







1.其实数据结构是问题导向的,栈和队列都只是向量或者列表的一种特例,是它的子集,为什么要单独实现呢?因为用这种数据结构能高效地实现一些对问题解决,把这封装成一种数据结构便于使用和操作,数据结构和解决问题地方法是紧紧联系在一起的。
2.树的定义等
这方面需要结合离散数学的知识来进一步认识。这里主要应用的是指定一个节点为根的有根树。
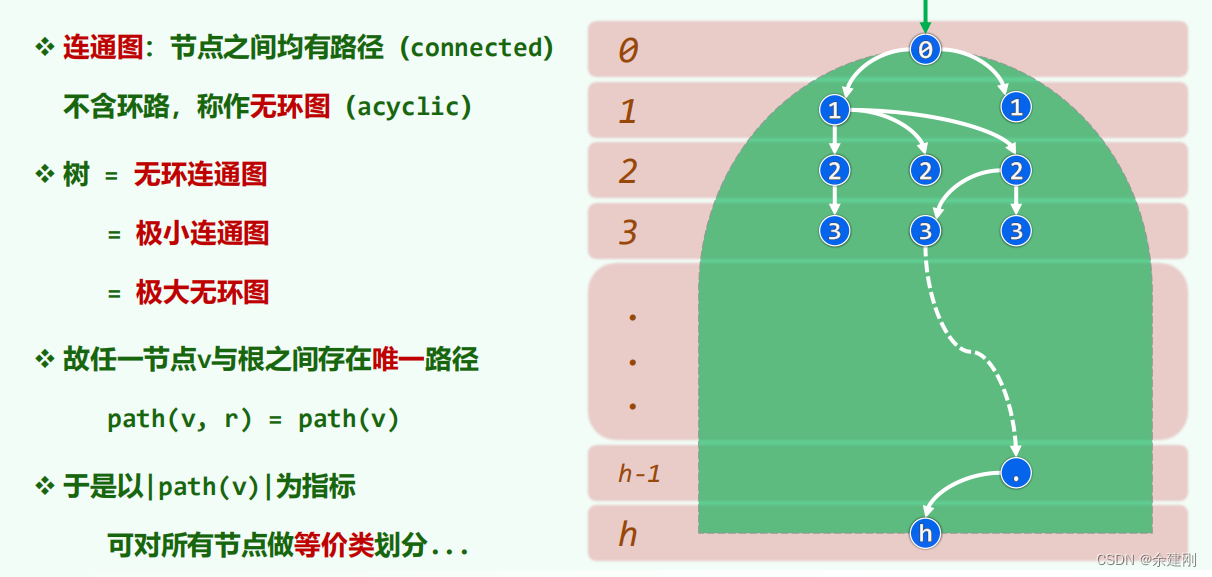
3.二叉树
多叉树和二叉树都是有根有序树(有序是指孩子可以排序,例如二叉树只有一个孩子也要区分是左还是右),多叉树可以转化为二叉树。用长子-兄弟法可以将多叉树转化为唯一的二叉树,虽然两棵树不同构,但是一一对应。(多叉树多叉在于孩子,一个节点与祖先有线相连,与孩子线可能超过两根,长子兄弟表示法同样是一根与祖先或兄弟相连,其他两根一根和长子连,一根和紧邻的兄弟连,只有两根(这也是有序性的体现))
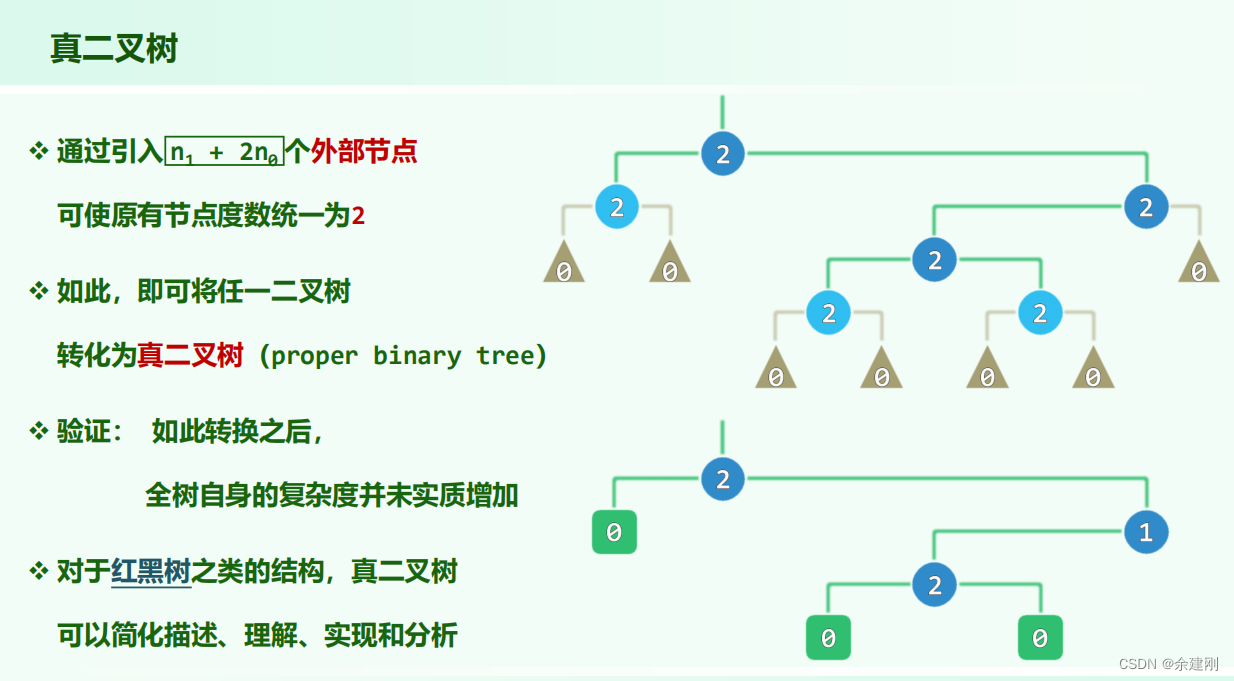
真二叉树(除叶节点外其他节点出度都为2),引入的节点数等于原先节点数加1。
4.BinNode模板类
成员变量包括父亲节点、左孩子节点、右孩子节点位置(BinNode指针),以及T类型数据,这四个与列表的ListNode基本一致,除此之外,还有高度、npl(Null Path Length(左式堆,也可直接用height代替))、红黑树中的颜色等属性值。主要的接口有子树规模(规模用size()用函数表示,可以递归实现),插入左孩子,插入右孩子(这个和列表节点插入前驱,插入后继一致,在这个节点进行插入,因此是节点的接口),以及该节点子树的各种遍历接口和比较器判等器(很多类都要有,特别是这种容器),该节点的直接后继(中序遍历意义下:因为二叉树不是线性序列,后继一定要指定按照什么规则)。
构造函数方面还是要注意其是在堆区中开辟的数据,这样才不会轻易的被清除。同时在删除节点的时候也要注意release data中的指针指向的内存。(不仅要把node节点内存释放,还有把数据内存释放)
#define用宏可以表示一些节点的状态,如:()里面的是节点类型数据

5.BinTree模板类
成员变量有规模和根节点(很简洁,列表的都有规模以及头尾两哨兵节点)
私有接口有更新节点高度(这个完全可以放到节点类中)、更新节点及祖先的高度(一般这是插入操作后使用),公共接口有插入左孩子右孩子(直接调用节点类的插入即可)(并没有蹩脚的插入父亲) ,接入左子树右子树(attach)(默认左孩子或右孩子为空),子树删除以及子树分离等,还有就是遍历等接口(直接对根节点调用遍历接口即可)
删除一棵树包括三个层次:首先是树的空间(一个size 一个节点指针),其次是树中的各个节点空间(属性、地址、数据地址等等)、最后是数据空间。后两个可以用removeat(_root)函数来实现(递归的释放空间)
6.二叉树的遍历
所谓的遍历,其实将储存在树中的数据按照线性的序列展现出来
先序遍历:首先可以用递归简明的实现。但空间复杂度不好控制(与高度h相关?)。用迭代版其实只能在常数时间获得空间复杂度优化。
中序遍历:也可以用递归简明的实现。迭代版用栈也可以实现,但可以有不需要栈的版本,空间复杂度控制在O(1)而不是O(h)(迭代四版本)。
后序遍历:remove at函数是删除包括该节点的子树(包括数据和节点),删除节点的顺序就是后续遍历,先删除子树再删除节点。同样可以用递归简明实现 ,也可改进为迭代法。
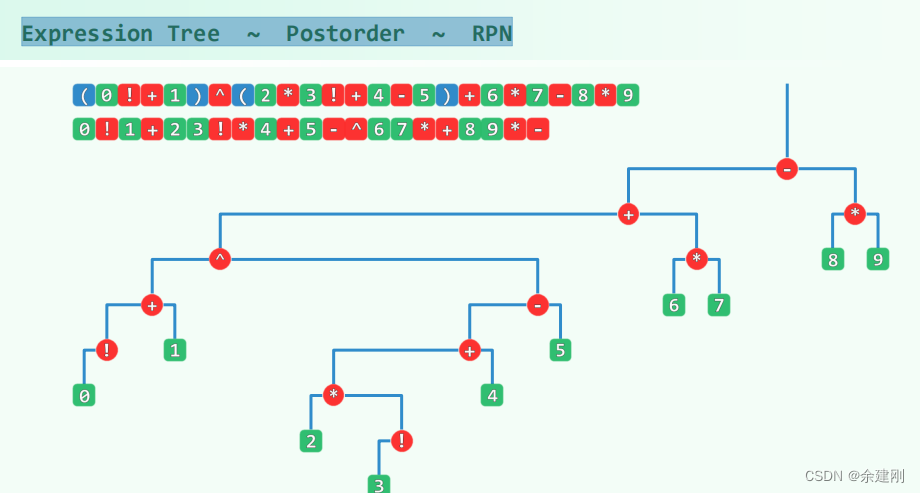
后序遍历和表达式树与RPN的关系:表达式树的后序遍历就是逆波兰表达式
逆波兰表达式是一个线性序列,按照这个线性序列可以完成运算,表达式树不是线性序列,但是其后序遍历是一个序列,正好是逆波兰表达式
层次遍历:用队列实现。用队列可以优美的解决,O(n)的时间复杂度和空间复杂度。
7.霍夫曼编码树
编码:将字符用二进制数来表示
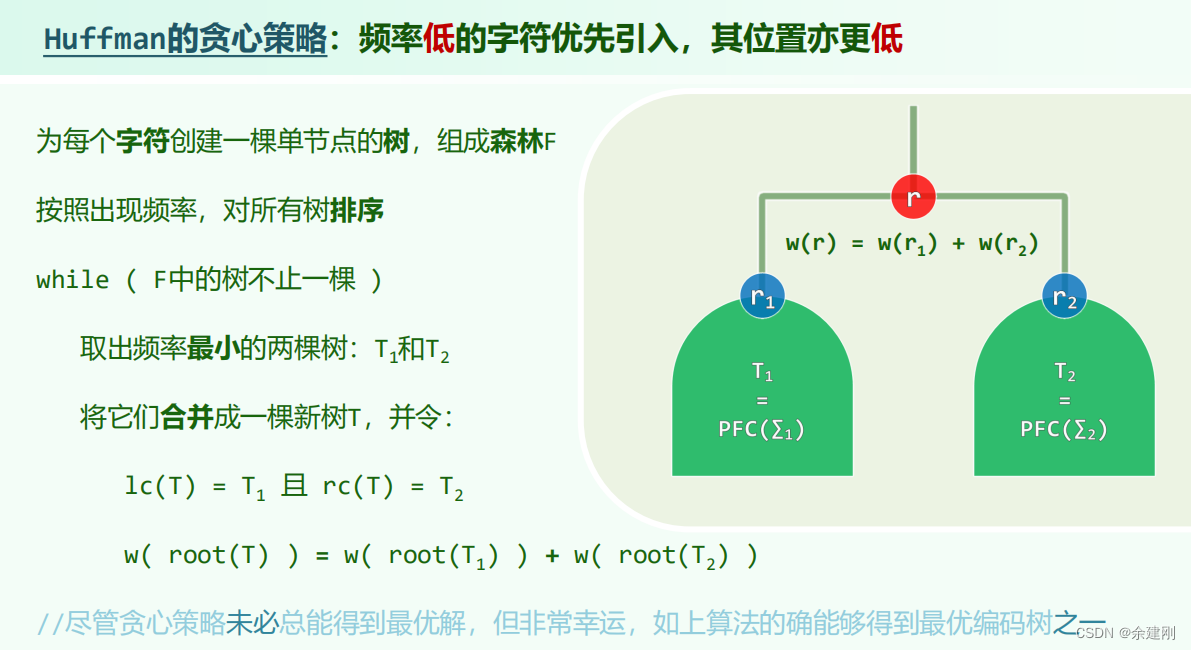
如何证明霍夫曼编码的正确性:数学归纳法——假设对于n-1字符的个霍夫曼编码是最优编码,那么对于n个字符,引入一个新的字符频率等于频率最小的两个的字符的频率相加,这n-1个字符用霍夫曼编码,由假设知其是最优编码,对这棵霍夫曼最优编码树进行处理,将新字符的叶子节点向下延伸,接上频率最小的两个字符,那么新得到的树一定是n个字符的最优编码树(反证法,假设不是最优,那么最优的的树去掉两个频率最低的节点并将这两个节点的父亲节点替换成新字符节点,那这棵树比之前n-1的霍夫曼树更优,与假设相悖),而这样处理的新树一定是按霍夫曼编码规则生成的树,因此对于n个字符而言,霍夫曼树也是最优树。
总结:二叉树可以用于编码,因为0和1正好和二叉的二对应,编码能与树之间形成一一对应的关系,将数的问题转化为树的问题,这也是二叉树的一个应用。霍夫曼的算法是所谓的贪心算法。
实现算法的过程中,关键是在于如何取出频率最低的那棵树,并将合并的树插入进去,用优先级队列可以实现nlogn的复杂度(logn时间取出最值插入时间也用logn维护即可)。除此之外,用一个栈和队列也可以实现nlogn的复杂度(先进行排序存入栈中,再将最小两个合并的树存入一个队列中,以后取的话只要比较栈顶和队列前段,谁小谁出栈和出队,进行两次比较就可以选择两个最小的,将最小合并的树入队,注意队中的次序一定是得到保障的,不用像普通的序列那样插入的维护,这一点是最重要的,就像消灭西瓜游戏一样,合并的树一定是越来越大(最后霍夫曼树的根节点频率值等于所有字符频率值之和),直接放在队尾是最好的选择),这种是用空间换取了时间,
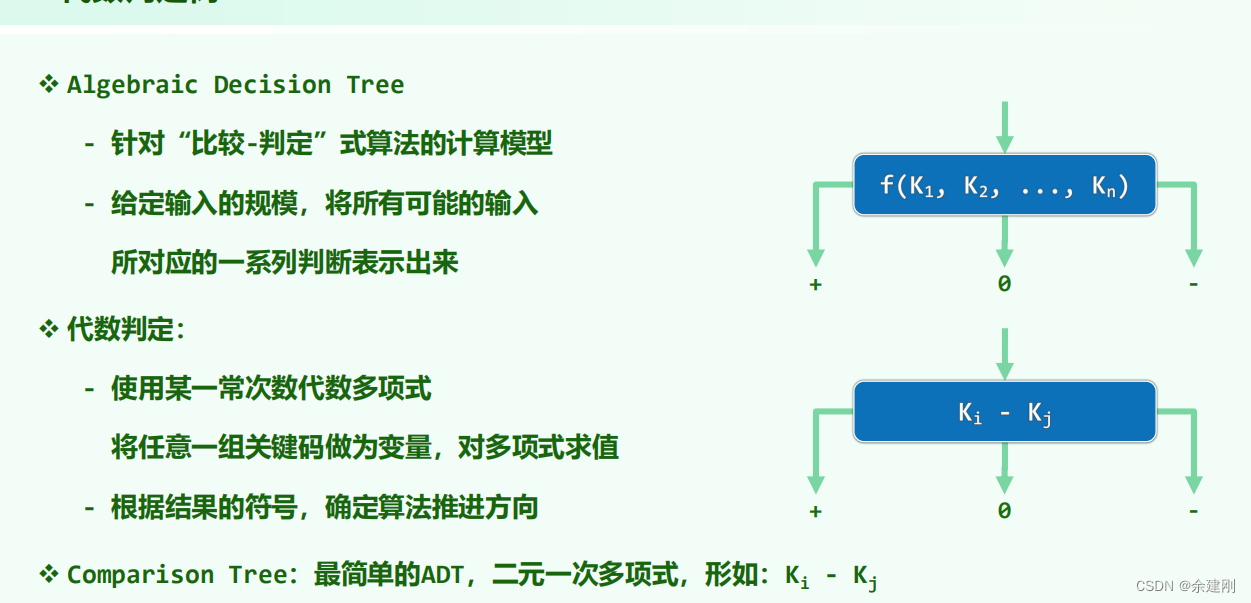
8.代数判定树(Algebraic decision tree)(ADT)
这是研究CBA算法(compare based algorithm)复杂度的工具,ADT是一棵三叉树,每个节点是对任意部分或者全部关键码的代数多项式求值,根据结果往下延申,到最后的叶子节点表示所有的结果。ADT对于n个元素任意输入都有结果,叶子节点包含所有可能输入产生结果。树高表示比较次数最多的一种情况(最坏情况,即时间与n有关还与输入有关,这种是最坏的输入产生的结果)叶子的平均深度表示平均情况,最小深度表示最好情况。
不同的算法的ADT树结构不同(比如有的树高小,但是叶子最小深度即最好情况可能更大)
对于CBA的排序算法(之前所用的排序算法本质上都是比较和调整位置),输入n个数,要有n的阶乘结果,而树高要大于logn!,即最坏的时间复杂度下界是nlogn。(之前复杂度都是分析上界,这个分析指明了CBA排序的下界也是nlogn,没法再优化到更好的了,要更好的可能要跳出CBA这种类型的算法,这个工具指明了问题的一类算法的下界,还有线性规约——(Linear-Time Reduction)工具也可以确定下界,具体没太明白)
















 1086
1086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









