况。
基准测试结果
我们在设备集群上预先调整了一些流行的网络,并发布了以下基准测试。复现说明在本博客的最后。
由于 TVM 拥有统一的运行时接口,全面基准测试很容易。但是,如果没有许多其他项目开发人员的专业协助,维护与所有其他平台的完整、最新和正确的比较是不可行的。因此,我们将所有数字放在一个表中,然后提供与其他一些库的不完整比较。
对比
我们通过与每个平台上经过大量优化的传统库进行比较来验证自动优化堆栈的有效性。
我们在 ImageNet(3x224x224)数据集上测试了流行的图像分类网络,批量大小为1,数据类型为 float32。报告的数字是每张图像耗时,以毫秒为单位。
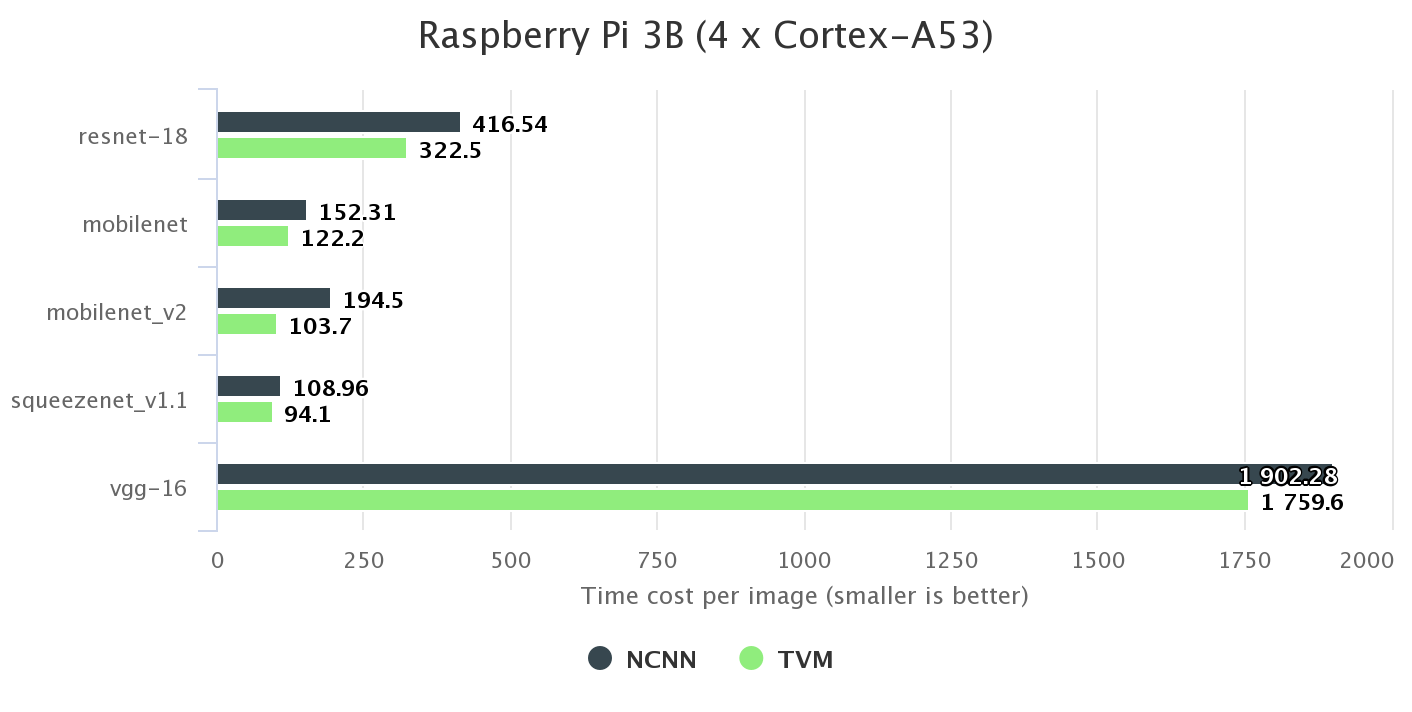
ARM CPU
我们选择 NCNN,一种广泛使用的手动优化内核库作为基线。它广泛使用 NEON 汇编指令。例如,代码库仅包含13k 行代码,仅用于3x3卷积层。我们在他们的项目库中引用基准数字。如下图所示,在 Rasbperry Pi 3B 上运行时,TVM 在所有网络上都优于它。

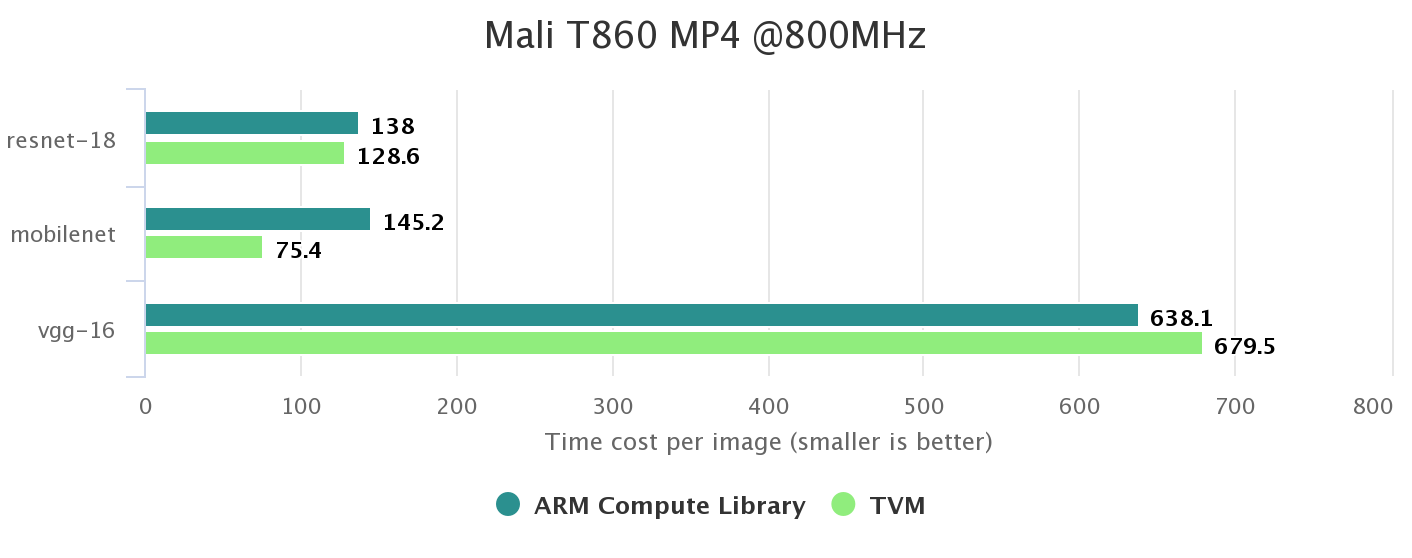
Mali GPU
ARM Compute Library 是供应商提供的库,可以很好地支持 Mali GPU(OpenCL)。根据结果,由于卷积层的优势,TVM 在 ResNet 和 MobileNet 中提供了更强的性能。TVM 在 vgg-16上落后了一点,因为 vgg-16是一个古老而庞大的网络,并且有几个大的密集层。

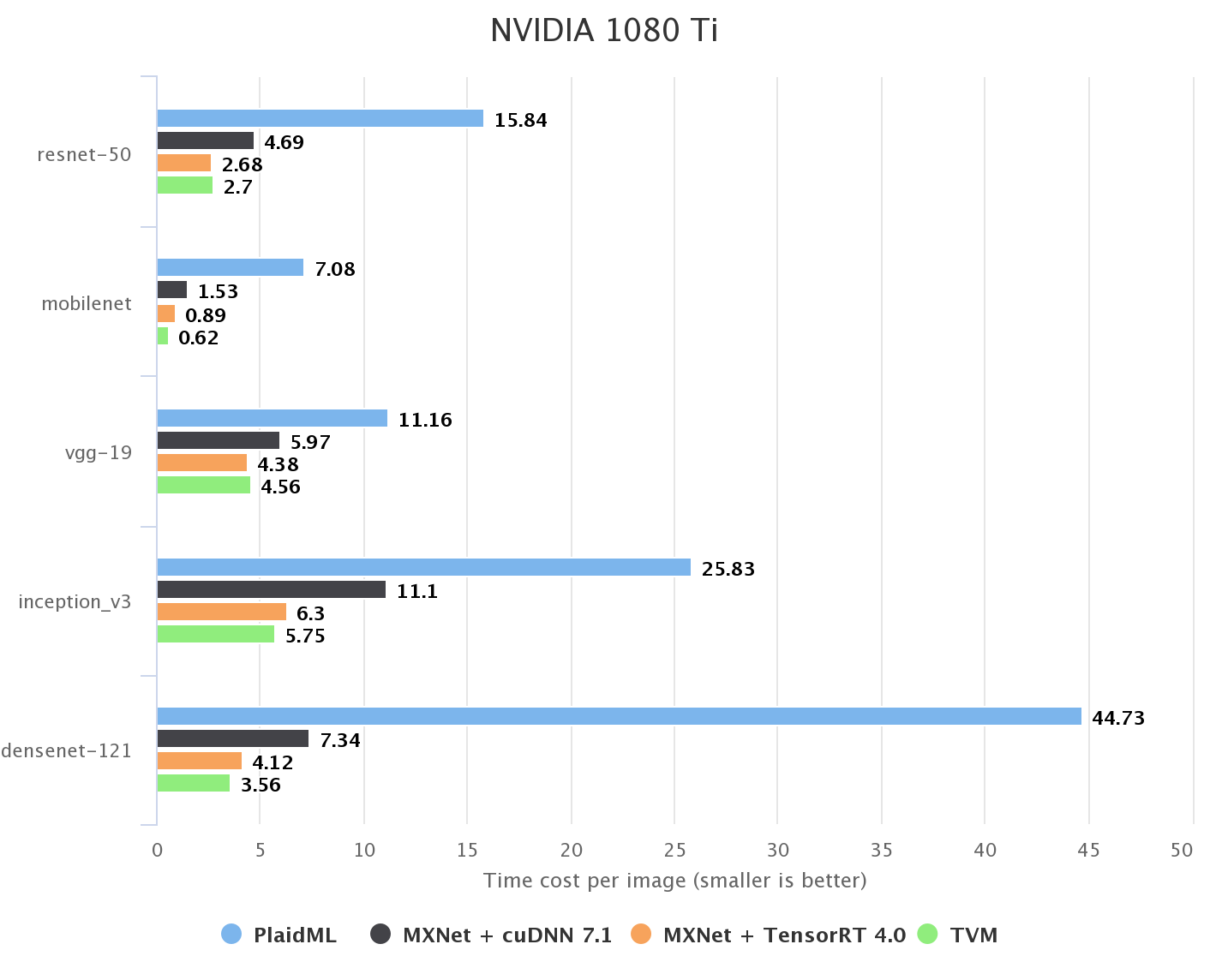
NVIDIA GPU
在 NVIDIA GPU 上,CuDNN 和 TensorRT 分别是供应商提供的两个用于训练和推理的库。由于我们专注于推理,因此我们在非批量设置中运行我们的基准测试。另一个张量编译器 PlaidML 与 AutoTVM 版本之前的 TVM 进行了比较,因此也将其作为基线。我们参考 PlaidBench 的基准测试结果。根据以下结果,TVM 实现了与 TensorRT 匹敌的性能。

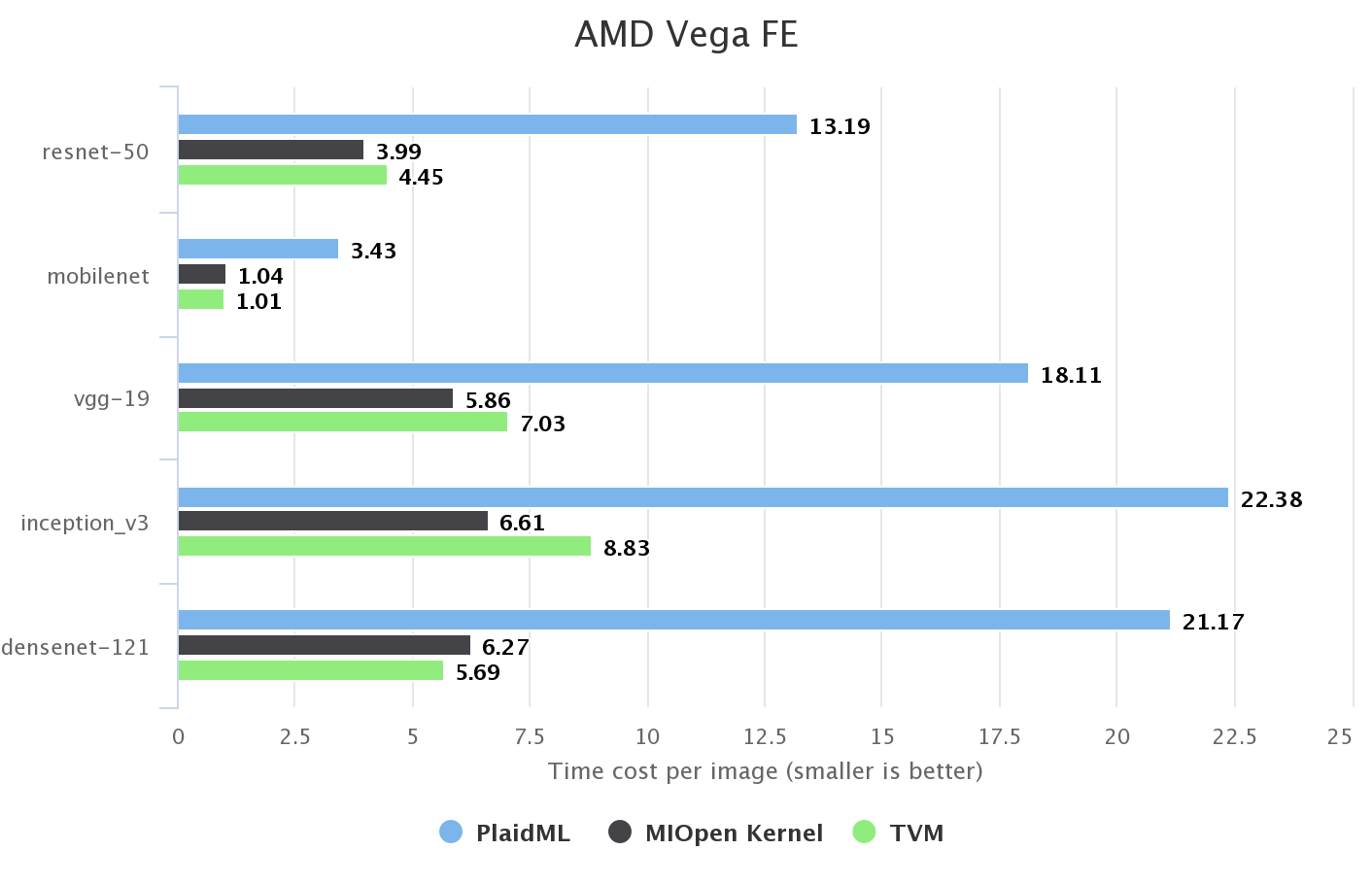
AMD GPU
我们还快速了解了一下 AMD GPU。TVM 支持 OpenCL 和 ROCm 后端。我们发现 ROCm 更好,因为它更专用于 AMD GPU。 MIOpen 是供应商提供的内核库。TVM 的图运行时可以直接调用 MIOpen 的内核实现,因此我们通过使用此集成来报告基线性能。
我们没有对 AMD GPU 进行任何特定的优化。直接重用了 NVIDIA GPU 的所有计算定义和调度代码。因此,在大多数情况下,TVM 比 MIOpen 慢一点。我们认为仍有改进的空间。

我们所有的结果
我们在 ImageNet(3x224x224)数据集上测试了流行的图像分类网络,批量大小为1,数据类型为 float32。报告的数字是每张图像耗时,以毫秒为单位。

Note 1:此板上的内存不足。
Note 2:由于时间限制,我们没有在 GPU 上调整一些小型网络。当分析数据不可用时,TVM 可以使用回退代码生成。但在这种情况下无法保证性能竞争力。
结论
通过富有表达力的代码生成器和高效的搜索算法,我们能够生成与手工优化的内核相当的内核。由于程序员时间昂贵且机器时间越来越便宜,我们认为循环中借助真实硬件和数据进行自动优化将成为推理部署的标准工作流程。TVM 只是提供了这样的解决方案。
链接
1 benchmark: https://github.com/dmlc/tvm/tree/master/apps/benchmark
2 Tutorial on tuning for ARM CPU: https://docs.tvm.ai/tutorials/autotvm/tune_nnvm_arm.html
3 Tutorial on tuning for Mobile GPU: https://docs.tvm.ai/tutorials/autotvm/tune_nnvm_mobile_gpu.html
4 Tutorial on tuning for NVIDIA/AMD GPU: https://docs.tvm.ai/tutorials/autotvm/tune_nnvm_cuda.html
5 Paper about AutoTVM: Learning to Optimize Tensor Program
6 Paper about Intel CPU (by AWS contributors) : Optimizing CNN Model Inference on CPUs

















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}