






首先要知道的东西
1.序列式容器
vector、list、deque、forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。
2.关联式容器
关联式容器也是用来存储数据的,与序列式容器不同的是,里面存储的是结构的键值对,在数据检索时比序列式容器效率更高。
3.键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。比如:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义。
4.树形结构的关联式容器
根据应用场景的不同,STL总共实现了两种不同结构的管理式容器:树型结构与哈希结构。树型结构的关联式容器主要有四种:map、set、multimap、multiset。这四种容器的共同点是:使用平衡搜索树(即红黑树)作为其底层结构,容器中的元素是一个有序的序列。下面一依次介绍每一个容器。
set的使用
1.insert
关联式容器没有提供push这样的接口了。
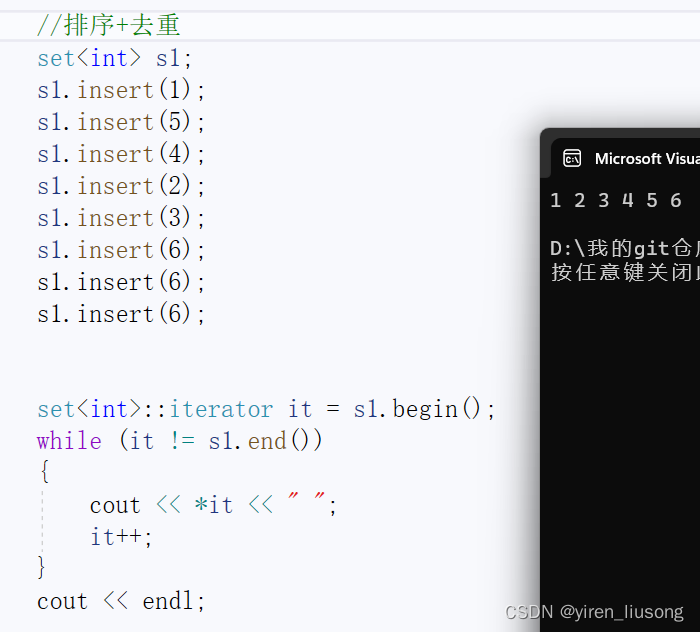
可以看到:插入后直接有序,并且进行了去重。
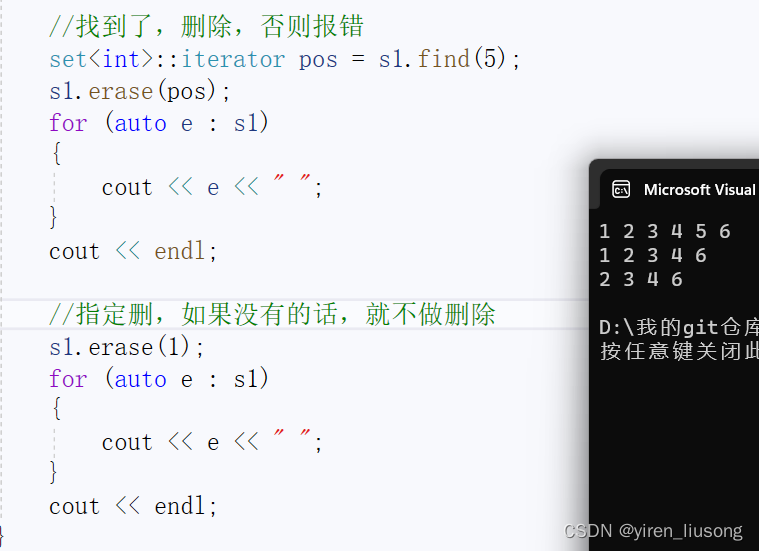
2.erase
3.lower_bound和upper_bound

提问:为何找这个区间不用find(3)和find(5)呢?
因为c++中要给接口的迭代器区间都是 [ ) 的,所以根据上图的特性,upper_bound就可以找到下一个位置。
4.multiset和count
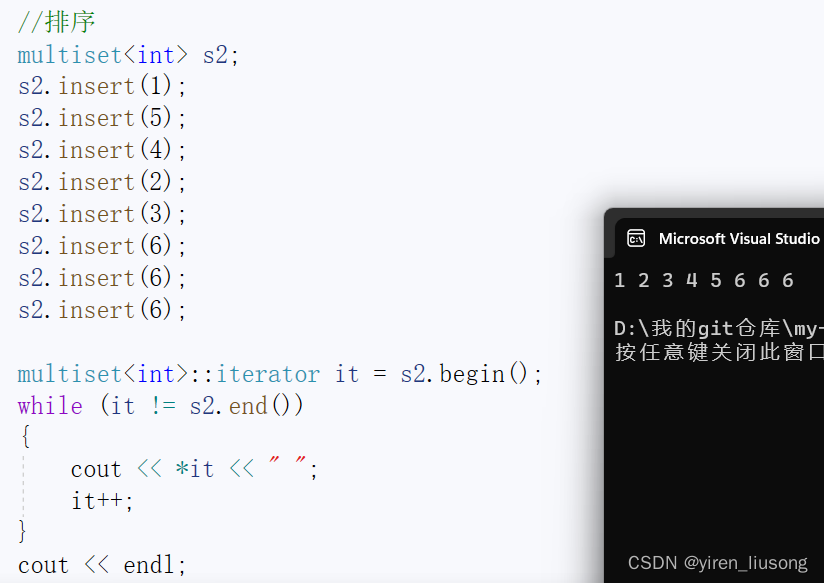
可以看到:multiset允许数据冗余

count就可以返回数据存在的个数。
map的使用
1.了解pair


pair是一个类模板,它里面的T1 T2存的就是一个键值对。
2.insert

解释:因为map insert的一种插入,参数类型为pair这个类模板,所以插入是得用pair类型的对象来插入
而make_pair是一个函数模板

返回一个pair对象,所以比较常用这个。
c++11里才会有{ }
注意:既然map是KV模型,那再次插入相同的K,不同/相同的V,都是不会插入也不会更新,系统会认为插入失败。
3.find

理解:存在,返回迭代器 不存在,返回end位置的迭代器。
应用:可以统计水果个数
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" }; map<string, int> count; for (auto& e : arr) { map<string, int>::iterator it = count.find(e); if (it != count.end()) { //在的话,次数++ it->second++; } else { //没在,就插入 count.insert(make_pair(e, 1)); } } for (auto& e : count) { cout << e.first << ':' << e.second << " "; } cout << endl;
4.[ ] 和insert返回值
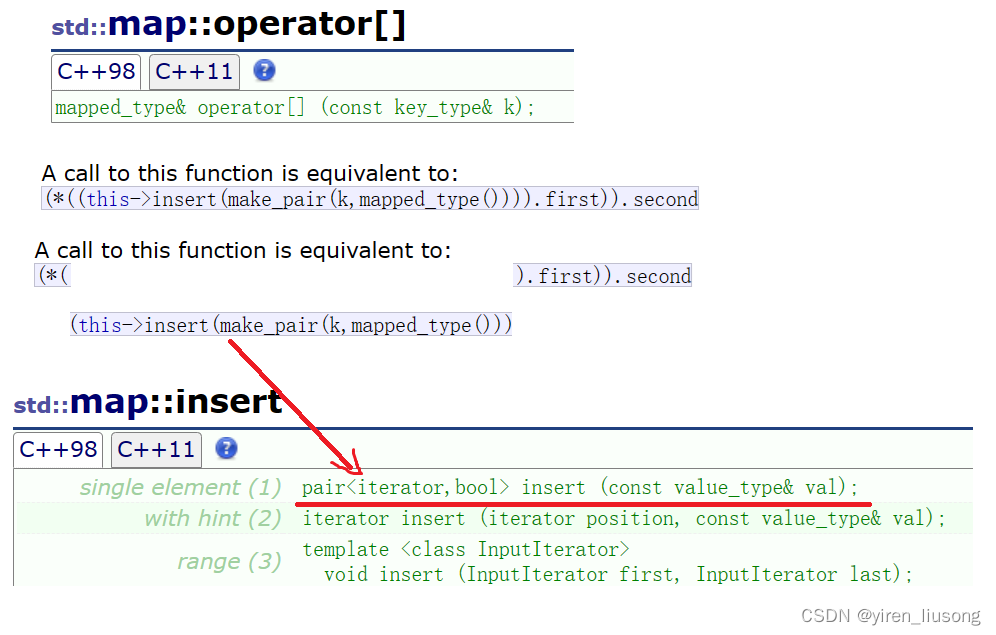

理解:insert第一个重载 返回值是pair类型,而[ ]利用了这个返回值的first(其实就是对应的参数列表的map对象的迭代器),用这个迭代器可以访问里面的俩参数,[ ]就是指向里面的第二个bool值参数。
解释Return value:first会指向一个新插入元素的迭代器或者值与它相等的元素的迭代器,second是,如果插入成功就返回true,如果失败(map里已经有相等的),就返回false
因此,可以把水果计数改为:
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" }; map<string, int> count; for (auto& e : arr) { pair<map<string, int>::iterator, bool> ret; ret = count.insert(make_pair(e, 1)); if (ret.second == false) { ret.first->second++; } } for (auto& e : count) { cout << e.first << ':' << e.second << " "; } cout << endl; }
注意:[ ]也是有参数和返回值的
那么就可以用[ ]做很多事情
只需记住括号里参数为K,括号的返回值是V
= 右边是 V

两道OJ题
1.两个数组的交集
可以用set的特性以及,成员函数count操作:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2)
{
//用set排序+去重
set<int> s1(nums1.begin(), nums1.end());
set<int> s2(nums2.begin(), nums2.end());
vector<int> ret;
auto it = s1.begin();
for (auto& e : s2)
{
if (s1.count(e))
{
ret.push_back(e);
}
}
return ret;
}也可以用一种算法来解决:

这种数据同步算法应用:
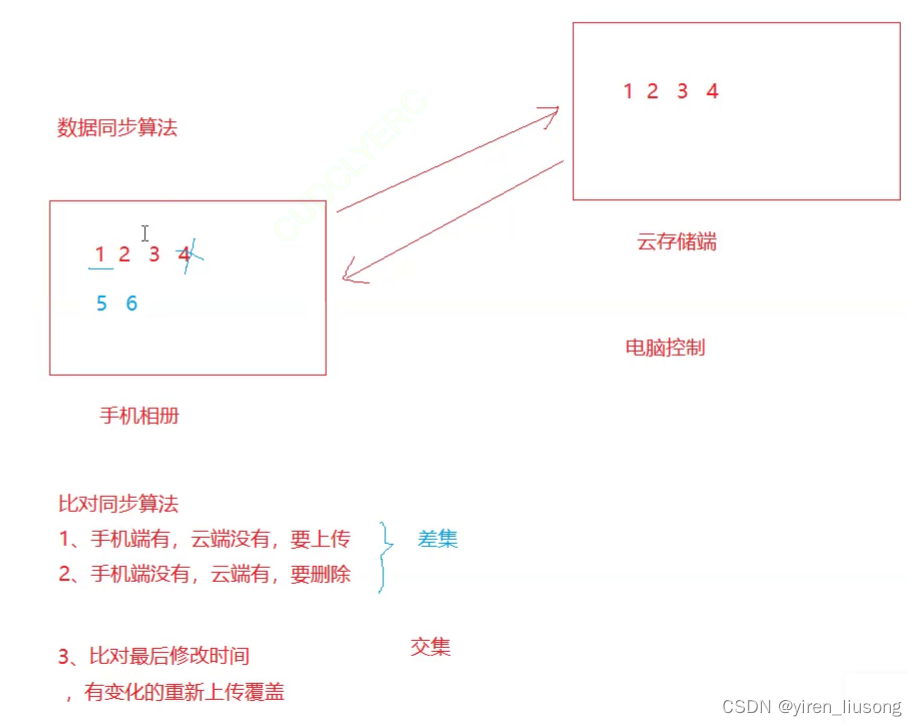
2.前k个高频单词
class Solution
{
public:
//仿函数
struct KVcomp
{
bool operator()(const pair<string, int>& p1, const pair<string, int>& p2)
{
return p1.second > p2.second || (p1.second == p2.second && p1.first < p2.first);
}
};
vector<string> topKFrequent(vector<string>& words, int k)
{
//统计次数
map<string, int> countMap;
for (auto& e : words)
{
countMap[e]++;
}
//按次数排序,也就是按V排序
vector<pair<string, int>> v(countMap.begin(), countMap.end());
sort(v.begin(), v.end(), KVcomp());
//到这里,排序完成,到topk
vector<string> ret;
auto it = v.begin();
while (k--)
{
ret.push_back((*it).first);
it++;
}
return ret;
}
};对仿函数后面的补充就是因为:sort内部用快排实现,不稳定,所以会导致即使次数相同但原先在前面的单词也可能跑到后面去。
第二个解决方法:用stable_sort() 内部用归并,不存在上面的问题。
模拟实现
1.红黑树部分改造
1.改节点
红黑树是K V模型,但set是K模型,但需要再改一份K的红黑树吗?
没有这个必要,既然set和map都是用红黑树的逻辑来实现的,那么只需要给个模板参数,让红黑树的节点里的值,用参数的类型去初始化,这样:set以后传一个K类型,map以后传一个pair类型,都不影响功能
enum Colour
{
Red,
Black
};
template<class T>
class RBNode
{
public:
RBNode<T>* _left;
RBNode<T>* _right;
RBNode<T>* _parent;
T _data;
Colour _col;
RBNode(const T& data)
:_left(nullptr)
, _right(nullptr)
, _parent(nullptr)
, _data(data)
,_col(Red)
{}
};2.改插入
因为上面会改节点,那么插入时的比较逻辑就会出问题
![]()
像这样是KV的比较逻辑,但如果我传的是set的值,那只有K,上面却是pair的结构,怎么办呢?
给set和map内部封装一个仿函数,让它来做比较,我是set,取节点的K比较,我是map,取节点的first比较。



因为要调用仿函数(类中()的重载),得有个对象。set和map初始化节点时,会把仿函数类型也传给RBTree。
3.造迭代器
因为set和map的迭代器都是复用红黑树的,所以主要是实现红黑树的迭代器。
因为一会在写RBTree的时候,要实现iterator 和 const_iterator,所以在迭代器里重载* 和->时的返回值需要有普通的和带const的,咋办?
还是一样,传相应的参数,就调用相应的迭代器。因此,在模板里,添两个参数类型,对应返回值的T* 和 T&
template<class T,class Ptr,class Ref>
struct RBTreeIterator
{
typedef RBNode<T> Node;
typedef RBTreeIterator<T,Ptr,Ref> Self;
Node* _t;
RBTreeIterator(Node* t)
:_t(t)
{}
Ref operator* ()
{
return _t->_data;
}
Ptr operator->()
{
return &_t->_data;
}
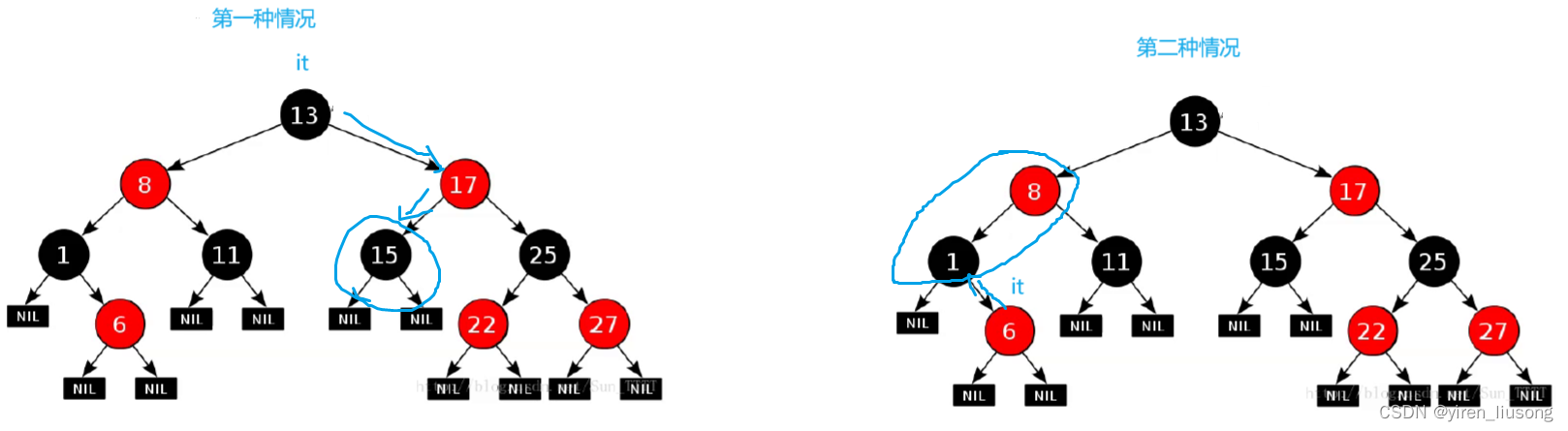
Self& operator++()
{
if (_t->_right)
{
//第一种情况:右孩子存在,去找右子树的最左节点
Node* subLeft = _t->_right;
while (subLeft->_left)
{
subLeft = subLeft->_left;
}
_t = subLeft;
}
//第二种情况:右孩子不存在,往上走,直到当前变成左孩子,那它的父亲就是要找节点
else
{
Node* cur = _t;
Node* parent = cur->_parent;
while (parent && cur == parent->_right)
{
cur = parent;
parent = cur->_parent;
}
_t = parent;
}
return *this;
}
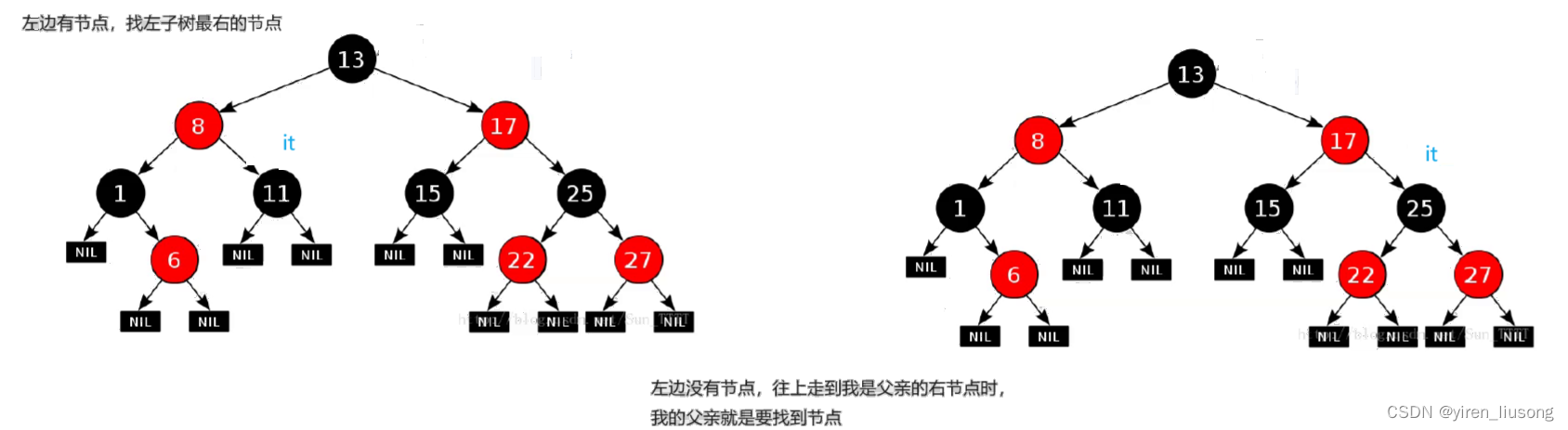
Self& operator--()
{
Node* subL = _t->_left;
//左孩子存在
if (subL)
{
//找左子树的最右节点
while (subL->_right)
{
subL = subL->_right;
}
_t = subL;
}
//左孩子不存在
else
{
//
Node* cur = _t;
Node* parent = cur->_parent;
while (parent && cur == parent->_left)
{
cur = parent;
parent = cur->_parent;
}
_t = parent;
}
return *this;
}
bool operator!=(const Self& t)
{
return t._t != _t;
}
bool operator==(const Self& t)
{
return t._t == _t;
}
};++操作要画个图:
--操作要画个图:
4.RBTree连入迭代器
既然是迭代器,必须要存在begin() 和end() ,它们要分别指向第一个元素(中序的),最后一个元素的下一个位置。
template<class K, class T, class KeyofT>
class RBTree
{
typedef RBNode<T> Node;
public:
typedef RBTreeIterator<T,T*,T&> iterator;
typedef RBTreeIterator<T,const T*, const T&> const_iterator;
RBTree()
:_root(nullptr)
{}
RBTree(const Node* root)
:_root(root)
{}
iterator beign()
{
Node* subLeft = _root;
while (subLeft && subLeft->_left)
{
subLeft = subLeft->_left;
}
return iterator(subLeft);
}
iterator end()
{
return iterator(nullptr);
}
const_iterator beign()const
{
Node* subLeft = _root;
while (subLeft && subLeft->_left)
{
subLeft = subLeft->_left;
}
return const_iterator(subLeft);
}
const_iterator end()const
{
return const_iterator(nullptr);
}5.插入再次改
因为set和map的插入的返回值都是pair,因此插入逻辑得改一下。
pair<iterator,bool> insert(const T& data)
{
if (_root == nullptr)
{
_root = new Node(data);
_root->_col = Black;
return make_pair(iterator(_root),true);
}
Node* cur = _root;
Node* parent = nullptr;
KeyofT kot;
while (cur)
{
if (kot(data) < kot(cur->_data))
{
parent = cur;
cur = cur->_left;
}
else if (kot(data) > kot(cur->_data))
{
parent = cur;
cur = cur->_right;
}
else
{
return make_pair(iterator(cur), false);
}
}
cur = new Node(data);
if (kot(parent->_data) < kot(data))
{
parent->_right = cur;
}
else if (kot(parent->_data) > kot(data))
{
parent->_left = cur;
}
//这一步是为了保存当前节点的parent,方便后续操作
cur->_parent = parent;
Node* newnode = cur;
//下面因为情况一和位置无关但二有关,所以写到一起也没啥事
while (parent && parent->_col == Red)
{
Node* grandfather = parent->_parent;
//情况一
if (parent == grandfather->_left)
{
Node* uncle = grandfather->_right;
if (uncle && uncle->_col == Red)
{
uncle->_col = parent->_col = Black;
grandfather->_col = Red;
//向上再处理
cur = grandfather;
parent = cur->_parent; // 此时如果parent不存在,就证明g就是根,while就不会进去,在下面会把根改成黑色。
}
//情况二
else
{
//情况二,单旋
if (cur == parent->_left)
{
RotateR(grandfather);
parent->_col = Black;
grandfather->_col = Red;
}
//情况三,双旋
else if (cur == parent->_right)
{
RotateL(parent);
RotateR(grandfather);
cur->_col = Black;
grandfather->_col = Red;
}
break;
}
}
else
{
Node* uncle = grandfather->_left;
if (uncle && uncle->_col == Red)
{
uncle->_col = parent->_col = Black;
grandfather->_col = Red;
//向上再处理
cur = grandfather;
parent = cur->_parent; // 此时如果parent不存在,就证明g就是根,while就不会进去,在下面会把根改成黑色。
}
else
{
//情况二,单旋
if (cur == parent->_right)
{
RotateL(grandfather);
parent->_col = Black;
grandfather->_col = Red;
}
//情况三,双旋
else if (cur == parent->_left)
{
RotateR(parent);
RotateL(grandfather);
cur->_col = Black;
grandfather->_col = Red;
}
break;
}
}
}
_root->_col = Black;
return make_pair(iterator(newnode), true);
};小细节:
首先,cur是新插入节点(是要返回它的迭代器的),但如果插入后要发生旋转,cur就要向上调整,cur的值会发生变化,所以需要提前保存一下cur的值,以便最后返回。
set的模拟实现
namespace bit
{
template<class K>
class set
{
struct SetKeyofT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename RBTree<K, const K, SetKeyofT>::iterator iterator;
typedef typename RBTree<K, const K, SetKeyofT>::const_iterator const_iterator;
pair<iterator,bool> insert(const K& key)
{
return _t.insert(key);
}
iterator begin()const
{
return _t.beign();
}
iterator end()const
{
return _t.end();
}
iterator Find(const K& key)
{
return _t.Find(key);
}
private:
//我的成员是一个红黑树的节点
RBTree<K, const K,SetKeyofT> _t;
};注意:因为无论如何set的值K都不可被改变,所以他只可以封装为const迭代器。
map的模拟实现
namespace bit
{
template<class K, class V>
class map
{
public:
struct MapKeyofT
{
const K& operator()(const pair<K,V>& kv)
{
return kv.first;
}
};
typedef typename RBTree<K, pair<const K, V>, MapKeyofT>::iterator iterator;
typedef typename RBTree<K, pair<const K, V>, MapKeyofT>::const_iterator const_iterator;
iterator begin()
{
return _t.beign();
}
iterator end()
{
return _t.end();
}
const_iterator begin()const
{
return _t.beign();
}
const_iterator end()const
{
return _t.end();
}
pair<iterator, bool> insert(const pair<K,V>& kv)
{
return _t.insert(kv);
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert(make_pair(key, V()));
return ret.first->second;
}
private:
//我的成员是一个红黑树的节点
RBTree<K,pair<const K,V>,MapKeyofT> _t;
};注意:因为map有[ ]的使用,所以重载了[ ]
重载[ ]主要还是用insert的返回值:传入K,构造一个K V的pair返回给ret,ret的iterator就是保存这个节点的迭代器,而[ ]就是可以通过传进来的K来进行插入(K,V()的默认构造)形成一个节点,[ ]会通过ret的first这个节点找到对应的V值。
【有道云笔记】STL———map和set容器
https://note.youdao.com/s/UWxCLQlS















 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









