









1、Hadoop有三种配置模式,分别为独立模式、伪分布式模式、分布式模式。
独立模式:即本地模式,该模式没有运行的守护程序,所有的程序运行在一个jvm中。适合开发期间运行MapReduce程序,源于他的易于测试和调试。
伪分布式模式:守护程序运行在本地主机,模拟一个小规模集群。
分布式模式:守护程序运行在多个主机的集群上。
2、安装SSH、配置SSH无密码登陆。
在伪分布式模式下,必须启动守护进程,因此我们需要安装SSH脚本。
Hadoop实际上并不区分伪分布式模式和分布式模式;它只是启动守护进程的集合
主机集群中通过ssh主机和开始守护进程。伪分布式模式是完全分布式模式的一个特例(单个主机),所以我们需要确保我们可以SSH本地主机和无需输入密码登录。
(1)安装
sudo apt-get install openssh-server
(2)配置密钥,-t指定算法(rsa算法);-P,指定密码;-f指定存放密钥的文件名称。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
(3)进入.ssh目录。会有两个文件。其中id_rsa为私钥,id_rsa.pub为公钥。把公钥放在授权认证的文件里面去。
cat id_rsa.pub >> authorized_keys
(4)登录ssh,测试你可以登录。第一次登录会提示确认连接,之后该提示则会消失。
ssh localhost
3、配置。
基本概念:nameNode:名称节点,只存放文件目录。 dataNode:数据节点,存放数据。secondaryNameNode:辅助节点,节点的备份,replication:数据副本(数据备份)。
(1)配置core-site.xml文件,配置nameNode名称节点的位置。
<!-- core-site.xml -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost/</value>
</property>
</configuration>(2)配置hdfs-site.xml文件,配置副本数量。
<!-- hdfs-site.xml -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>(3)配置mapred-site.xml文件,配置mapreduce框架指定yarn
<!-- mapred-site.xml -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(4)配置yarn-site.xml文件,配置资源管理器。节点管理器。
<!-- yarn-site.xml -->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>4、使用HDFS文件系统。
(1)对文件系统进行格式化。
hdfs namenode -format
(2)启动dfs守护进程,
start-dfs.sh --config $HADOOP_INSTALL/etc/hadoop_pseudo
注:config之后是文章上面配置的xml文件目录。
(3)启动yarn的mapreduce框架。
start-yarn.sh --config $HADOOP_INSTALL/etc/hadoop_pseudo
注:config之后是文章上面配置的xml文件目录。
5、创建用户目录
(1)为了方便以后使用,这里配置一个环境变量HADOOP_CONF_DIR
export HADOOP_CONF_DIR=./
注:‘./’代表配置的xml文件目录。
(2)创建用户目录
hadoop fs -mkdir /user/
6、简单应用
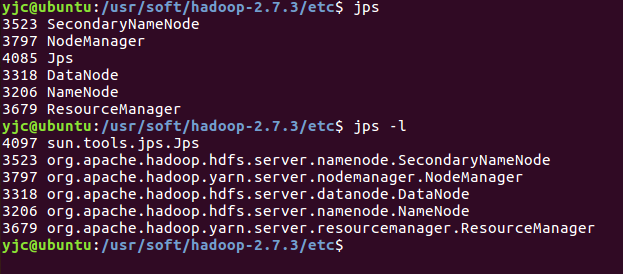
(1)通过jps/jps -l查看启动的进程。
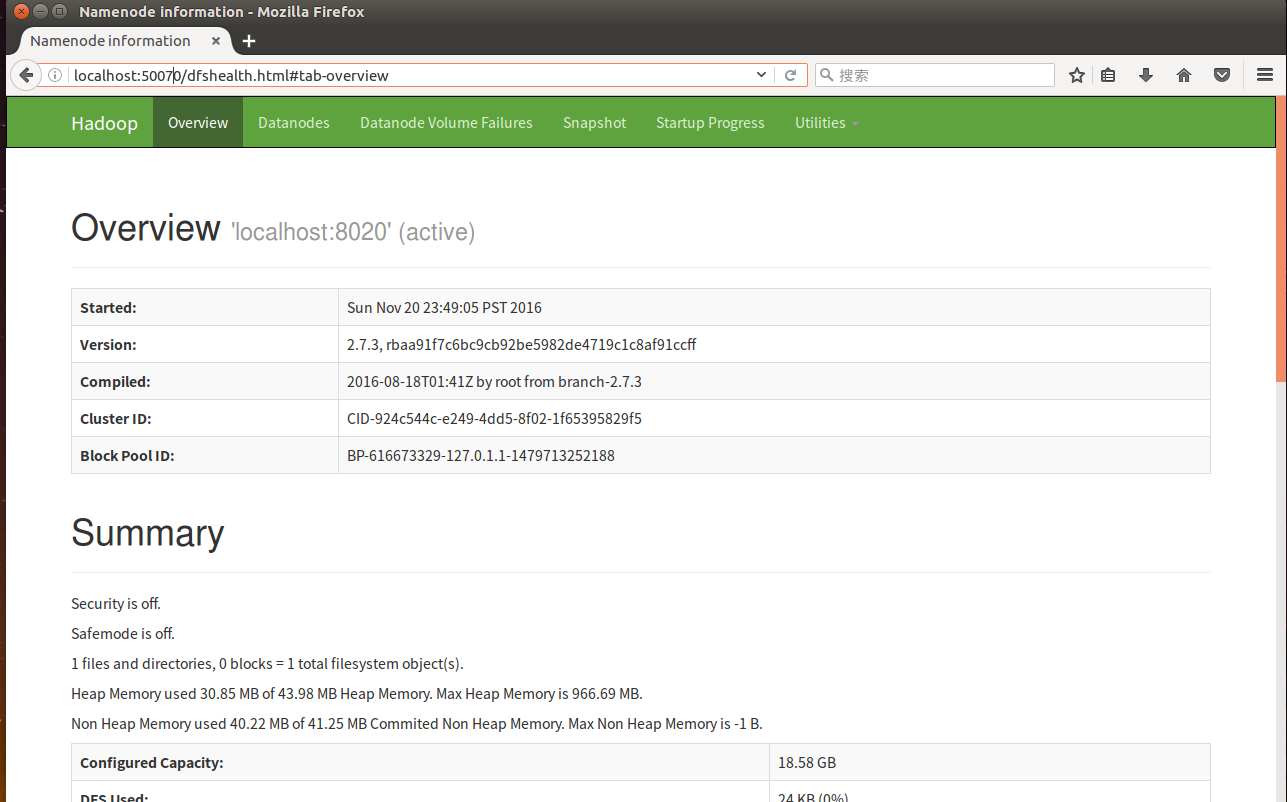
(2)通过web页面访问查询。
http://localhost:50070,查看名称节点。
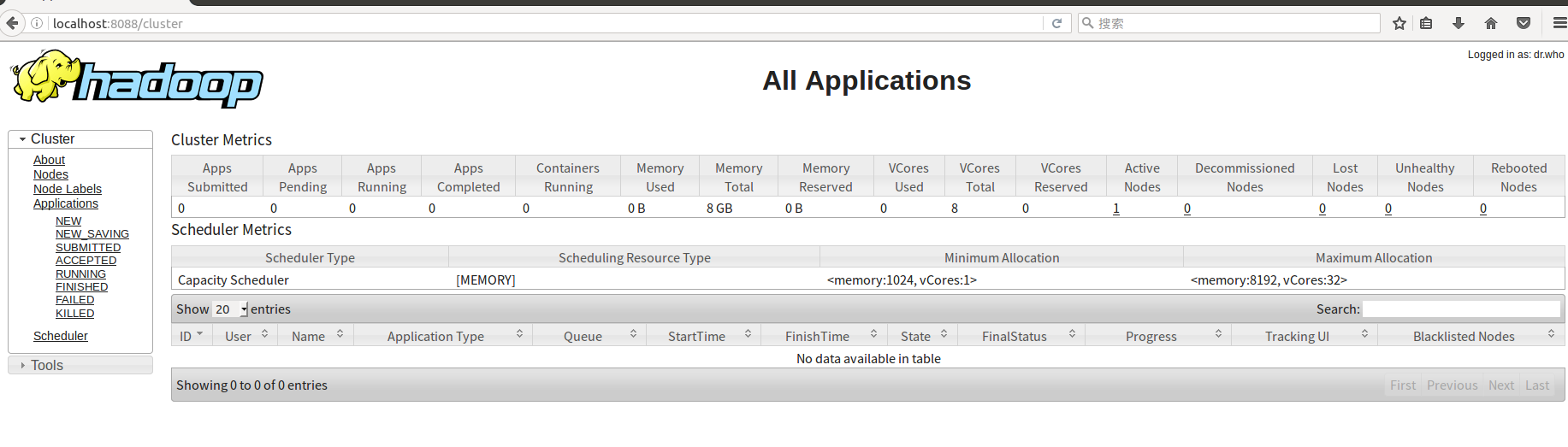
http://localhost:19888,查询资源管理器节点。
(3)查看文件目录信息
hadoop fs -ls /

7、停止服务
(1)停止yarn的mapreduce框架
stop-yarn.sh
(2)停止dfs守护进程
stop-dfs.sh
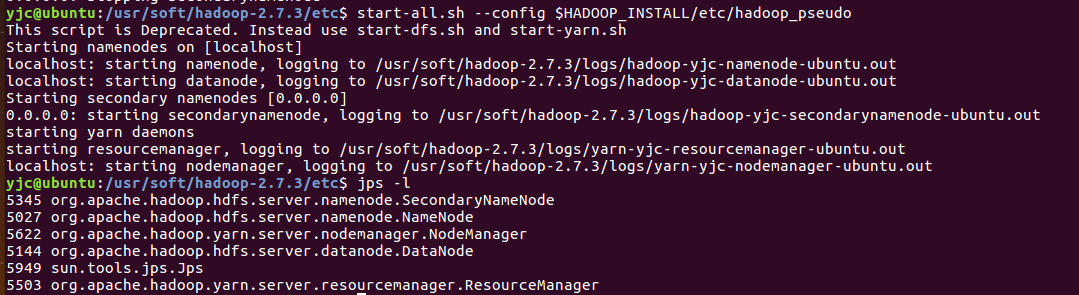
8、Hadoop提供了一个start-all.sh –config $HADOOP_INSTALL/etc/hadoop_pseudo,可以同时启动之前的进程。















 114
114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









