









DeepID2+ face recognition
DeepID2+[1]的结构与DeepID2[2]基本一致,不同之处在于每个conv layer的feature maps数量不同,同时每个conv layer在maxpooling之后都连接了fully-connected layer(简称Fc-1,Fc-2,Fc-3,Fc-4)。与DeepID2一样,DeepID2+也引入了identification signals和verifacation signals,并且在所有的Fc层(Fc-1,Fc-2,Fc-3,Fc-4层)均含有这两类信号。
由于对结构进行了调整,使得人脸验证的准确率提升到了99.47%,并且对遮挡情况具有一定的鲁棒性。除此之外,在论文中作者还验证了DeepID2+的三个特性——sparsity,selectiveness和robustness,试图揭示深度神经网络为何具有如此高效的性能。
Network Architecture

上图为DeepID2+的网络结构。这里有几个不同的地方:
1.每个conv层的feature maps都增加到了128
2.training set更大,除了包含原来DeepID,DeepID2使用的CelebFaces+,还加入了WDRef数据集。使得训练集包含了290000 张12000不同identities的人脸,在之前的DeepID2中使用的数据集只包含了160000张8000不同identities的人脸。
3.对于每个conv层,在maxpooling之后都会连接一个fully-connected层,它们作为最终的人脸feature,后面的实验会介绍这几个fc层的使用,FC-4的鲁棒性是最好的。每个FC层都是512维的,训练的过程中都引入了identification signals和verifacation signals。
可以看出,相比于DeepID2,DeepID2+的网络规模更大,而且引入的信息也更多了。
Performance
在训练的过程中,参数的更新方式和DeepID2基本一样,input face patches也采用了和DeepID中一样的25个patches。
测试的时候,DeepID2+采用了FC-4 layer作为特征。
在性能上,25个不同的DeepID2+ features都完胜DeepID2 features

Three Properties
在介绍了DeepID2+之后,作者还试图从本质上揭示它如此高效的本质,揭开深度神经网络的神秘面纱。
sparsity
对于同一张输入图像,不同的神经元对它的反应是不同的,大概有一半的神经元处于激活状态,而另一半处于抑制状态,这使得不同的identity具有最大的区分性。
而对于同一神经元,大概有一半的样本能将其激活,而对另一半处于抑制状态,这使得神经网络具有最大的区分能力。
同时,是否使用dropout对上述两种现象基本没有影响。

之后,文章还验证了神经元的激活状态比激活值更重要,在将DeepID2+ features二值化之后,得到的验证结果只比原来稍微下降一点。将来可采用binary code直接作为特征,这样既能提高匹配速度,还能节省存储空间。

selectiveness
这里说明DeepID2+ features具有属性信息,除了能利用它来进行face cerification,还可以用来进行性别、肤色、种族等的区分。
除此之外,每个神经元对同一identify或者attribute的敏感程度不同,200左右的神经元较为活跃,neural ID大于400的神经元活跃度很低。而对于其它所有的图像,活跃度变化基本不大,而且活跃度基本处于中间位置,这里可以看出它增加了网络的识别能力。下图也显示了这一现象。
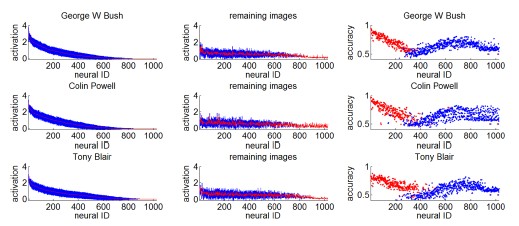
神经元激活值的分布直方图也反映了这一现象,我们可以看出,神经元对于不同的identify和attirbute都会有相应的反应,每个神经元都有一定的记忆性,包含大量的样本属性信息。


robustness

作者对测试样本采用了两种不同的处理方法——从下往上按一定比例遮挡,随机block遮挡。
但是这里有一点需要注意的是,训练样本中并未含有经遮挡处理后的图像,而在后面的人脸验证中却对遮挡具有很好的鲁棒性,这也说明了DeepID2+有多神奇。

对于不同的遮挡情况,神经元的激活值有会有相应的变化,当遮挡面积越来越多的时候,神经元的激活状态就开始具有一定的随机性。回想一下前面介绍的神经元激活值分布直方图,其实随着遮挡面积的增加,它就趋向于将输入识别为其它类别时的激活情况一致,因此这些神经元就失去了特殊性。
实验中作者还将25个FC-4+ features合并(DeepID2+ combine),同时还分别测试single FC-1,FC-2,FC-3,FC-4以及传统特征提取方法LBP,验证它们对于遮挡情况的鲁棒性。发现FC-1,FC-2,FC-3,FC-4鲁棒性基本上是从小到大排列的,DeepID2+ combine最高,而传统的LBP是最差的。在遮挡面积达到40%的时候,DeepID2+还能保持在90%以上。occlusion block大小为50×50的时候,DeepID2+最高还能达到92.4%,而LBP急剧下降。


25个FC-4组成的DeepID2+ combine features具有非常好的鲁棒性,同时二值化后的DeepID2+ combine features仍然能基本上完全保留原来的信息,可分性依然非常高,相比DeepID2,DeepID2+ combine features的维度更大一些。
参考文献
[1] Sun Y, Wang X, Tang X. Deeply learned face representations are sparse, selective, and robust[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 2892-2900.
[2] Sun Y, Chen Y, Wang X, et al. Deep learning face representation by joint identification-verification[C]//Advances in Neural Information Processing Systems. 2014: 1988-1996.















 8647
8647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









