







1.串匹配问题
pattern:模式串
text:文本串
在文本串中找到与模式串相匹配的位置。

2.蛮力算法
两种不同实现,都是从文本串的头开始匹配,失败模式串向后移动一格继续匹配。最坏O(n*m)。第一个返回的如果是大于n-m,则匹配失败。第二个如果返回n-m+1也是匹配失败。


3.KMP算法
利用经验的算法:主要思路是,在一次比对中,如果给定比对失败的位置,那么前面的比对成功的值是确定的,因此只根据模式串就可以预先构筑出一个表,表中记录下一个要比较的j值,即next[j],i值不用回退(和第一种蛮力算法比较),这个next[j],一定小于j,当j=0时,next[0]=-1,仿佛是P[-1]与T [i]在进行下一次比较,可以认为这个值始终相等,那么i++,j++,其实实际上是P[0]与T[i+1]比较,符合应该进行的操作。构造next[]表的思路:要确定next[j+1]等于多少,如果p(j)=p(next[j]),那么next[j+1]=next[j]+1,如果不相等,比较怕P(j)与P(next[next[j]]),如果相等,则next[j+1]=next[next[j]]+1,如此迭代,如果知道P(j)=P(-1)才相等,那么next[j+1]=0,也符合规律。构造表需要O(m)时间。
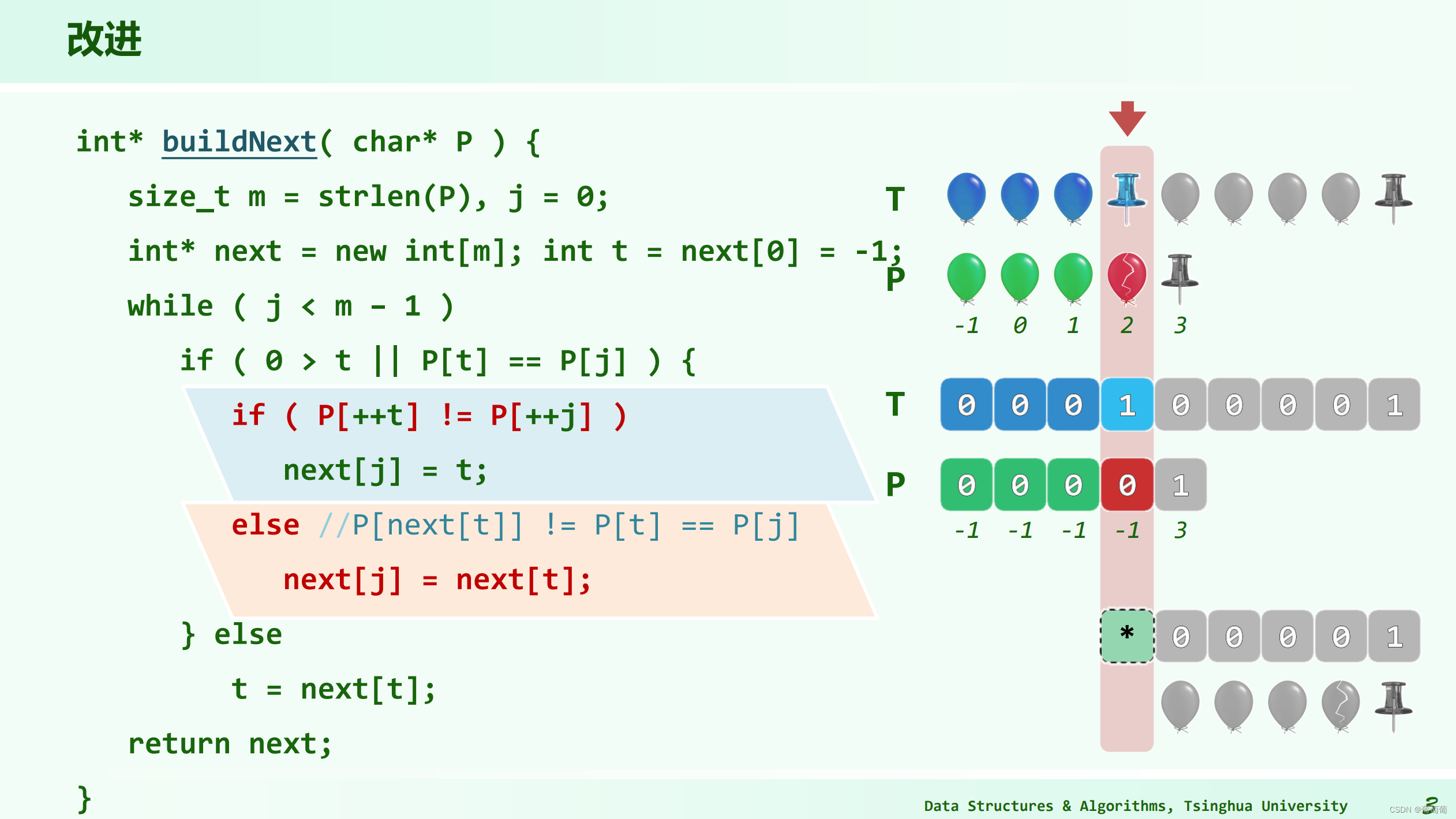
可以还有改进的next表,之前的next[j]充分利用j前面已经成功匹配的信息,其实还可以考虑失败的信息,即T[i]一定不等于P[j],所以next[j]除了前面的要匹配外,P(next[j])还不能等与P[j]相等。分析改进版和第一版的区别,其实可以发现,t依然是j的next[j](不考虑P(next[j])还不能等与P[j]相等的情况),如果要考虑新的条件,next[j]要等于next[t],因为p(next[t])一定不等于p(t),从而不等于P[j]。
时间复杂度分析:最坏O(n)。按照最坏的时间考虑,要i增长到n时,程序结束。花费时间主要是在比较上,比较可以分为两部分,Ti与Pj相等和Ti与Pj不等。相等的部分一定时O(n),因为相等i就前进一步,路途的距离不过是n。不等的时间呢?可以注意到不等的时候j跳转奥next[j],不断变小,到j=-1时,i一定会前进一步。因此不等的时间会等于j变小的次数,因为j的增长来源是i的增长,所以总的增长不过n,因此总的减少也不过n(况且每一次减少可能不止1点),因此不等的比较次数也是O(n),因此总的时间O(n)。整个过程可以这么理解:一只蜗牛要走n米的路程,是走1m需要一单位时间,会积累一点劳累值(j),停留一单位时间可以至少减少1点劳累值,劳累值到达-1休息饱了一定会向前走。整个过程结束要么是劳累过度gg(j值达到m),或者是到达终点(i值达到n)。要时间尽可能长,那么应该是要到达终点。分析总时间主要花费在走路和休息上,走路的时间不过O(n),休息的时间也不过O(n)。加上构造表的时间,一共O(n+m)。(也可以把模式串p看成小车不断向前移动)


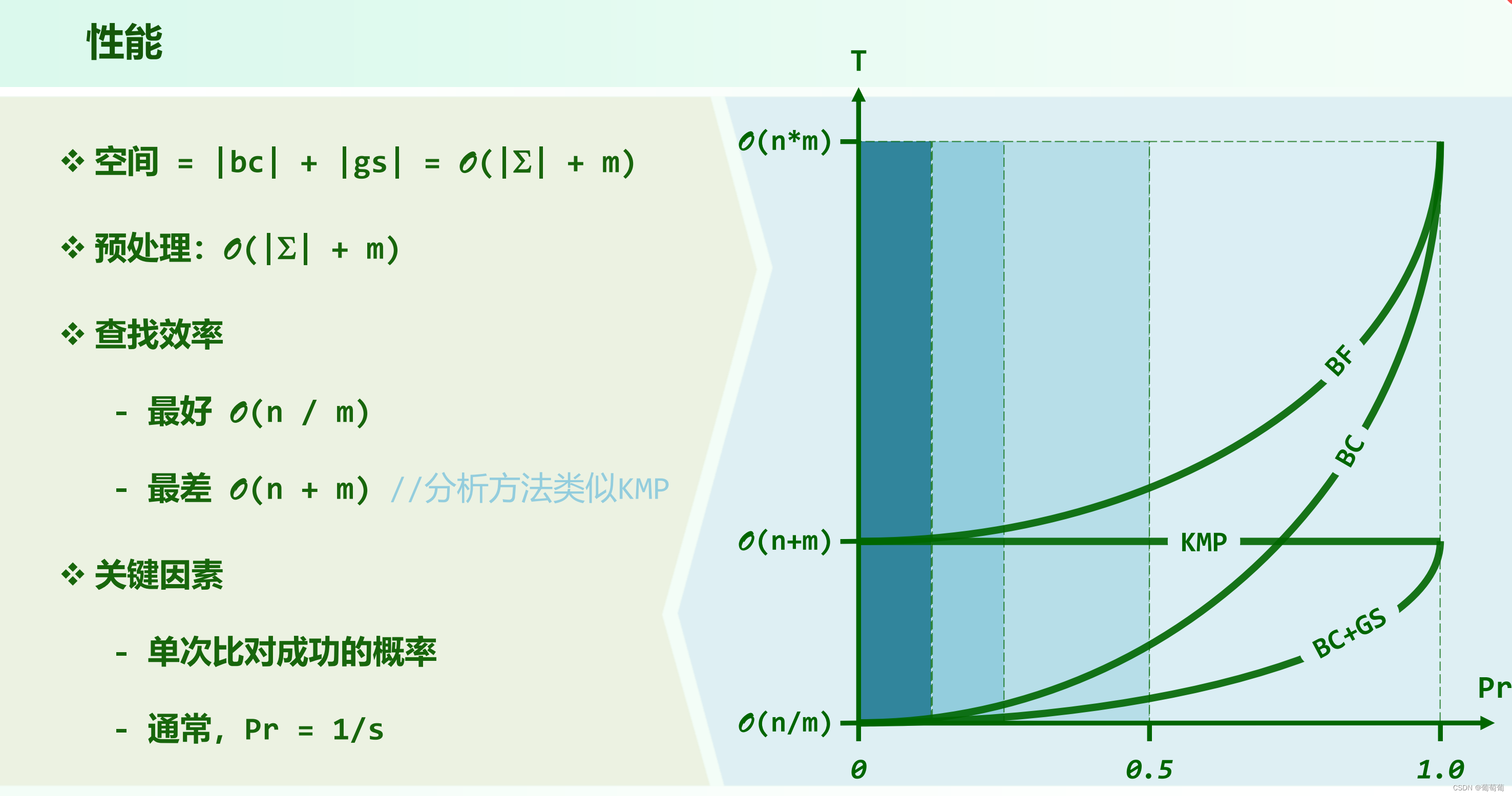
想要充分利用以往对比的信息,那就要一次尽可能匹配多一点长度,从概率上看n/(s^m),如果k小的话匹配的长度可能多一些,所以比较适合s(字符集数量)小的。
4.BM算法
从P的末端开始扫描比较。蛮力算法与前面第一版的蛮力算法相比,只需i--,j--,循环结束条件j=-1或者是i=n,同时也有回退和复位。
bc策略(bad character):构建bc表,表长度是字符集数量,记录每个字符在模式串P中出现的最后的位置。如果匹配失败,调用bc策略的过程就是根据文本串的坏字符是什么,查序bc表,如果值小于当前位置j,那么可以用该值作为继任进行比较。这种适合容易出现比较失败的场景(例如字符集很大),因为这样一方面匹配失败的j值会很大,然后bc表中的值可能会很小,这样可以前进一大步,效率很高。如果字符集小的话效率就反过来了很低。坏字符策略为什么要适合从末端开始 扫描呢?如前所述,bc策略效率高的场景是匹配失败概率较大的时候,如果你从头开始扫描,很容易就在前面就遇到坏字符,这样其实能移动的距离很小。所以bc策略适用于从末端扫描。
gs策略(good suffix):
好后缀有点像KMP中的利用经验和教训,不同的是,KMP中只有在尾端(j接近m)时模式串才有可能移动接近m的距离,而BM好后缀中,无论j匹配失败在哪个位置,都有可能达到m的位移量,因为在BM中,后继的极限不是0,可能是j-m(这后继是在KMP的语境下,从头到尾进行比较,其实在BM里是从末端比较,后面这些根本不需要比较,也就没有什么如果是负数就定义为和所有的值相等),即有了m的位移量。产生这种现象的原因是前者是从头到尾进行扫描,无法知道文本串T在j后面的情况,所以最多只能移动j;而后者从末端开始扫描,文本串T在j后面的是清楚的。
gs表记录的是模式串移动的距离(和KMP算法不一样,next表记录的是下一继任的位置),gs[m-1]=1,其他的取值为[1,m],如果取的值大于j,说明P部分前缀等于后缀(值取j+1后缀是整个P[j+1,m-1],其他的值是其一部分),如果取值小于等于j,说明p中间有一段完全匹配P[j+1,m-1]。确定一个gs[j]的思路是,从小到大从1到m逐渐尝试,如前面所诉,1到j+1需要完全匹配,j+1到m只需要匹配P[j+1,m-1]的部分后缀,从小到大遇到合适的就停下来。
构造gs表:首先构造ss表,ss[j]表示的是从P[j]往前与P[m-1]往前匹配的最大的长度,ss[m-1]=m,其他的值[0,j+1]。由ss表怎么得到gs表?注意到如果ss[j]=j+1,那么m-1-j是所有gs[j]的候选;ss[j]<j+1,那么m-1-j是j>=m-1-ss[j]的gs[j]的候选。所以可以将gs表先初始化,值全是m,然后从后往前依次访问ss表,根据不同取值更新gs表(因为是从后往前,所以前面赋值的一定更小,所以不需要比大小,只需要判断有没有赋值过,即是否等于m)。至于构造ss表,蛮力算法O(m^2),有O(m)的算法。(待会学习)
bc策略可以冲上限(n/m),gs策略可以保下限(n+m)。gs策略保下限O(n+m)的分析和KMP很相似,关键要注意到每次比较可以跳过一些已经成功比对的段落。这个可以以P作为小车来分析,其充满油之后必定会向前走(不然再充就爆炸),充油的过程可以类比为从后向前扫描比较,当充到一定量的油向前走时,走多少油就消耗多少(注意之前有的油不一定全部消耗光了),可以知道,向前走的时间O(n),充油的时间也是O(n)。
5、karp-Rabin算法
字符串 -> 数,第一想法是用进制来表示,其实还可以用素数的乘积表示,每个字符串表示相应位置的素数的指数。

当然因为一个字符可以转为数,所有字符串也可转化为一个数(这个数被称为指纹)。字符串的匹配可以转为数是否相等。以ASCII为例,用一个字节8位表示一个字符,那么一个m长度的字符串其实是m个字节,8m位的数表示的,因为一般寄存器64位,所以一次只能比较64位,即需要比较m/8次,O(m)(和前面的比较方式相比,区别在于前面都是一个字符一个字符比较,而这是8个字节8个字节比较,但是只是常数上优化,一次比较还是要O(m)),总体比较也还要O(n*m)的时间。
通过hash可以将指纹压缩,压缩后的指纹只需O(1)比较时间,但是压缩的过程需要O(m)时间*n,还是O(1)*n时间?



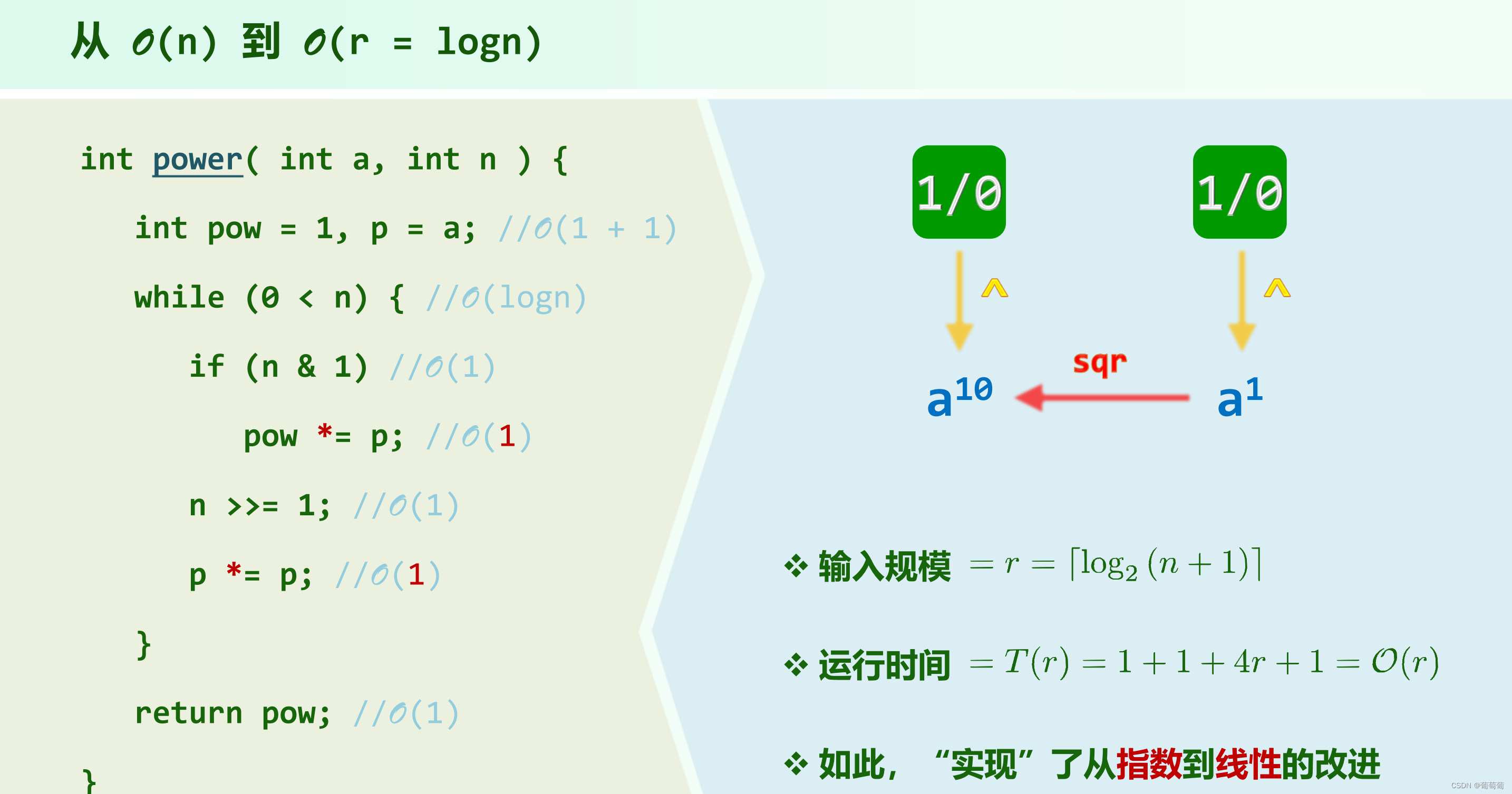
两个不同算法计算a^n,一个是n--,需要O(n),一个是根据位数,一次迭代位向前进1,只要O(logn),但是a^n打印都需要O(n),为什么会有悖论?

6、Trie 键树
储存一系列字符串时,如果字符集比较小,那么很多字符串会有共同前缀,利用这种方式的可以节省空间。
















 2391
2391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









