







使用前馈神经网络时,对于一个输入得到一个输出,但是这没办法处理一个序列数据输入的情况,例如语音的输入。这时就出现了这样一种模型-循环神经网络,专门用于处理序列数据的神经网络。
一.循环神经网络(RNN)
1.网络结构
基础仍然是一个前馈神经网络,重点在于随着序列的输入,这个网络在重复地被使用,所以称为循环神经网络。所以一般我们见到的RNN的结构图都是将一个普通网络随着序列输入展开,或者说沿着时间轴展开的。
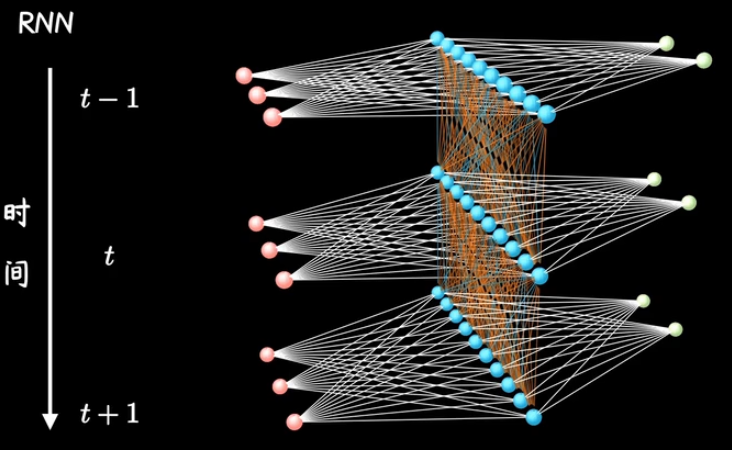
将(结构图+时间轴)抽象为简单循环计算图,RNN的重点就是,此刻网络的计算是和前一刻网络的计算相联系的

2.普通RNN的前向计算
 x是输入,o是输出,h是隐藏层计算出的特征。输入层x到隐藏层h的参数权重矩阵是U,隐藏层h到输出层o的权重是V。前一时刻隐藏层
h
t
−
1
\ h_{t-1}
ht−1到后一时刻隐藏层
h
t
\ h_t
ht的参数权重是W。
x是输入,o是输出,h是隐藏层计算出的特征。输入层x到隐藏层h的参数权重矩阵是U,隐藏层h到输出层o的权重是V。前一时刻隐藏层
h
t
−
1
\ h_{t-1}
ht−1到后一时刻隐藏层
h
t
\ h_t
ht的参数权重是W。
| t时刻输入 x t x_t xt | t-1时刻的隐藏层提取的特征是 h t − 1 \ h_{t-1} ht−1 |
|---|---|
| a t = b + W h t − 1 + U x t \ a_t = b + Wh_{t-1} +Ux_t at=b+Wht−1+Uxt | 隐藏层的权重和偏执的线性变换 |
| h t = t a n h ( a t ) \ h_t = tanh(a_t) ht=tanh(at) | 隐藏层的激活函数 |
| o t = c + V h t \ o_t = c + Vh_t ot=c+Vht | 输出根据需要选择全连接层或者其他 |
图中从输入到输出只有一层隐藏层,只不过这个隐藏层被重复使用,并且留下特征给下一刻使用。
3.用伪代码描述
import numpy as np
class RNN:
def __init__(self):
self.W = np.random.random()
self.U = np.random.random()
self.b = np.random.random()
def forward(self, x,h):
if(x == "结束"):
return h
else:
a = np.dot(self.W, h) + np.dot(self.U, x) + self.b
h = np.tanh(a)
x = get_data()
return self.forward(x,h)
h_0 = np.zeros()
x_1 = get_data()
rnn = RNN()
h = rnn.forward(x_1,h_0)
#这个伪代码中只是描述了前向循环计算了中间层h的结果,省略了输出层o的描述
二.Seq2Seq
理解注意力机制之前,先了解一个循环网络的变种,序列到序列架构(Seq2Seq)。这个模型是一个RNN的变种,从一个序列生成另外一个序列,但是输出序列长度不确定。
1.网络结构
Seq2Seq由两个RNN组成,前一个叫编码器,后一个叫解码器。图中的C代表context,意思是上下文。编码器把所有的输入序列都编码成一个固定长度的上下文,然后再由解码器解码。
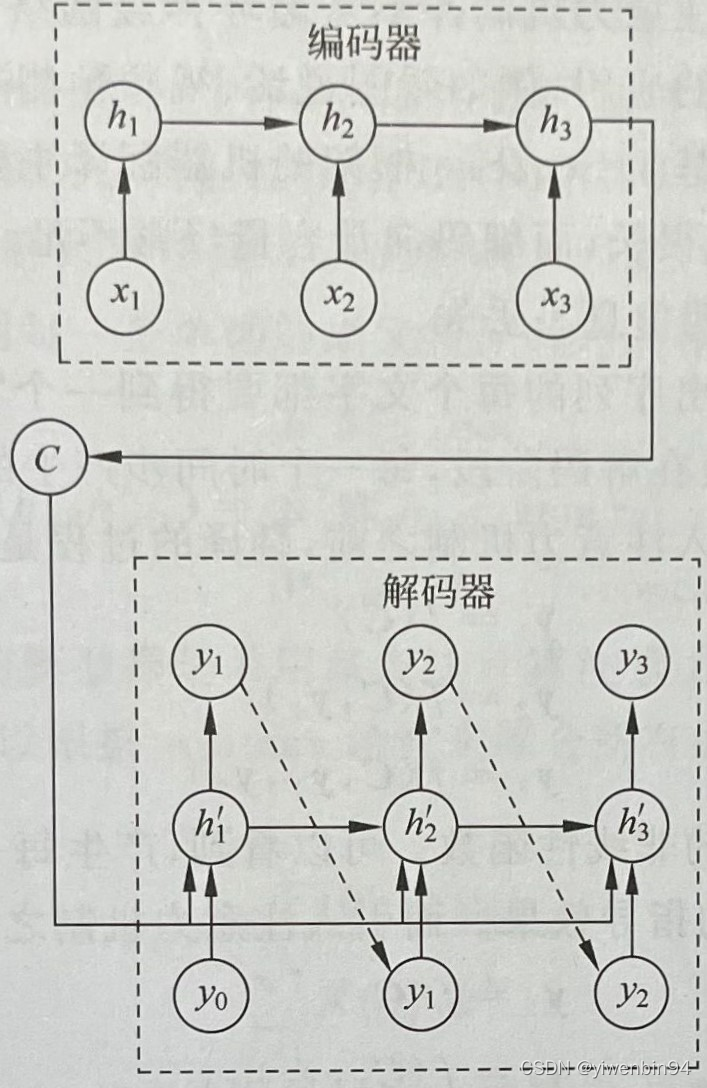
2.解码器工作流程
从普通RNN的角度理解编码器很好理解了,那么解码器是如何工作的呢?
解码这个过程的任务是负责根据上下文C生成指定的序列,方式不固定。
(1)上面的结构图中表示的,语义向量C参与了序列所有时刻的运算,上一时刻的输出转而作为当前时刻的输入,但语义向量C会参与所有时刻的运算。
(2)如果想用最简单的方式,那就是将C作为初始状态输入到解码器的RNN中。
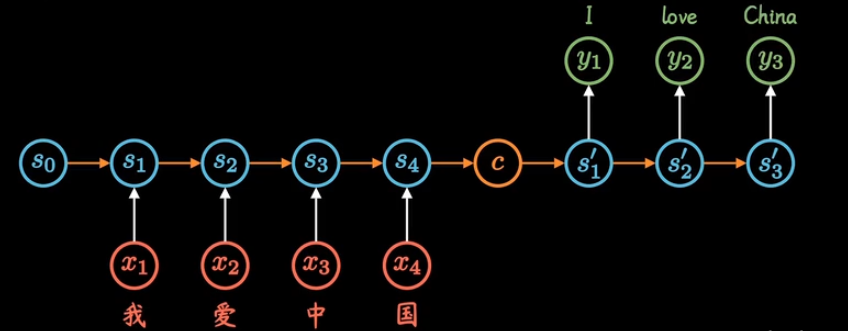
三.NLP中的注意力机制(Attention)
Seq2Seq有局限性:(1)上下文向量C的长度是固定的,如果原始序列的信息太多,它的长度就成了限制模型性能的瓶颈。(2)上下文只来自编码器的最后一次隐藏层输出,解码的时候,不同时刻使用的上下文信息是同样的,输出序列与输入序列在不同时刻的对应关系不能很好的捕获。就像是只能交替传译而不能同声传译。
1.网络结构
为了能实现同声传译,有学者研究建议,将C向量变为一个长度可变的序列,将输出序列的每一个元素关联匹配不同的上下文C,这一机制称为注意力机制。
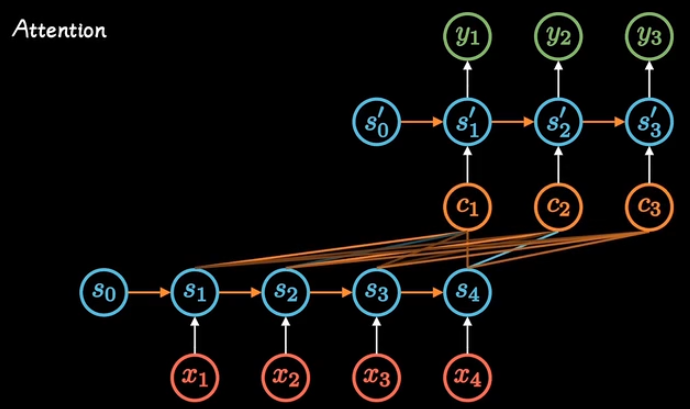
2.前向传播中的注意力矩阵
编码器的不同时刻隐藏层,到上下文这一层,可以看作一层全连接,注意力大小,就是权重,注意力矩阵是我们要训练的东西。
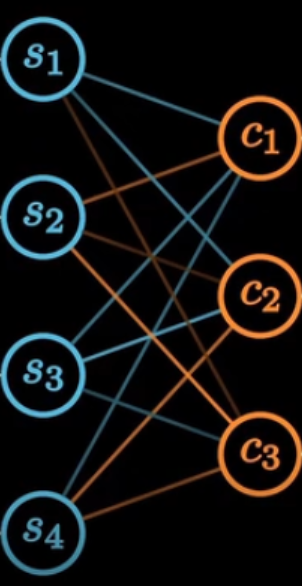
3.总结
核心思想:在序列到序列的这种结构中,输出序列的每一部分对输入序列的上下文Context的理解和关注点应该是不同的。
1.相比普通RNN ,参数更少。
2.Attention的计算可以并行处理,速度更快。
3.长序列最开始的信息没有被弱化,效果更好。














 1328
1328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









