







hadoop集群搭建好以后,spark的集群安装就比较简单了。只需要将spark压缩包解压并配置相应的环境变量就可以了。spark也可以看成是hadoop的一部分,他主要是用来取代Hadoop的MapReduce操作,依然依赖于Hadoop的分布式文件系统HDFS以及Hadoop的资源调度系统yarn。当然spark也可以基于其他的资源调度系统甚至是local模式。下面我们就来介绍spark的安装与配置。
1.首先依然是去官网下载压缩包spark-2.2.1-bin-hadoop2.7.tgz利用Xftp上传到master
解压tar -zxvf spark-2.2.1-bin-hadoop2.7.tgz
重命名mv spark-2.2.1-bin-hadoop2.7 spark
2.配置环境变量,修改/etc/profie
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.7/
export PATH=$PATH:$SPARK_HOME/bin复制spark-env.sh.template成 spark-env.sh
cp spark-env.sh.template spark-env.sh
3.修改spark-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_121
export SCALA_HOME=/usr/share/scala
export HADOOP_HOME=/opt/hadoop-2.7.3
export HADOOP_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoop
export SPARK_MASTER_IP=114.55.246.88
export SPARK_MASTER_HOST=114.55.246.88
export SPARK_LOCAL_IP=114.55.246.88
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.7
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.3/bin/hadoop classpath)复制slaves.template成slaves
修改slaves,添加:slave1 slave2 slave3
将配置好的spark文件复制到slave1 2 3
scp /usr/spark root@slave1:/usr
修改slave1 2 3配置
在slave1 2 3上分别修改/etc/profile,增加Spark的配置,过程同Master一样。
在slave1 2 3修改$SPARK_HOME/conf/spark-env.sh,将export SPARK_LOCAL_IP=114.55.246.88改成Slave1和Slave2对应节点的IP。
在spark上启动集群
/usr/spark/sbin/start-all.sh
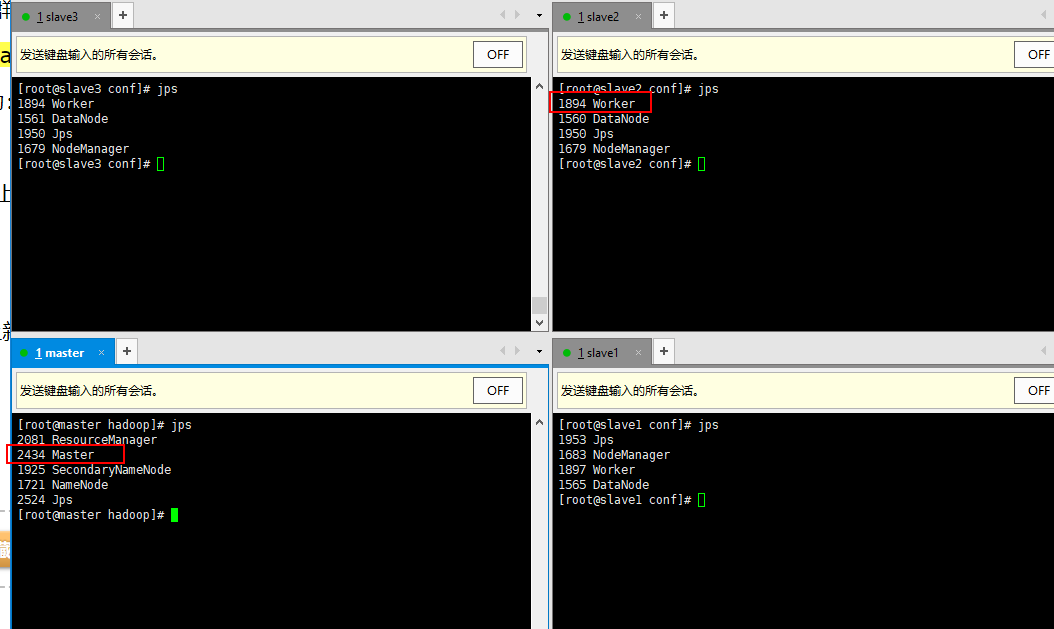
查看启动状态
运行命令JPS















 553
553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









