









Kimi-VL开源,看技术报告训练操作蛮多的,特此记录下。
模型架构
Kimi-VL模型整体架构框架与前期内容介绍的llava、reyes等多模态大模型的架构大差不差,组成形式:视觉编码器(MoonViT)+ MLP层 + MoE的LLM。
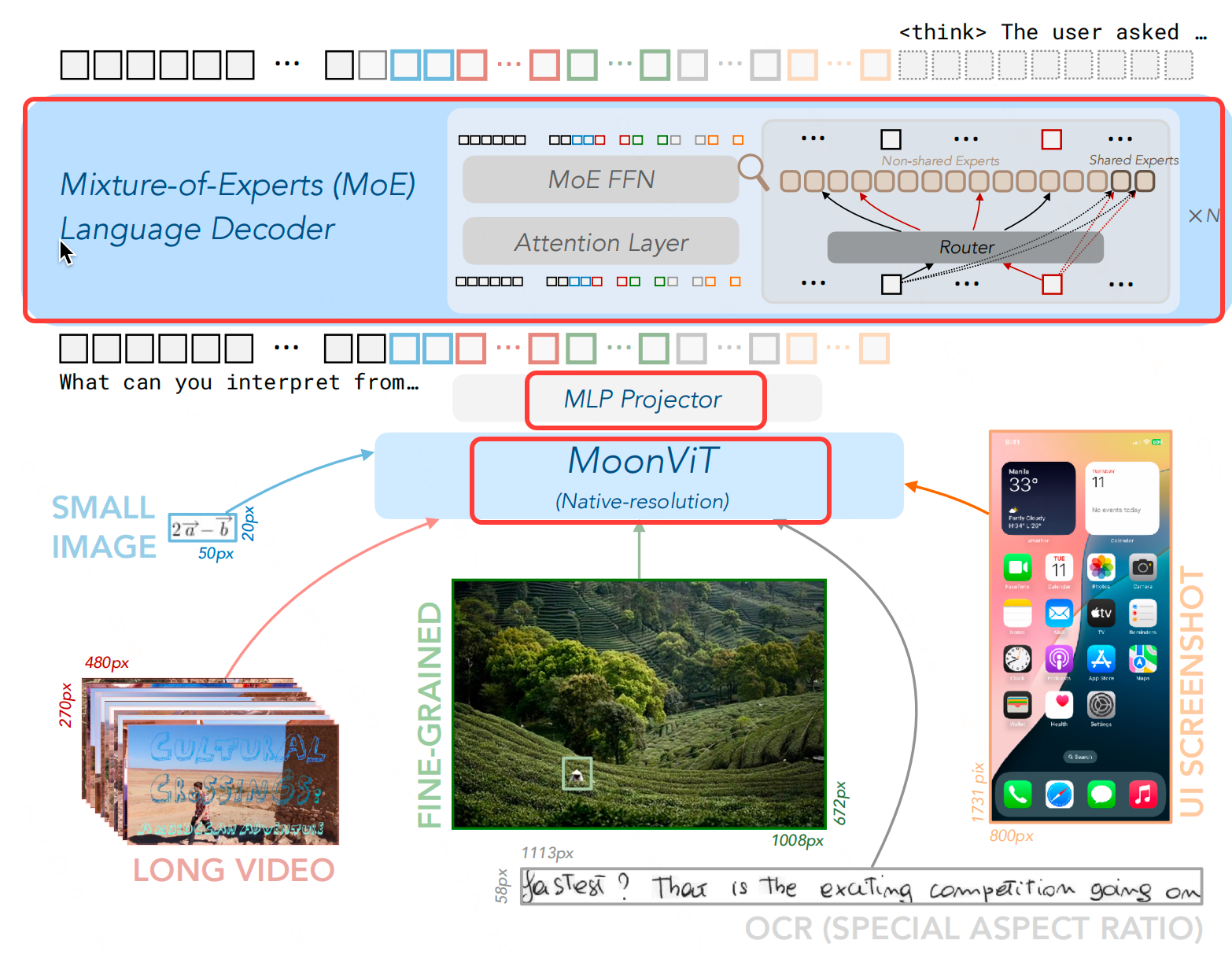
1. MoonViT:视觉编码器
MoonViT的设计目标是能够以图像的原始分辨率处理图像,从而消除复杂的子图像分割和拼接操作。这种设计使得MoonViT能够更灵活地处理不同分辨率的图像,而不需要进行额外的预处理步骤。
实现方式:
-
图像分块和拼接: MoonViT采用NaViT中的打包方法,将图像分割成补丁,展平后顺序连接成一维序列。便于使用FlashAttention进行优化注意力计算。
-
位置编码: MoonViT从SigLIP-SO-400M初始化,并使用插值的位置嵌入来更好地保留SigLIP的能力。然而随着图像分辨率的增加,这些插值的位置嵌入变得不足。为了解决这个问题,MoonViT引入了二维旋转位置嵌入(RoPE),这在高度和宽度维度上改进了对细粒度位置信息的表示,特别是在高分辨率图像中。
-
连续特征输出: 经过处理后,MoonViT输出的连续图像特征被传递到MLP层,对齐LLM的维度。
2. MLP层
MLP层的作用是连接MoonViT和LLM:首先,MLP投影器使用像素重排操作来压缩MoonViT提取的图像特征的空间维度,进行2x2的下采样并相应地扩展通道维度。压缩后的特征随后输入到一个两层MLP中,将其投影到与LLM嵌入相同的维度。
3. 混合专家(MoE)语言模型
Kimi-VL的语言模型基于2.8B激活参数的MoE语言模型-Moonlight模型,总共有16B参数。Moonlight模型从预训练阶段的中间检查点初始化,该检查点已经处理了5.2T个纯文本令牌,并激活了8K的上下文长度。
预训练数据与方法
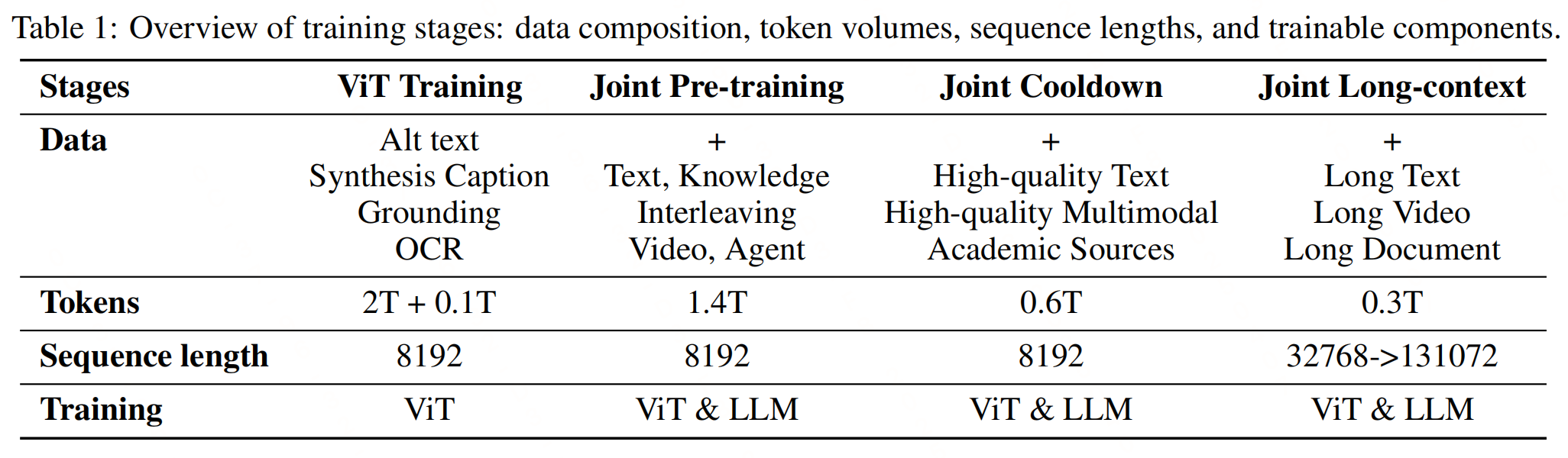
Kimi-VL的预训练搞了四个阶段,每个阶段都有特定的目标和数据集。
总结如下:

| 阶段 | 目标 | 损失函数/数据 | 训练策略 |
|---|---|---|---|
| 训练阶段 | 训练一个能够处理原生分辨率图像的视觉编码器(MoonViT) | 最终损失函数为 L = L s i g l i p + λ L c a p t i o n \mathcal{L} = \mathcal{L}_{siglip} + \lambda \mathcal{L}_{caption} L=Lsiglip+λLcaption,其中 λ = 2 \lambda = 2 λ=2;图像和文本编码器计算对比损失,文本解码器进行条件生成的下一个标记预测(NTP) | 1. 初始化时,使用SigLIP SO-400M的权重,并采用渐进分辨率采样策略来逐步允许更大的尺寸 2. 文本解码器从一个小型的纯解码器模型初始化 |
| 联合预训练阶段 | 通过结合纯文本数据和多模态数据来增强模型的语言和多模态能力 | 纯文本数据和多模态数据 | 继续使用加载的LLM检查点进行训练,消耗额外的1.4T token。初始步骤仅使用语言数据,然后逐渐增加多模态数据的比例 |
| 联合冷却阶段 | 通过高质量的语言和多模态数据进一步确保模型的性能 | 1. 高质量的语言和多模态数据集 2. 语言部分:使用高质量子集数据进行训练,提高数学推理、知识任务和代码生成的能力 3. 多模态部分:使用高质量子集的重放和学术视觉或视觉-语言数据源的过滤和改写 | 1. 通过实验验证,观察到在冷却阶段引入合成数据可以显著提高性能 2. 保持语言和多模态QA对的低比例,以避免过拟合这些QA模式 |
| 联合长上下文激活阶段 | 扩展模型的上下文长度,使其能够处理长文本和多模态输入 | 1. 长文本、长视频和长文档等多模态数据 2. 数据集包括长文本和长多模态数据,以激活模型的长上下文能力 | 1. 将模型的上下文长度从8192(8K)扩展到131072(128K) 2. 通过两个子阶段进行扩展,每个子阶段将模型的上下文长度增加四倍 3. 使用长数据和短数据的混合策略,确保模型在学习长上下文理解的同时保持短上下文能力 |
后训练方法


| 阶段 | 目标 | 技术实现 | 训练策略 |
|---|---|---|---|
| 联合监督微调(SFT) | 通过指令微调来增强模型的指令遵循能力和对话能力,从而创建一个交互式的Kimi-VL模型 | 1. 使用ChatML格式进行指令优化,保持与Kimi-VL架构的一致性 2. 优化语言模型、MLP投影器和视觉编码器,使用纯文本和视觉-语言的微调数据进行训练 3. 监督仅应用于答案和特殊标记,系统提示和用户提示被屏蔽 4. 精心策划的多模态指令-响应对,确保对话角色标记、视觉嵌入的结构注入和跨模态位置关系的保留 | 1. 首先在32k令牌的序列长度上训练1个epoch,然后在128k令牌的序列长度上再训练1个epoch 2. 学习率在第一个阶段从 2 × 1 0 − 5 2 \times 10^{-5} 2×10−5 递减到 2 × 1 0 − 6 2 \times 10^{-6} 2×10−6,然后在第二个阶段重新加热到 1 × 1 0 − 5 1 \times 10^{-5} 1×10−5 并最终递减到 1 × 1 0 − 6 1 \times 10^{-6} 1×10−6 3. 通过将多个训练示例打包到单个训练序列中来提高训练效率 |
| 长链推理(CoT)监督微调 | 通过构建高质量的推理路径数据集来增强模型的长链推理能力 | 1. 使用提示工程构建一个小型但高质量的长链推理预热数据集,包含文本和图像输入的准确验证推理路径 2. 通过轻量级SFT对预热数据进行训练,以激活模型的多模态推理策略 | 1. 通过提示工程生成长链推理路径,类似于拒绝采样(RS),但专注于通过提示工程生成长链推理路径 2. 预热数据集设计用于封装人类推理的关键认知过程,如计划、评估、反思和探索 |
| 强化学习(RL) | 通过强化学习进一步提升模型的推理能力,使其能够自主生成结构化的CoT推理路径 | 1. 采用在线策略镜像下降变体作为RL算法,迭代优化策略模型
π
θ
\pi_{\theta}
πθ 以提高其问题解决准确性 2. 使用相对熵进行正则化,以稳定策略更新 | 1. 在每个训练迭代中,从数据集D中采样一个问题批次,并使用策略梯度更新模型参数到
θ
i
+
1
\theta_{i+1}
θi+1 2. 实施基于长度的奖励来惩罚过长的响应,减少过度思考问题 3. 使用课程采样和优先级采样策略,利用难度标签和实例成功率来优化学习轨迹和提高训练效率 |
数据构建方法
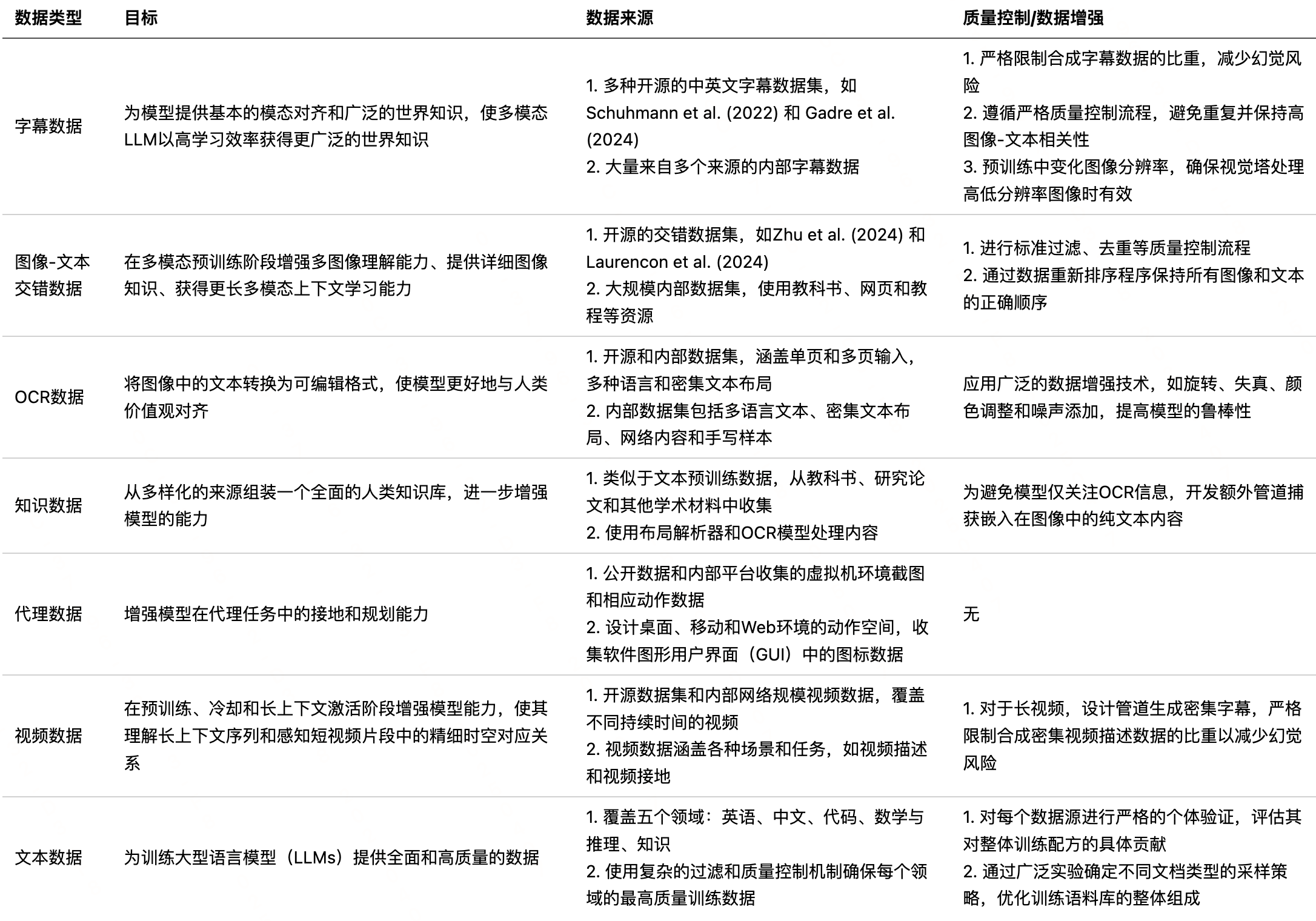
| 数据类型 | 目标 | 数据来源 | 质量控制/数据增强 |
|---|---|---|---|
| 字幕数据 | 为模型提供基本的模态对齐和广泛的世界知识,使多模态LLM以高学习效率获得更广泛的世界知识 | 1. 多种开源的中英文字幕数据集,如Schuhmann et al. (2022) 和 Gadre et al. (2024) 2. 大量来自多个来源的内部字幕数据 | 1. 严格限制合成字幕数据的比重,减少幻觉风险 2. 遵循严格质量控制流程,避免重复并保持高图像-文本相关性 3. 预训练中变化图像分辨率,确保视觉塔处理高低分辨率图像时有效 |
| 图像-文本交错数据 | 在多模态预训练阶段增强多图像理解能力、提供详细图像知识、获得更长多模态上下文学习能力 | 1. 开源的交错数据集,如Zhu et al. (2024) 和 Laurencon et al. (2024) 2. 大规模内部数据集,使用教科书、网页和教程等资源 | 1. 进行标准过滤、去重等质量控制流程 2. 通过数据重新排序程序保持所有图像和文本的正确顺序 |
| OCR数据 | 将图像中的文本转换为可编辑格式,使模型更好地与人类价值观对齐 | 1. 开源和内部数据集,涵盖单页和多页输入,多种语言和密集文本布局 2. 内部数据集包括多语言文本、密集文本布局、网络内容和手写样本 | 应用广泛的数据增强技术,如旋转、失真、颜色调整和噪声添加,提高模型的鲁棒性 |
| 知识数据 | 从多样化的来源组装一个全面的人类知识库,进一步增强模型的能力 | 1. 类似于文本预训练数据,从教科书、研究论文和其他学术材料中收集 2. 使用布局解析器和OCR模型处理内容 | 为避免模型仅关注OCR信息,开发额外管道捕获嵌入在图像中的纯文本内容 |
| 代理数据 | 增强模型在代理任务中的接地和规划能力 | 1. 公开数据和内部平台收集的虚拟机环境截图和相应动作数据 2. 设计桌面、移动和Web环境的动作空间,收集软件图形用户界面(GUI)中的图标数据 | 无 |
| 视频数据 | 在预训练、冷却和长上下文激活阶段增强模型能力,使其理解长上下文序列和感知短视频片段中的精细时空对应关系 | 1. 开源数据集和内部网络规模视频数据,覆盖不同持续时间的视频 2. 视频数据涵盖各种场景和任务,如视频描述和视频接地 | 1. 对于长视频,设计管道生成密集字幕,严格限制合成密集视频描述数据的比重以减少幻觉风险 |
| 文本数据 | 为训练大型语言模型(LLMs)提供全面和高质量的数据 | 1. 覆盖五个领域:英语、中文、代码、数学与推理、知识 2. 使用复杂的过滤和质量控制机制确保每个领域的最高质量训练数据 | 1. 对每个数据源进行严格的个体验证,评估其对整体训练配方的具体贡献 2. 通过广泛实验确定不同文档类型的采样策略,优化训练语料库的整体组成 |
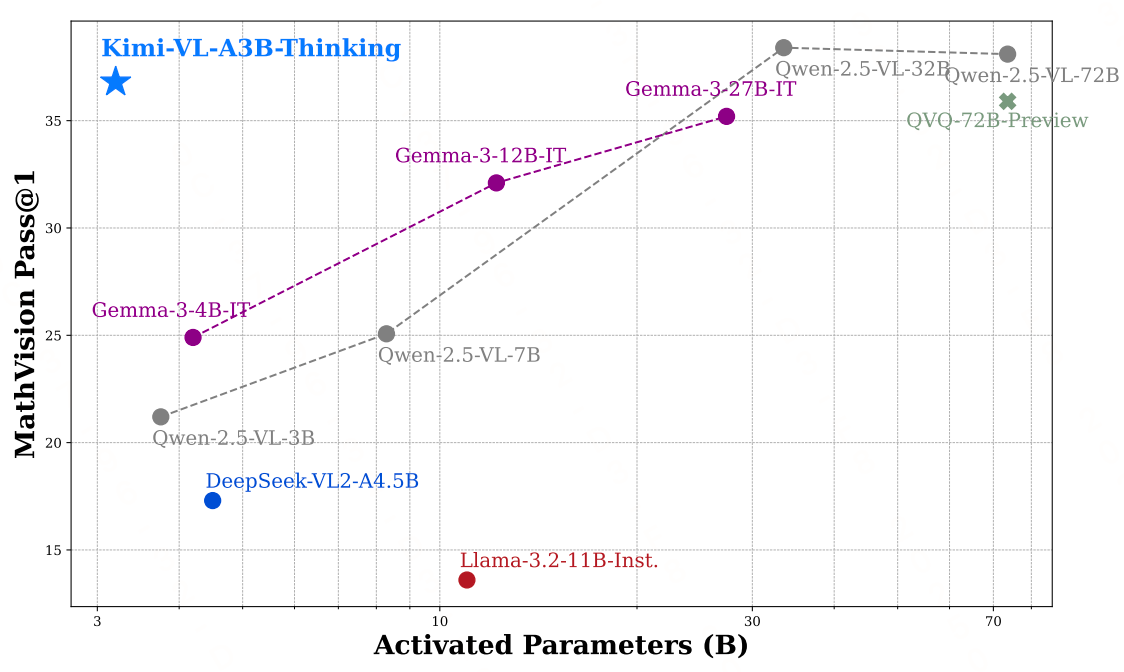
实验效果
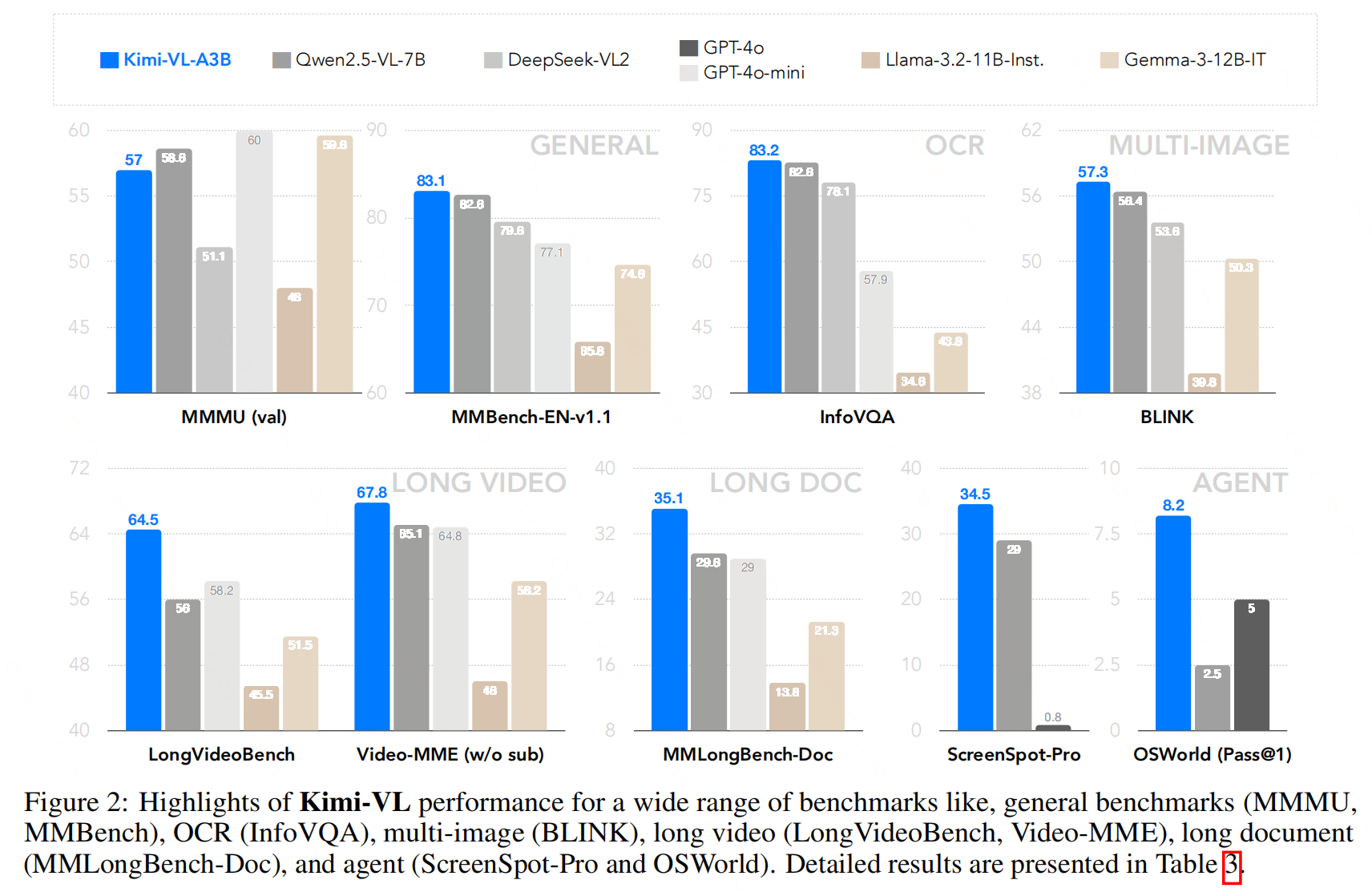
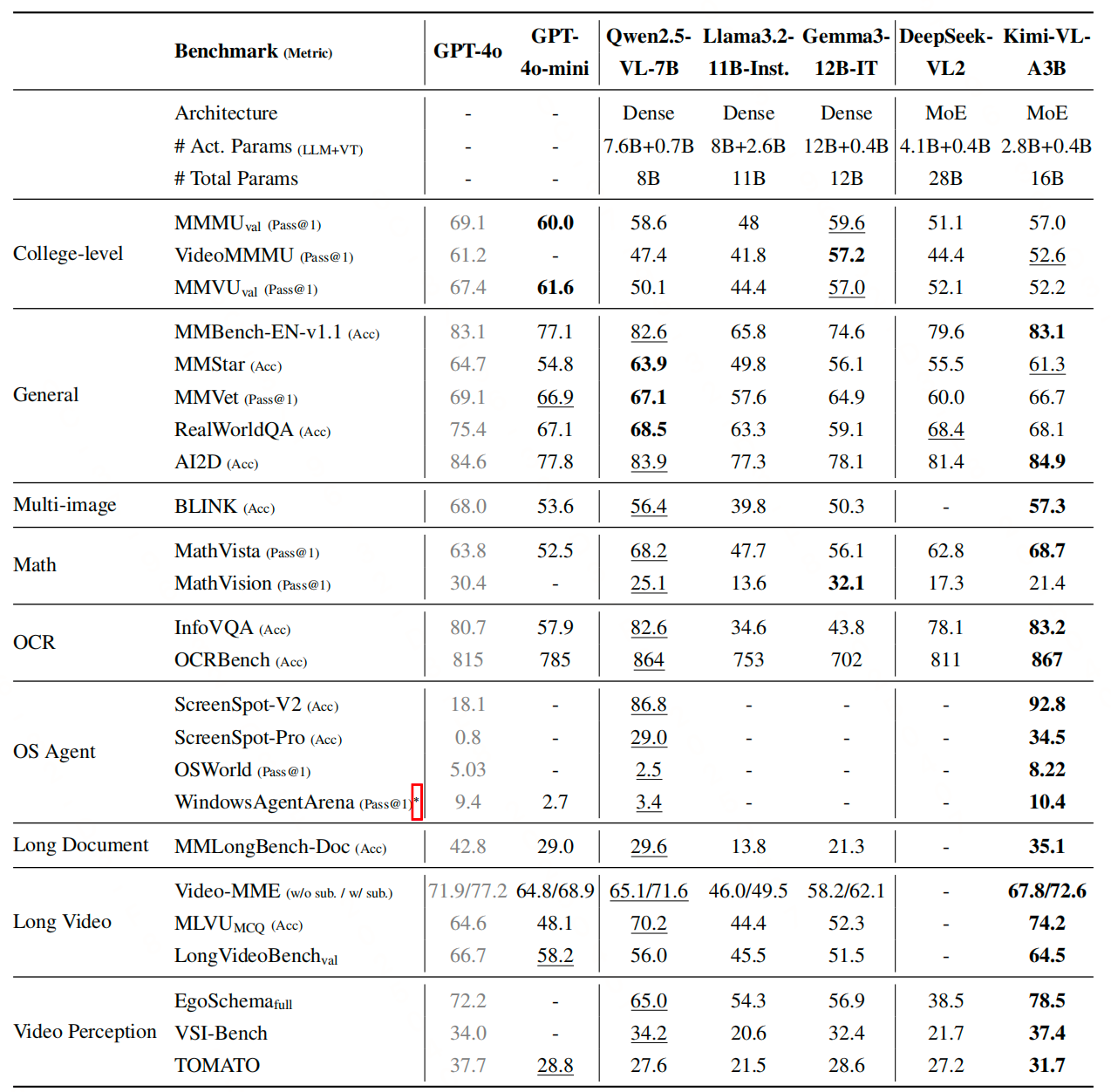
参考文献:KIMI-VL TECHNICAL REPORT,https://github.com/MoonshotAI/Kimi-VL/blob/main/Kimi-VL.pdf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









