









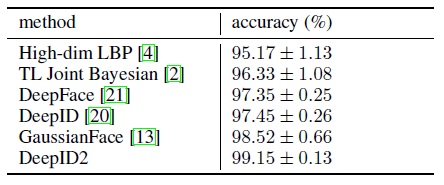
DeepID2 face recognition
DeepID2[1]采用了和DeepID相似的网络架构,但是又有很多不同,除了前期patches的准备方法,还有训练的方式,最终分数的融合方法。LFW上的人脸验证准确率也达到了99.15%,人类的准确率为99.20%,这是计算机第一次在人脸验证领域与人类不相上下。
Network Architecture
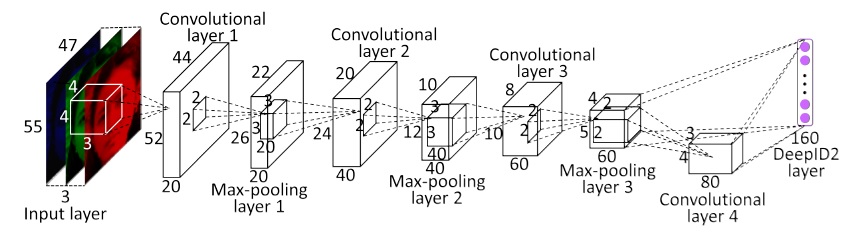
DeepID2的网络结构和DeepID基本一致,图片是从论文中截取的,最后连接的softmax层没画上。网络的结构如下:
1.Four convolutional layers
2.Three maxpooling layers
3.One full connection layer(DeepID2 feature layer)
4.each maxpooling layer is followed by ReLU
5.DeepID2 is a fully connect layer followed by ReLU
补充一下,经maxpooling后的conv3层与conv4层一起直接连接到DeepID2层,cov3主要是保留局部特征,conv4主要保留全局特征。这个和DeepID没什么区别。
Training
从训练的整个过程我们就能看到DeepID2与DeepID的不同之处首先是样本的准备就不一样。
face patches preparation
作者采用了SDM[2]算法检测出21个facial landmarks,然后根据这些landmarks对人脸样本进行调整,最终根据不同的位置,尺度,颜色生成200个patches,然后水平翻转扩充成400个。至此所有样本准备完毕,后续作者还做了处理。
learning algorithm
在训练的过程中,DeepID2引入了两个Loss function——
Ident(f,t,θid)
和
Verif(fi,fj,yij,θve)
。它们分别对应于face identification和face verification。文章通过将两者结合,达到增大inter-personal variation,同时减小intra-personal variation的目的。
其中
Ident(f,t,θid)
采用交叉熵
Ident(f,t,θid)=−∑ni=1pilogp^i=logp^i
Verif(fi,fj,yij,θve)
采用L2范数
训练的方法如下所示:

首先每次训练的时候样本都是成对输入的,这样才能计算 Verif(fi,fj,yij,θve) ,通过梯度下降法不断更新网络参数。其中的 λ 用于调节identification和verification之间的权重,实验部分会有专门介绍如何选择 λ 。
Face Verification

在这一部分,文章根据生成的400个patches训练网络,生成400个160维的DeepID2 feature,然后在face varification的时候,还是利用DeepID一样的方法Joint Bayesian[3]。
但是,在训练Joint Bayesian model之前,文章对400个DeepID2 feature进行了筛选,采用forward-backward greedy algorithm[4]选出其中的25个,然后将它们组合成一个25×160=4000维的向量,利用PCA降至180维,然后得到了98.97%的准确率。
Experiments
这一部分,文章介绍了
Ident(f,t,θid)
和
Verif(fi,fj,yij,θve)
的重要性,
λ
如何确定,人脸identity数量对结果的影响,以及不同的
Verif(fi,fj,yij,θve)
的性能。最后文章通过进一步介绍一些实验细节,说明作者是如何达到99.15%这个准确率的。
其中由于LFW上大部分人只有一个样本,所以文章采用了外部数据库CelebFaces+进行训练,只在LFW上进行测试。
Balancing the identification and verification signals
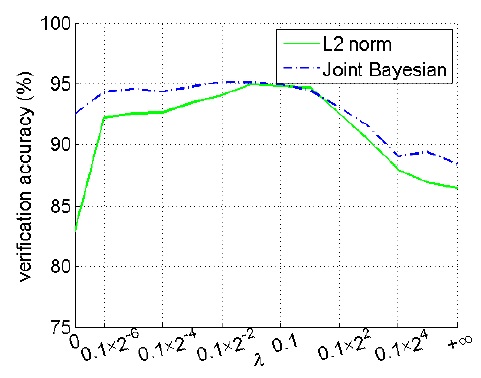
上图曲线说明
λ
太大或太小都会影响结果,比较合适的值为0.05。之后,作者还对这个值的选择做了进一步的解释。
inter-personal scatter matrix:
Sinter=∑ci=1ni(xi¯−x¯)(xi¯−x¯)T
intra-personal scatter matrix:
Sintra=∑ci=1ni∑x∈Di(x−xi¯)(x−xi¯)T
它们的特征值越小,对应的方差越小。这里我们再强调一下,我们需要inter-personal variance越大越好,同时intra-personal variance越小越好。这是一个看似很矛盾的条件。但是,作者通过下面的图说明了通过做一点点牺牲,能够有效的使两者达到平衡。
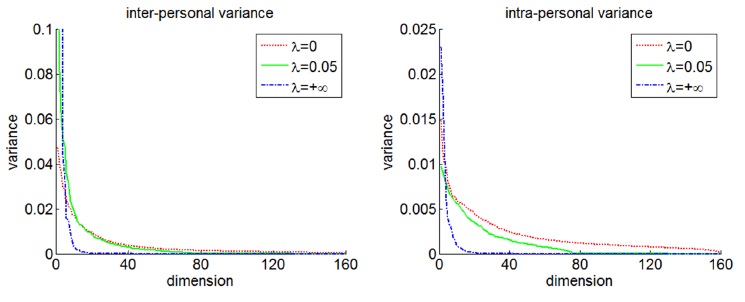
从图中看出,当
λ
从0增加到0.05时,inter-personal variance基本不变,甚至在某些地方还会略微提升,而intra-personal variance变小了,这就是一个折中的选择。
文章还通过PCA对其降维画出其中的前两个特征的散点图给我们更加形象的展示了不同
λ
的效果:
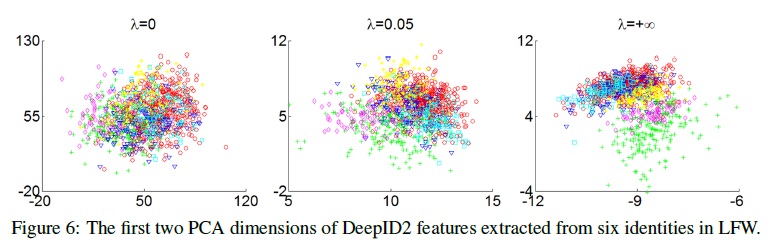
Rich identity information improves feature learning
这一部分还是和DeepID差不多,就是为了说明identity越大越好。我们发现,其实最后L2 norm与Joint Bayesian方法的效果已经非常的接近了。
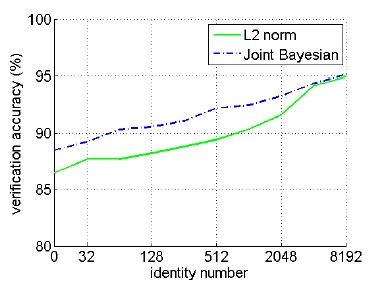
Investigating the verification signals
这里文章对比了几个不同的
Verif(fi,fj,yij,θve)
,说明还是L2最好,同时说明它的关键就在于减小intra-personal variance

Final system
为了达到更好的效果,文章利用forward-backward greedy algorithm[4]又重复选择出了6组不同的25个DeepID2 features,并且保证每个feature不重复。
然后用这7组数据训练Joint Bayesian[3]得到7个score,最后利用这些score训练SVM将其融合,得到预测结果,最终达到了99.15%的准确率。

参考文献
[1] Sun Y, Chen Y, Wang X, et al. Deep learning face representation by joint identification-verification[C]//Advances in Neural Information Processing Systems. 2014: 1988-1996.
[2] X. Xiong and F. De la Torre Frade. Supervised descent method and its applications to face alignment. In Proc. CVPR, 2013.
[3] D. Chen, X. Cao, L. Wang, F. Wen, and J. Sun. Bayesian face revisited: A joint formulation. In Proc. ECCV, 2012.
[4] T. Zhang. Adaptive forward-backward greedy algorithm for learning sparse representations. IEEE Trans. Inf. Theor. 57:4689–4708, 2011.















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









