







 1. 简要回顾首先简单复述一下FFmpeg中对深度学习的支持情况,如上图所示,FFmpeg在libavfilter中支持基于深度学习的filter,目前已经支持sr, derain和dnn_processing等filter,其中,dnn_processing是一个通用的filter,涵盖了sr和derain的功能,本文将要介绍的超分辨率(Super Resolution)功能也将使用dnn_processing来完成。为了实现模型推理功能,FFmpeg提供了三种不同的方式(被称为后端backend).
1. 简要回顾首先简单复述一下FFmpeg中对深度学习的支持情况,如上图所示,FFmpeg在libavfilter中支持基于深度学习的filter,目前已经支持sr, derain和dnn_processing等filter,其中,dnn_processing是一个通用的filter,涵盖了sr和derain的功能,本文将要介绍的超分辨率(Super Resolution)功能也将使用dnn_processing来完成。为了实现模型推理功能,FFmpeg提供了三种不同的方式(被称为后端backend).
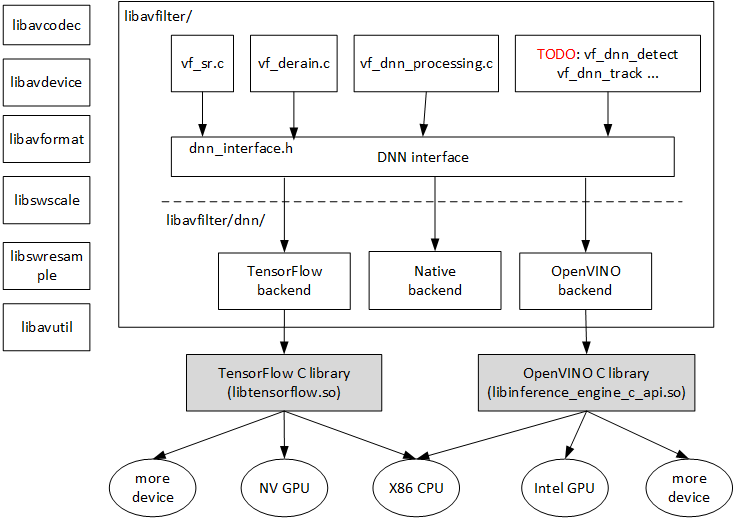
1. 简要回顾
首先简单复述一下FFmpeg中对深度学习的支持情况,如上图所示,FFmpeg在libavfilter中支持基于深度学习的filter,目前已经支持sr, derain和dnn_processing等filter,其中,dnn_processing是一个通用的filter,涵盖了sr和derain的功能,本文将要介绍的超分辨率(Super Resolution)功能也将使用dnn_processing来完成。
为了实现模型推理功能,FFmpeg提供了三种不同的方式(被称为后端backend),分别是native 后端、tensorflow后端和openvino后端。native后端的所有代码实现都在FFmpeg代码树中,目前以C语言的形式存在,可以跑在各种host端CPU上。tensorflow后端是指FFmpeg调用动态库libtensorflow.so进行模型加载和推理,可以跑在x86 cpu、NV GPU等各类计算设备上。openvino后端是指FFmpeg调用动态库libinference_engine_c_api.so进行模型加载和推理,可以跑在x86 cpu、Intel GPU等各类计算设备上。顺便提一下,由于FFmpeg的要求,不能调用C++接口,所以这些动态库都是提供C语言接口的库文件。
另外,在filter和后端之间,设计了一个用来解耦的接口层DNN interface,这样,filter可以很方便的从这个后端切换到另外一个后端,方便FFmpeg的开发者和用户无需修改代码,只需简单修改参数即可无缝切换到不同的计算设备上。
接下来将介绍如何使用tensorflow后端在NV GPU上加速Super Resolution,以及如何使用OpenVINO后端在Intel GPU上加速Super Resolution。
2. 资料准备
Super Resolution最本质上就是对视频图片的放大,在深度学习技术的加持下效果更好。我们采用ESPCN模型(Efficient Sub-Pixel Convolutional Neural Network model),这是论文地址https://arxiv.org/abs/1609.05158。 这个模型的实现非常简洁,用了4层,依次是64个5x5的卷积层,32个3x3的卷积层,4个3x3的卷积层,卷积层的参数都是same,维持feature map尺寸不变;最后一层是depth2space层,将最后的4个feature map转换为长宽都乘以2的一张图片。
所有的模型文件和测试码流都已经放在了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









