







前两天用PowerBI做了一个多元线性回归基于R语言的内容,点击《PowerBI多元回归预测数据(R语言)》可以查看,但是好像现在Python在人群中使用的更多,后面类似的涉及统计模型和机器学习的内容应该也会以Python为主,下面开始介绍一下Python和PowerBI一起实现多元线性回归并在PowerBI中进行筛选预测的方法,效果如下↓
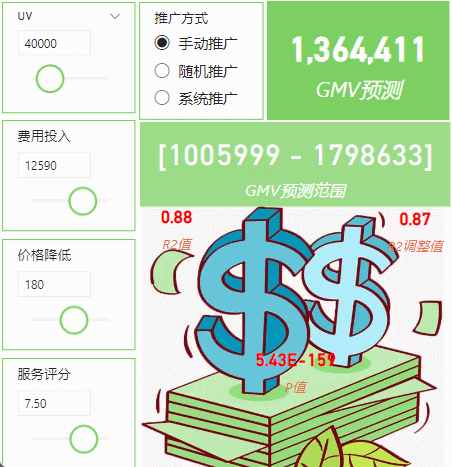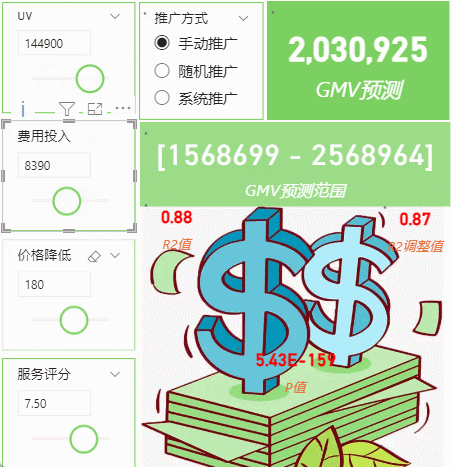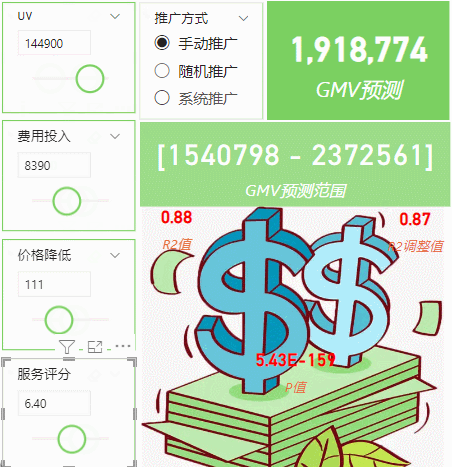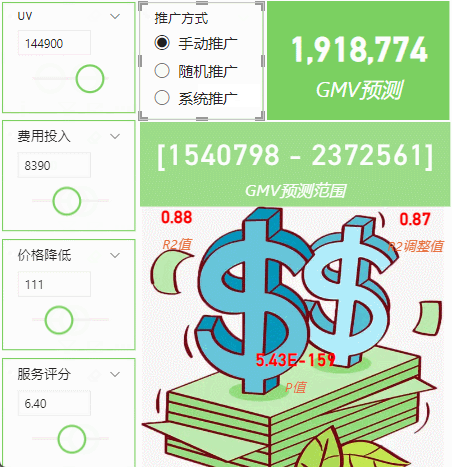
从图中看应该还是清楚,过了两天我们又新增了p值检验参数,并且还新增了一个维度,就是推广投放费用的时候有三种投放规则(随机投放、手动精确投方和系统投放),这三个是定性变量,还需要独热编码转换成数值。新增了这个参数后,我们模型的匹配率更高了,之前R2是0.78左右,有了这个维度,R2直接上升到了0.88,几乎接近完美了。下面简单介绍一下实现方法。
数据还是之前的数据,只是又新增了一个费用投放方式的维度,如下↓

然后流程是PowerBI导入数据,这个数据很完整了,不需要清洗,不需要聚合,直接拿来使用就可以了,下面就是重点,如何调用Python来完成我们重点的参数计算。在Python里面有两种主流计算多元回归的方法,通过statsmodels里面OLS方法,或者调用SKlearn里面的线性回归方法都可以。我们这里使用的是第一种,因为第二种调用SKlearn的方法后面其他的机器学习模型应该会经常用到。
需要指出的是,我们有一个推广方式的字段是分类值,需要使用pd里面的get_dummies进行独热编码处理后才能使用。处理然后把数据合并在一起,加上一个1的常数列,就可以用一句很简单的语句建模拟合数据了,然后把拟合的参数转换成DataFrame格式,PowerBI就可以识别了,Python语句和结果如下↓
import pandas as pd
import statsmodels.api as sm
#数据预处理,分类数据编码(独热编码)
pro_t = pd.get_dummies(dataset['promotion_type'],prefix="pro_t")
df1 = pd.concat((dataset.iloc[:,2:6],pro_t), axis=1)
X = sm.add_constant(df1)
Y = dataset.iloc[:,1]
#建模。参数估计(回归系数、总体方差)
model = sm.OLS(Y, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2159
2159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









