







这篇承接上一篇,FRCN是rbgirshick在R-CNN基础上提出的改进,提出了一些创新式的做法,不仅提升了训练和测试时的速度,而且提升了精度。

SPPnet是Kaiming He提出的一种结构,论文链接在这:https://arxiv.org/abs/1406.4729
可以看出,FRCN不仅在精度上得到了提升,更重要的是,它在测试时比RCNN快了213倍,这让实时处理成为可能(当然faster RCNN基本已经达到了实时的要求)。接下来我们首先分析一下这篇论文:https://arxiv.org/abs/1504.08083
写在解读之前:
通篇阅读下来,实在敬服rbgirshick大神。有理有据,对比实验,实现,思路都十分清晰。尤其是第五部分,对那几个问题的探讨和对比实验,更是让人茅塞顿开。RBG大神的学术态度真是高山仰止!
一.论文解读
1.Introduction
detection有两方面的挑战。第一,大量的候选区域需要被处理;第二,候选区域只能提供大致的定位,所以必须被细调来达到精确的定位。这两个挑战让众多解决方案只能牺牲速度和精度。
RCNN是一个多级的过程,首先提取约2k个候选区域,然后使用log loss微调一个卷积网络,最后,训练SVMs作为检测器。RCNN在测试时很慢(在GPU上大约47s/image),因为每一个候选区域都需要在卷积网络中做一遍前向传播,没有共享计算。
SPPnet改进了这一点,它将整张图片作为输入得到一张特征图,然后再用特征图中提取到的特征向量分类每一个候选区域,但SPPnet同样是一个多级过程。
rbgirshick认为FRCN有以下几个贡献:
1.更高的检测质量(mAP)相比于RCNN和SPPnet
2.使用一个多任务的loss,训练时单级的
3.训练可以更新所有网络层
4.不需要为特征缓存提供磁盘存储
2.Architecture和training
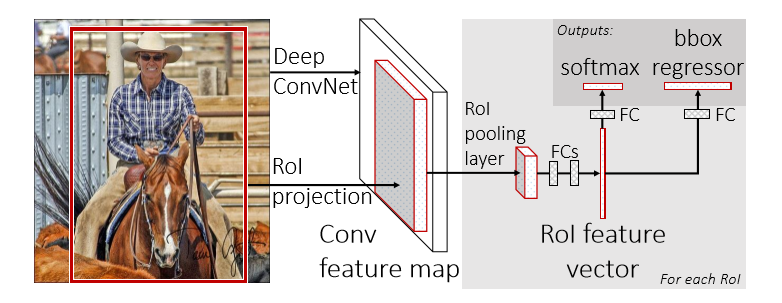
这张图就是FRCN的架构图。一个FRCN网络使用整张图片和候选区域集做为输入,网络首先处理整张图片得到一个卷积特征图,然后,为每个候选区域的ROI(region of interest)池化层从特征图中提取一个固定长度的特征向量,每个特征向量被送入全连接层,最终分成两个兄弟输出层:一个产生softmax概率评估K个物体类别外加一个"背景"类,另一个为每一个物体类输出4个实数值,每个4个值的集合都是K个类别的位置细调的结果。
2.1 ROI pooling layer
ROI池化层是SPP(spatial pyramid pooling)层的特殊情况,这里等看完SPPnet那篇文章再来详细解释
2.2 Initializing from pre-trained networks
一个预训练的网络初始化一个FRCN网络,需要三个转换:
1.最后一层最大池化层被一个ROI层替代来和网络的第一个全连接层相容
2.最后一个全连接层和softmax层被前文所述的兄弟层替代
3.网络需要被修改成采用两个输入:一个图像列表和这些图像中的ROIs列表
2.3 Fine-tuning for detection
使用反向传播方法来训练所有网络层的参数是FRCN的一个重要能力。首先,文中阐释了为什么SPPnet不能更新SPP层以下的层的参数的原因。根本原因是因为RCNN和SPPnet训练时的样本来自不同的图像,导致SPP层的反向传播非常低效。这种低效性来源于每个ROI基本都有一个非常大的感受野,经常就是整张图片。
文中提出了一个有效的方法。在FRCN训练过程中,SGD mini-batches是分层抽样的,首先采样N张图片,然后采用对每一张图片采样R/N个ROIs。关键是在前向和反向计算时,来自同一张图片的ROIs共享计算和内存,这大大减少了一个mini-batch的计算。例如,当N=2,R=128时,这种方法比从128个不同的图像中提取一个ROI的方法要快64倍。这种策略的一个缺点在于其可能会减慢训练的收敛因为来自同一张图片的ROIs是相关的。但是在实践中这种担忧并没有出现,当N=2,R=128时,比RCNN使用更少的SGD迭代得到了更好的结果。
Multi-task loss FRCN网络有两个子输出。第一个输出一个离散的概率分布(每一个ROI),p= ,对应于K+1个类别。第二个输出边界框的回归偏移,
,对应于K+1个类别。第二个输出边界框的回归偏移,
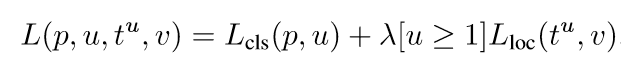
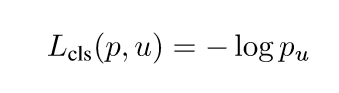
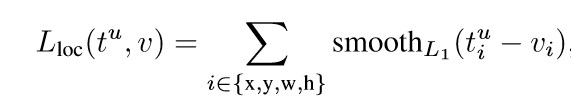
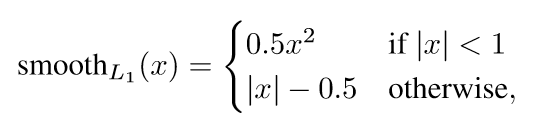
这是文中用于多分类任务的损失函数,u是具体的物体类别,而v则代表边界框的回归目标。
Mini-batch sampling 每个mini-batch来自于N=2张图片,mini-batch size取R=128,也就是从每张图片中取64个ROIs。25%的ROIs来自候选区域中和标注边界框有至少0.5(IoU)重叠,这些ROIs包含标记有前景对象类的示例,也就是u>=1的那些具体物体,剩下75%的ROIs取自最大IoU在[0.1,0.5)之间的候选区域,代表u=0的背景样例。训练时,图片以0.5的概率采用水平翻转,不采用其他的数据增强技术。
Back-propagation through RoI pooling layers 这一部分是推导ROI层的前向和反向传播函数
SGD hyper-parameters 分类和回归的全连接层分别被初始化为0均值的高斯分布,标准差分别是0.01和0.001.偏置项被初始化为0.所有层的learning rate初始化为0.001,30k次迭代后,lr降至0.0001,再训练10k次。但训练大数据集时,迭代更多次。momentum初始化为0.9,weight_decay初始化为0.0005
2.4 Scale invariance
文中探索了两种实现尺度不变性的物体检测的方法:一种通过蛮力学习,另一种是用图像金字塔。
3.Fast R-CNN detection
一旦FRCN网络微调完成,检测任务只需要前向传播这一个简单的步骤就可以完成(假设候选区域已经被提前计算好了)。网络用一张图片(或一个图像金字塔)和用于评分的R个候选区域列表作为输入。
3.1 Truncated SVD for faster detection
对于整张图片分类,花在全连接层的时间要远小于卷积层。而对于检测任务,当ROIs的数量较大时,大约一半的时间都用于计算全连接层。这时,我们可以对全连接层采用SVD(奇异值分解)的方法,减少其参数,从而加速运算速度。
4.Main Results
接下来就是实验结果了,主要有三个贡献:
1.在VOC07,2010和2012上均得到了state-of-the-art mAP结果
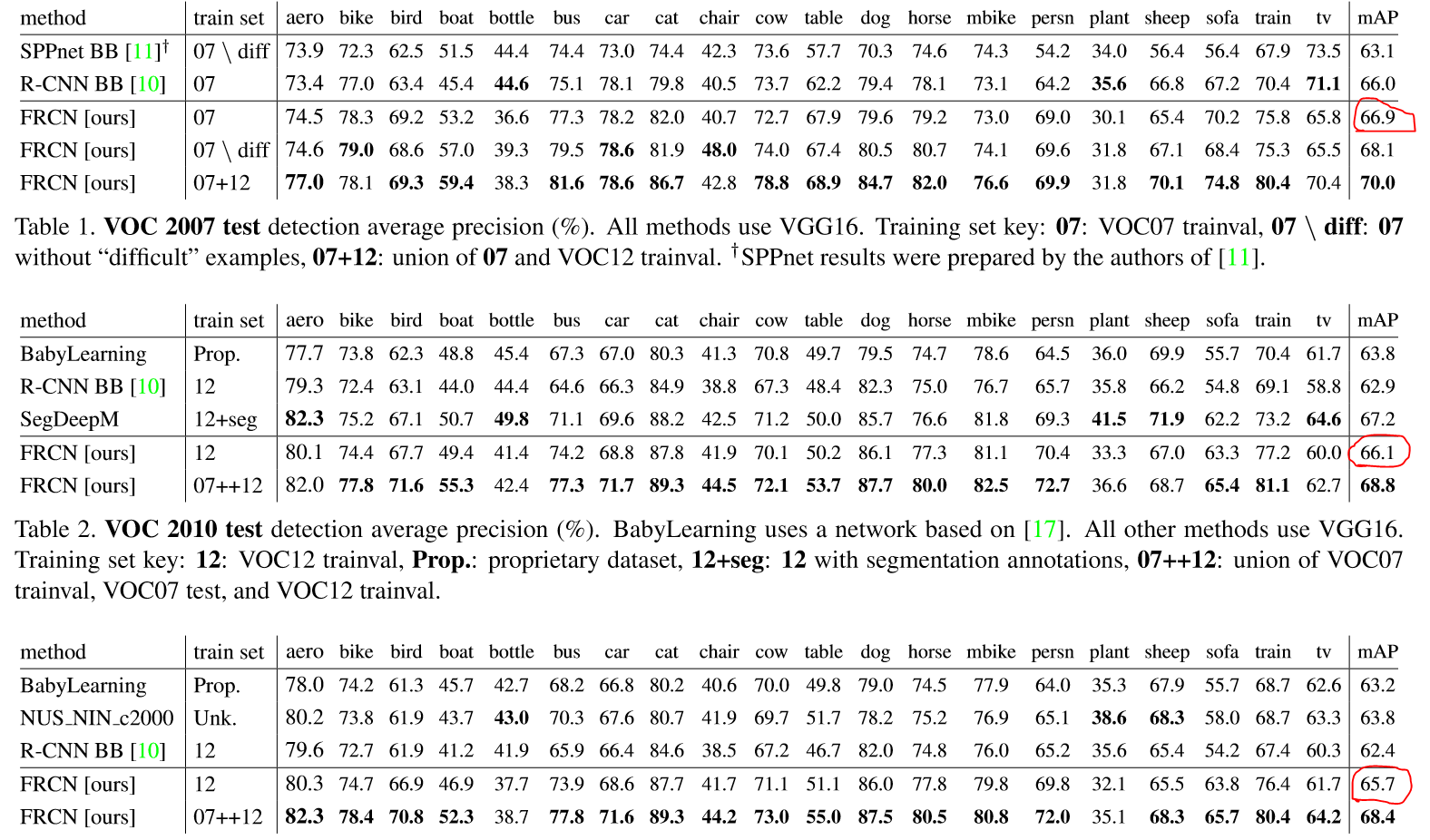
2.相比于RCNN和SPPnet更快的训练和测试过程
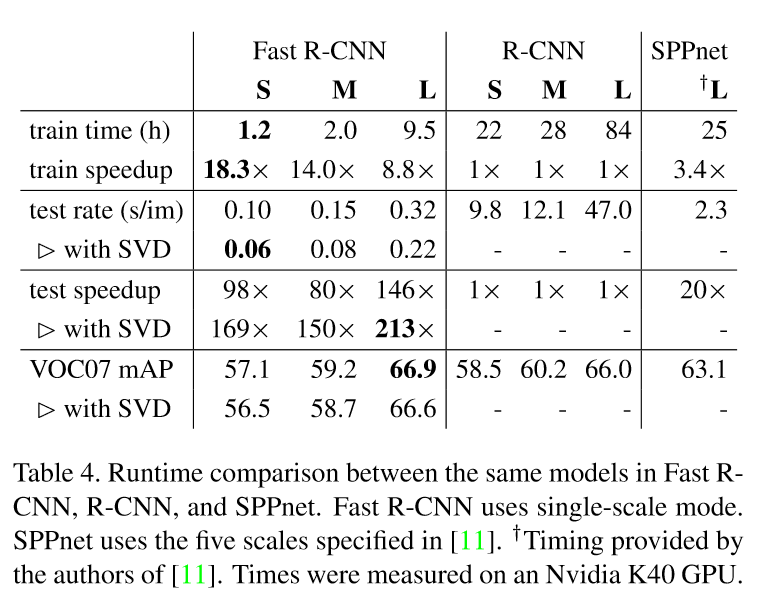
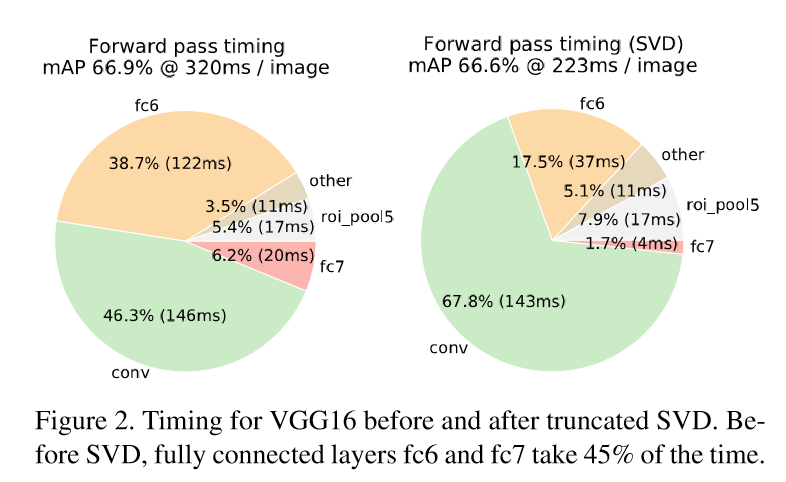
3.在VGG16上微调卷积层提高了mAP

但作者认为对于很深的网络(如VGG16),不是所有的卷积层都需要微调。因为conv1通常是一般性的,和任务无关的特征(通过可视化可以知道是颜色及边缘信息),所以微调conv1与否对最后的mAP影响不大,但会浪费许多时间。作者发现,微调conv3_1之后的层能得到最大的收益。
5.Design evalution
5.1 多任务训练是否有帮助?
通过对比实验证明确实对提高performance有帮助
5.2 尺度不变性:蛮力还是灵巧?
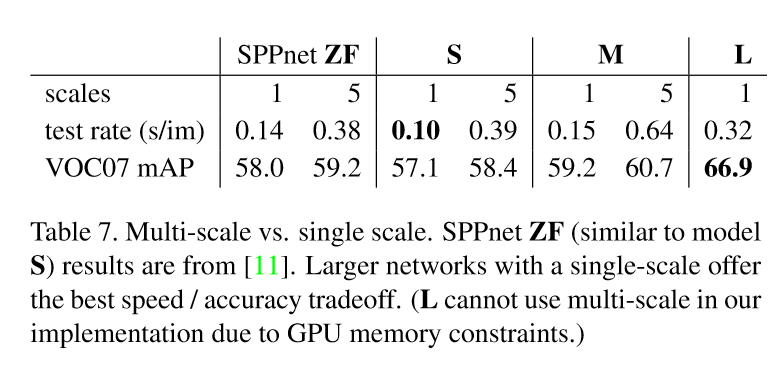
对比实验表明,蛮力方法(single scale)更好,multi-scale只能带来少量的mAP提升,却造成了大量计算时间的增加。这也同时验证了SPPnet中的结果:深度卷积网络善于直接学习尺度不变性
5.3 是否需要更多训练数据?
显然是的。通过将合并VOC07和VOC12,得到了明显的mAP提升(66.9%提升到70.0%),同样的结果在VOC10和VOC12上也观察到了
5.4 SVMs是否比softmax更优秀?
事实说明并非如此
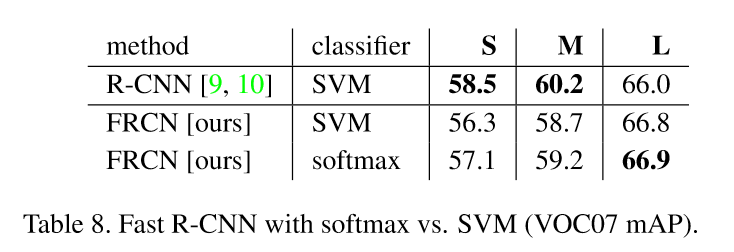
5.5 更多候选区域是否总是更好?
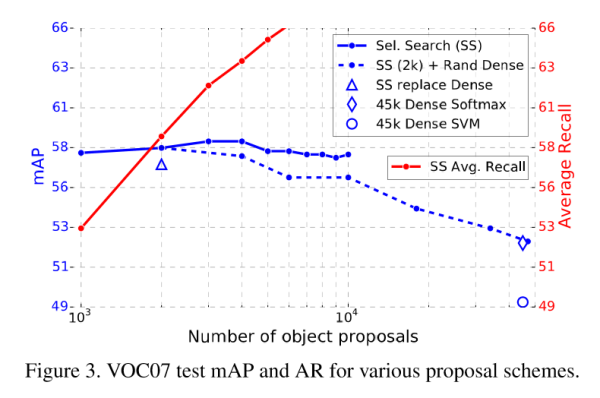
实验结果说明并非如此。这一点不通过实验恐怕很难解释,但似乎稀疏的候选区域结果会更好
二.实践
论文终于解读完了~^_^
下面我们利用开源代码实践一下!
RBG大神的代码开源在这里:GitHub - rbgirshick/fast-rcnn: Fast R-CNN
主要是python代码和c++版本的caffe。对代码结构了解之后,我们可以复现论文中的结果,稍微修改之后,我们也可以在自己的数据集上训练模型。
在windows下配置过程:
1.首先编译caffe.这里我们需要添加roi_pooling_layer和smooth_L1_loss_layer,我们使用happynear的caffe版本中的这两个层参数,首先
git clone https://github.com/happynear/caffe-windows.git
下载这个项目,我们遵循官方添加新层的过程:
1)首先修改src/caffe/proto/caffe.proto文件,添加roi_pooling_layer参数层
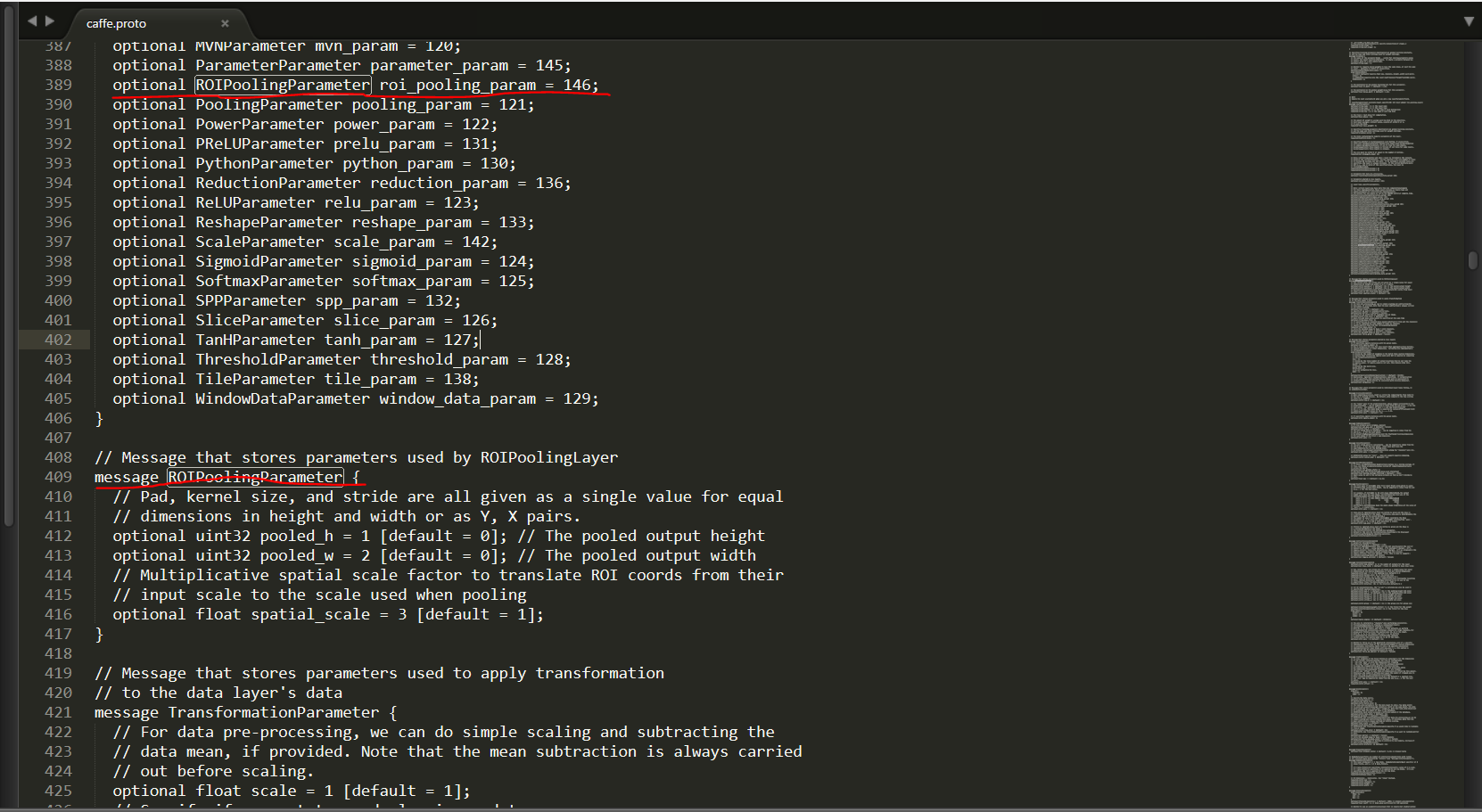
2)将happynear版本下的roi_pooling_layer.cpp(cu)和smooth_L1_loss_layer.cpp(cu)四个文件拷贝到我们的caffe-windows中src/caffe/layers/下,并将include/caffe/下的custom_layers.hpp对应copy过来
3)在VS2013的libcaffe对应文件夹下添加这几个文件,然后编译即可,请预先编译pycaffe,因为马上就会用到
2.然后使用
git clone --recursive https://github.com/rbgirshick/fast-rcnn.git
将fast-rcnn项目克隆到本地
3.为测试demo和我们自己的数据,我们需要下载已经预训练好的fast-rcnn模型,可以直接使用<frcn-root>/data/scripts/fetch_fast_rcnn_models.sh,但需要在windows下配置wget,而且下载速度比较慢,所有我直接从happynear分享出的云盘上下载的:frcn-models,下载完成后,将fast_rcnn_models文件夹拷贝到<frcn-root>/data文件夹下即可
4.我使用的是Anaconda2,cython已经默认装好了,只需要安装easydict即可
pip install easydict
5.将前面第一步编译好的caffe python接口下的内容复制到<frcn-root>/caffe-fast-rcnn/python文件夹下,覆盖原有的内容
6.用文本编辑器打开<frcn-root>/lib/utils/nms.pyx,将第25行的np.int_t修改为np.intp_t
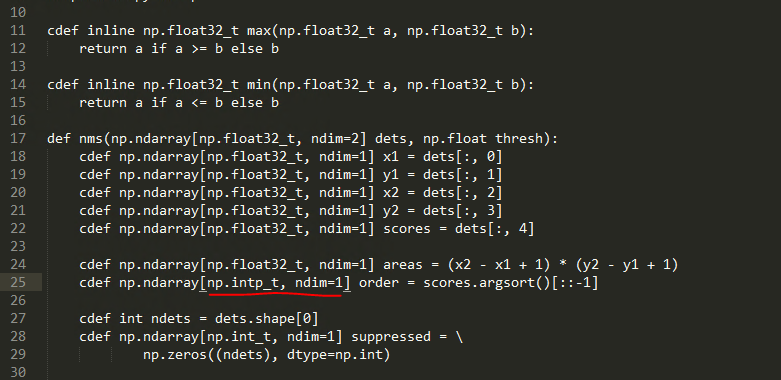
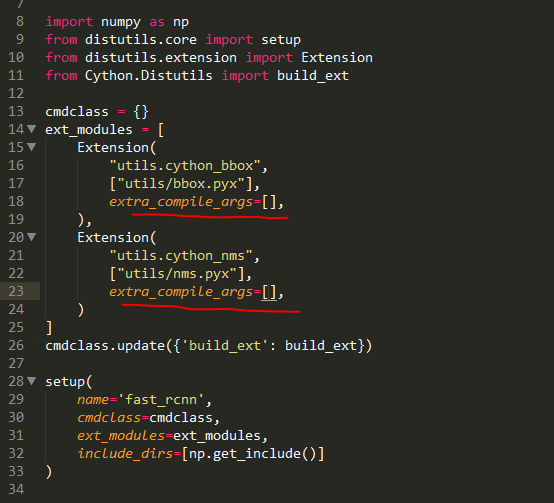
7.用文本编辑器打开<frcn-root>/lib/setup.py,将第18行和23行的
"-Wno-cpp", "-Wno-unused-function"指令删除,只留下空的中括号[]即可
8.打开cmd,首先定位至<frcn-root>/lib目录下,然后输入
python setup.py install
如果提示Unable to find vcvarsall.bat的话,请输入以下指令:
SET VS90COMNTOOLS=%VS120COMNTOOLS%
setup.py安装完成后,到python_root/Lib/site-packages/utils中可以找到两个文件cython_bbox.pyd和cython_nms.pyd,把这两个文件复制到<frcn-root>/lib/utils中

9.好了,接下来我们测试demo吧,在<frcn-root>下:
python tools/demo.py
首先看一下demo的结果图:




运行结果可以看出,第一张图片用时0.966s,第二张图片用时0.408s,如果使用SVD压缩的话,处理每张图片大约只需要0.3s,基本上已经达到了实时的要求!
注:demo的配置部分已经补齐,后面会添加ROI层的解释!
三.后续
faster-rcnn通过添加RPN(Region Proposal Network)来替代传统的提取候选区域方法,并通过Anchor来解决尺度不变性问题!使得基于proposal的目标检测方法几乎已经发展到最好!















 166
166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









