









笔者在前期文章中总结了RAG的分块《RAG常见13种分块策略大总结(一览表)》,本文介绍一个语义分段的工作,该工作解决的问题是文本语义分割,即将文档分割成多个具有连续语义的段落。传统方法通常依赖于预处理文档以分段来解决输入长度限制问题,但这会导致段间关键语义信息的丢失。RAG系统中的文本分块方法主要分为基于规则和基于LLM的方法。
插入一个思路,其实,语义分段的方式笔者在很早实践过一个思路,不管是RAG分块还是基于规则分块,都会或多或少的都是段落信息,如何通过语义的方式分割段落?笔者之前的思路最初的想法来源于序列标注模型,那么是否能应用序列标注的方法,来预测文本行之间的跳转概率?答案是肯定的,以pdf为例,具体实施步骤如下:
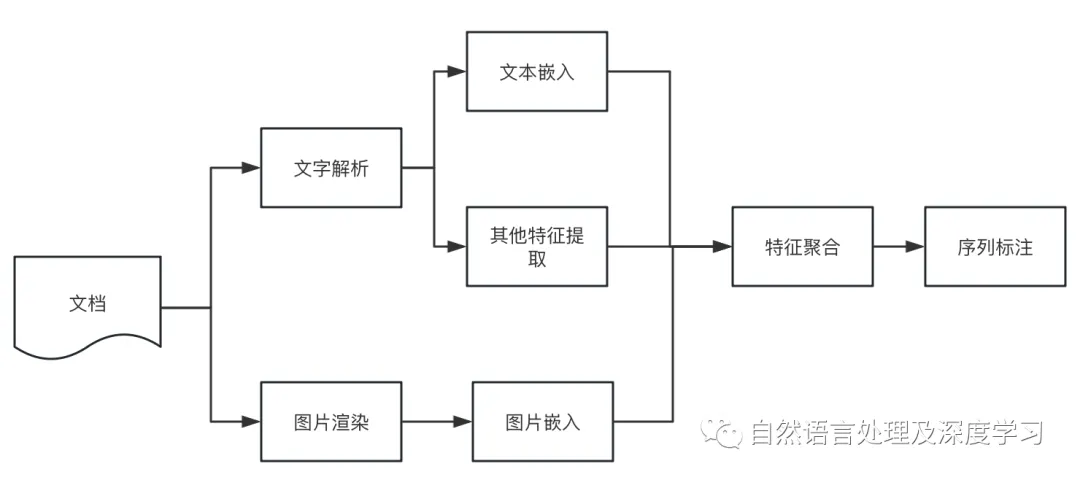
先放上笔者之前的老图:

- 从pdf读取程序或ocr引擎中得到文本行及其坐标;
- 使用神经网络对第i行的文本进行编码,得到文本嵌入向量text_emb(i);
- 提取对应行的图像,得到图像嵌入向量img_emb(i);
- 提取字号、文字长度特征,并进行归一化得到特征向量;
- 聚合步骤2、3、4得到的向量,得到行嵌入line_emb(i);
- 使用神经网络对行向量序列[line_emb(i)]进行序列标注。
整体方案流程图如下:
接下来,本文介绍的方法有异曲同工之处,也是采用序列标注的方式进行,供参考。
方法-CrossFormer
任务定义
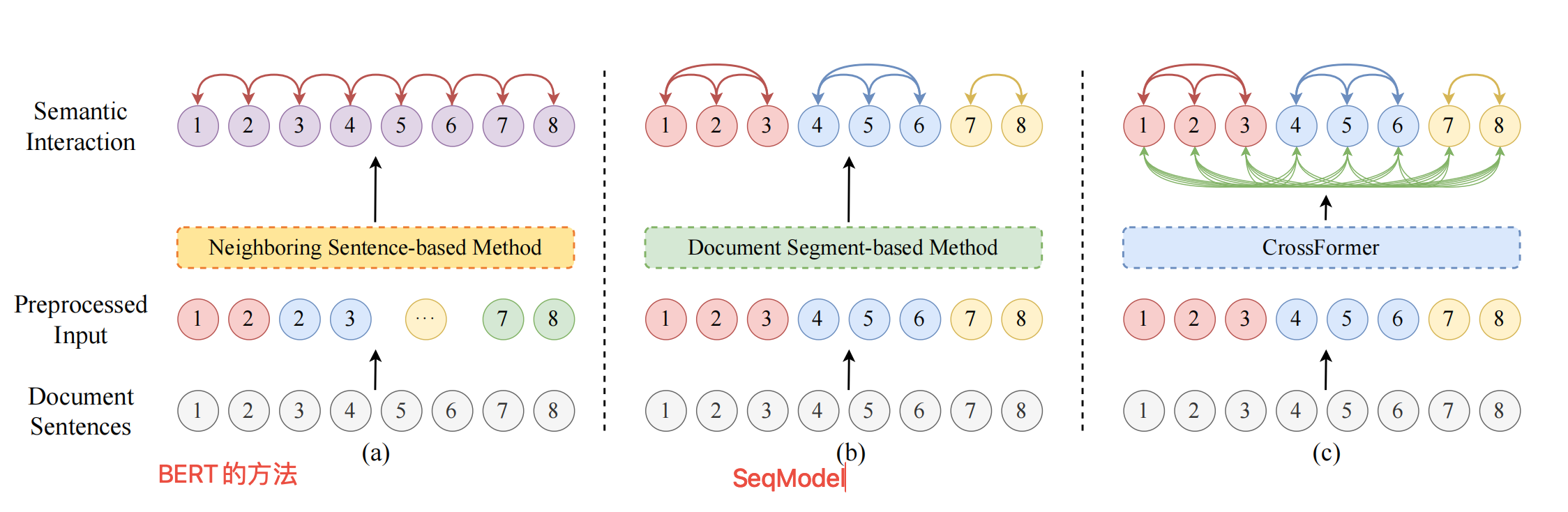
CrossFormer 将文本语义分割任务定义为句子级别的序列标注问题。给定一个文档 D \mathcal{D} D,包含 n n n 个句子,每个句子 s i s_i si 被分配一个二分类标签 y i ∈ { 0 , 1 } y_i \in \{0, 1\} yi∈{0,1}。标签 y i = 1 y_i = 1 yi=1 表示由语义连贯性统一的一个段落的终端边界,而 y i = 0 y_i = 0 yi=0 表示在同一主题段落内的连续性。目标是训练一个函数 f : D → { 0 , 1 } n f: \mathcal{D} \rightarrow \{0, 1\}^n f:D→{0,1}n,能够根据上下文预测每个句子的标签 y i y_i yi。
为了实现这一点,模型在每个句子 s i s_i si 的末尾添加一个特殊的标记 [SENT],并评估这个标记是否标志着一个段落边界。通过这种方式,文档被分割成一组不相交的语义段落。
文档预处理
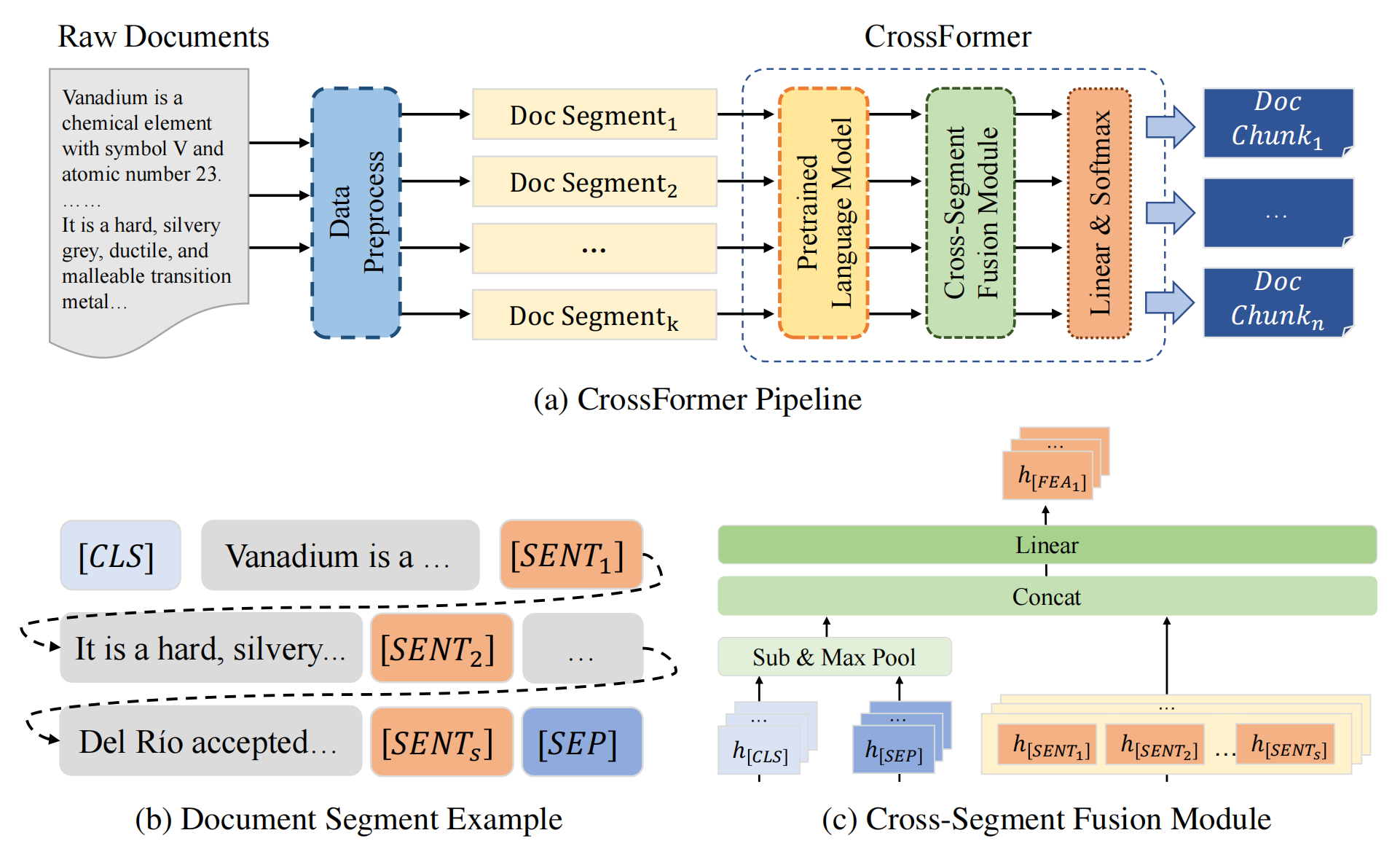
由于文本语义分割任务通常涉及长文档,需要采用适当的建模方法来有效处理这些文档。论文中采用了截断和分段的方法。步骤如下:
- 分段:根据任务指定的分隔符(如换行符或句号)对文档进行分段。
- 截断:将每个句子截断到最大长度 L L L。
- 拼接:将截断后的句子按顺序拼接,形成多个文档段,每个段的长度不超过 M M M。
- 批处理:将这些文档段组装成一个批次,并输入模型进行训练或推理。
跨段融合模块 (CSFM)
CSFM 是 CrossFormer 的核心组件,用于增强文档段之间的语义连贯性。原理如下:
- 全局语义表示:通过选择预训练的特殊标记 [CLS] 和 [SEP],提取每个段落的语义表示 h s e g h_{seg} hseg。然后,通过最大池化从这些表示中获取最大的语义成分,得到全局语义信息 h global h_{\text{global}} hglobal。
- 拼接和线性变换:将全局语义嵌入 h global h_{\text{global}} hglobal 与每个分隔符嵌入 h [ S E N T ] h_{[SENT]} h[SENT] 进行拼接,并通过两个线性层进行处理,得到 h [ F E A ] h_{[FEA]} h[FEA],即结合了全局语义信息的分隔符表示。
- 分类:将 h [ F E A ] h_{[FEA]} h[FEA] 输入线性层并应用 Softmax 函数,得到分类结果,从而确定段落边界。
训练模型使用交叉熵损失函数即可。
通过这种方式,CSFM 能够有效地捕捉文档段之间的语义依赖关系,提高分割性能。
CrossFormer 作为 RAG 文本块分割器
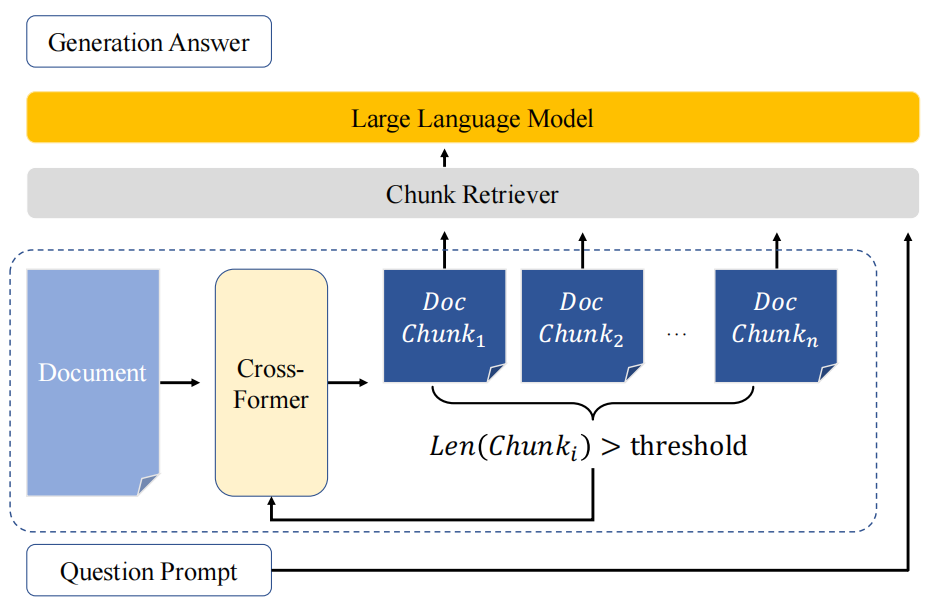
CrossFormer 可以作为RAG系统中的文本块分割器,生成更具语义连贯性的文本块。流程如下:
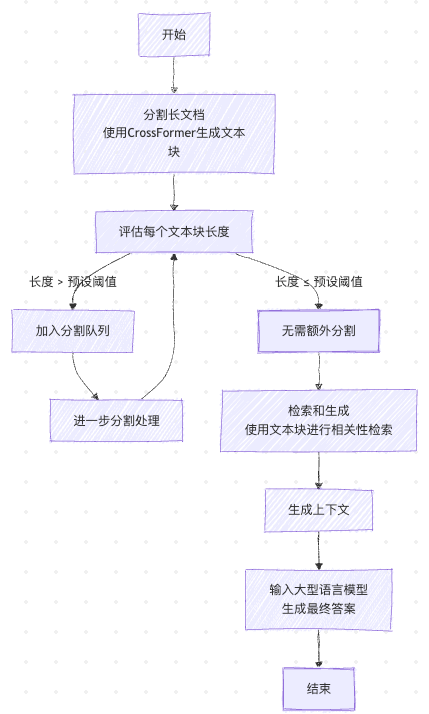
- 分割长文档:首先使用 CrossFormer 对输入文档进行分割,生成一系列文本块。
- 长度评估:评估每个文本块的长度。如果长度超过预设阈值,则将其输入分割队列进行进一步处理,直到确定不需要额外分割或文本块长度低于指定阈值。
- 检索和生成:使用分割后的文本块进行检索和生成。通过检索器和问题提示进行相关性检索,生成上下文,并将其输入到LLM中以获得最终答案。
局限性
- CrossFormer不能精确控制文本块长度的上限。因此,可能需要结合基于规则的方法来输出合适的长度。
- 作为线性文本语义分割模型,CrossFormer不能输出部分重叠的文本块,这在RAG系统的某些场景中是必需的。
实验效果
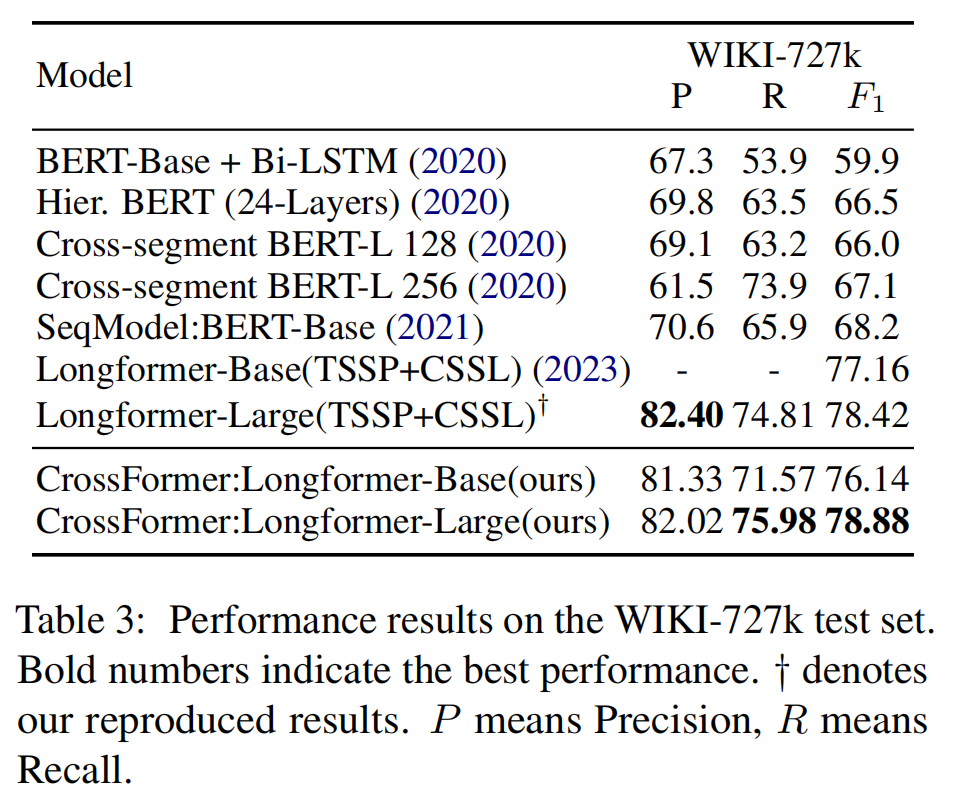
文本语义分割的结果
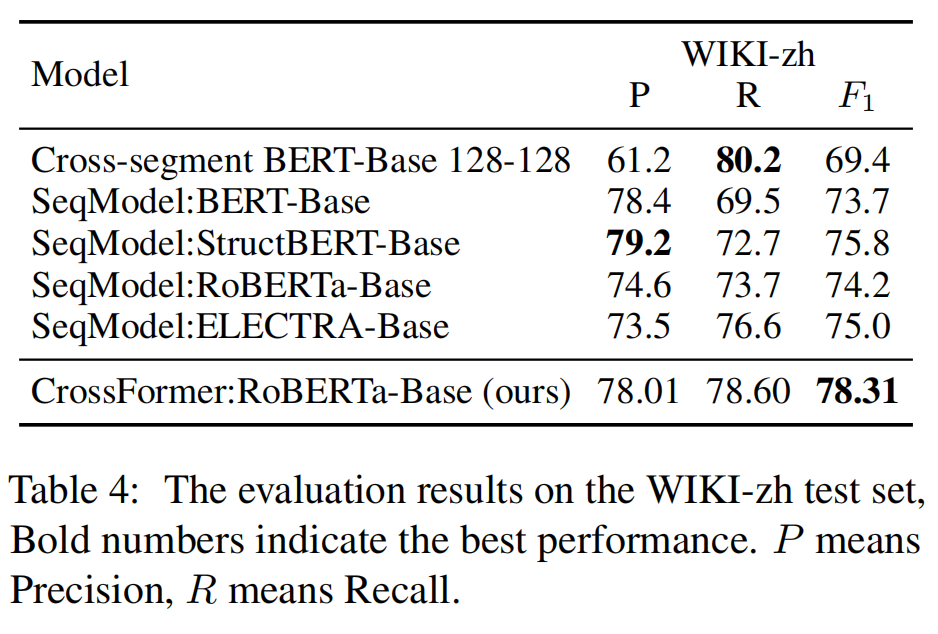
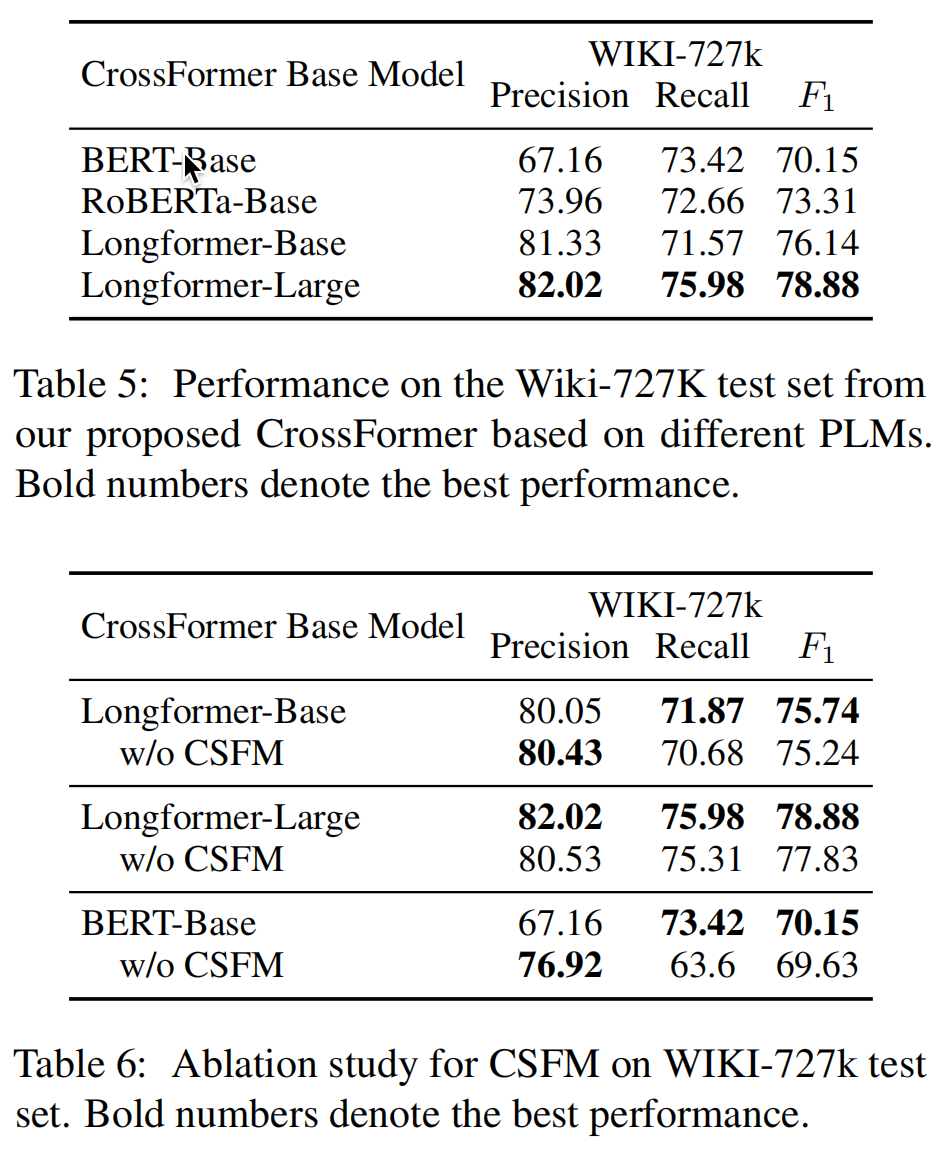
在RAG基准测试上的结果
参考文献:CrossFormer: Cross-Segment Semantic Fusion for Document Segmentation,https://arxiv.org/pdf/2503.23671v1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









