






基于大模型的具身智能系统核心要点
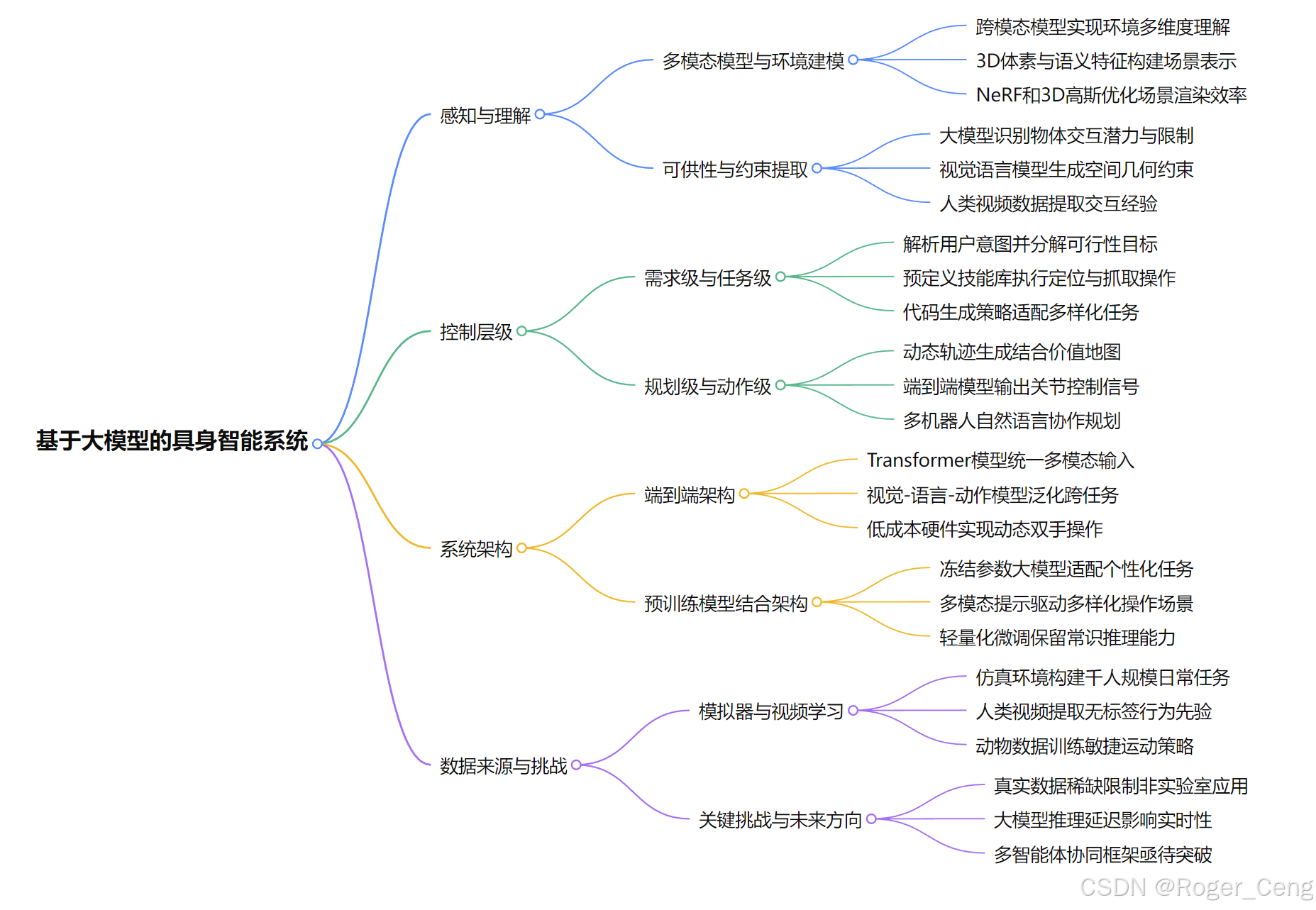
1. 感知与理解
- 多模态模型:GPT-4V、CLIP等跨模态模型实现对环境的多维度理解(文本、图像、3D场景),支持开放词汇检索和闭环规划。
- 环境建模:采用3D体素、NeRF、3D高斯等技术构建语义化场景表示,结合SLAM实现动态环境感知与实时交互。
- 可供性与约束:利用大模型提取物体交互潜力(如抓取点、工具使用),结合物理约束生成可行动作序列。
- 人类反馈:通过自然语言或视觉提示调整任务执行,如OLAF通过用户指令修正机器人行为。
2. 控制层级
- 需求级:大模型解析用户意图(如SayCan、Text2Motion),结合物理可行性生成任务目标。
- 任务级:分解复杂任务为子技能(如OK-Robot的定位-抓取流程),利用预定义技能库(如CaP生成代码策略)。
- 规划级:动态生成轨迹(如VoxPoser的3D价值地图)、多机器人协作(如Swarm-GPT无人机编队)、长期目标规划(如iVideoGPT预测未来状态)。
- 动作级:端到端输出关节控制信号(如Gato多任务控制、ALOHA的双手精细操作)。
3. 系统架构
- 端到端架构:
- RT系列(RT-1/RT-2/RT-X):基于Transformer的视觉-语言-动作模型,支持跨任务泛化。
- Mobile ALOHA:低成本硬件实现移动操作,结合扩散策略处理动态任务。
- 预训练模型结合架构:
- TidyBot:冻结参数的大模型(CLIP+LLM)处理个性化任务。
- VIMA:多模态提示驱动,适应多样化机器人操作场景。
4. 数据来源
- 模拟器:
- BEHAVIOR-1K构建千人规模日常任务仿真环境,Omnigrasp通过强化学习生成灵巧操作数据。
- DrEureka自动优化奖励函数,解决Sim2Real迁移问题。
- 模仿学习:
- HumanPlus通过人体动作映射采集人形机器人数据,UMI框架支持低成本动态操作演示。
- 视频学习:
- RoboCLIP从单视频/文本生成奖励函数,VPT利用无标签视频预训练行为先验。
5. 挑战与未来方向
- 数据瓶颈:真实数据稀缺,需提升非实验室环境采集效率(如AutoRT自动化数据框架)。
- 实时性:大模型推理延迟高,需结合轻量化模型(如LLM规划+小模型控制)。
- 多智能体协同:灾难救援等复杂场景需高效通信框架(如AutoRT多机器人协作)。
- 技术融合:3D高斯提升SLAM精度,扩散模型增强动作生成多样性,具身多模态大模型(如GPT-4o)推动通用性发展。
应用前景
- 家庭服务:物品整理、烹饪等个性化任务(TidyBot)。
- 工业:灵巧抓取(Omnigrasp)、多机器人协作(Swarm-GPT)。
- 医疗/教育:交互式代理(InteractiveAgent)支持诊疗、教学场景。
- 科研:Open X-Embodiment等开源数据集加速技术迭代。
总结:大模型显著提升具身智能的感知、规划和泛化能力,但需突破数据、实时性与复杂场景适应性的技术瓶颈。未来将向多模态融合、轻量化部署、群体协作方向发展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









