









引言
我们在之前介绍的分类算法中,判断算法好坏经常使用的指标就是准确率。本文就来告诉大家准确率的陷阱以及如何避免。
- 上一篇:机器学习入门——图解逻辑回归
- 下一篇:机器学习入门——图解支持向量机
准确度的陷阱
如果只用分类准确度来评价分类算法的话,是存在一定的问题的。
比如,一个癌症预测系统,输入体检信息,可以判断是否患有癌症。
假设预测准确度达到99.99%,那么这个系统是好的系统吗?
如果癌症产生的概率只有0.1%,那么系统只要预测所有人都是健康的,即可达到99.9%的准确率。
因此仅使用分类准确度来衡量分类系统是远远不够的,这种情况常常发生在数据是极度偏斜的。
因此需要引入其他指标来衡量分类算法的好坏。
首先介绍混淆矩阵这一工具。
混淆矩阵
混淆矩阵(Confusion Matrix),首先对于二分类问题,混淆矩阵是一个2x2的矩阵(没有考虑表头):
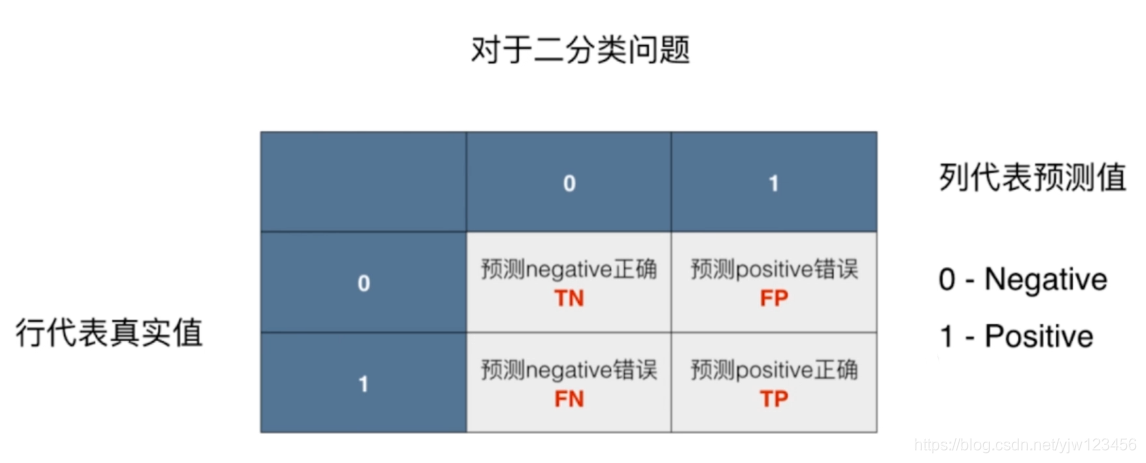
其中,蓝色部分是表头,灰色部分是相应的预测个数。在蓝色的表头中,通常列代表预测值,而行代表真实值,并且先写出0,再写出1。
其中用1(Postitive,正例)和0(Negative,负例)表示分类结果。
- 对于灰色2x2矩阵第一格,TN表示真实值是0,预测值也是0的个数,即正确(T)地预测为Negative →
TN - FP表示真实值是0,预测值1的个数,即错误(F)地预测为Positive→
FP - FN表示真实值是1,预测值0的个数,即错误(F)地预测为Negative→
FN - TP表示真实值是1,预测值1的个数,即正确(T)地预测为Positive→
TP
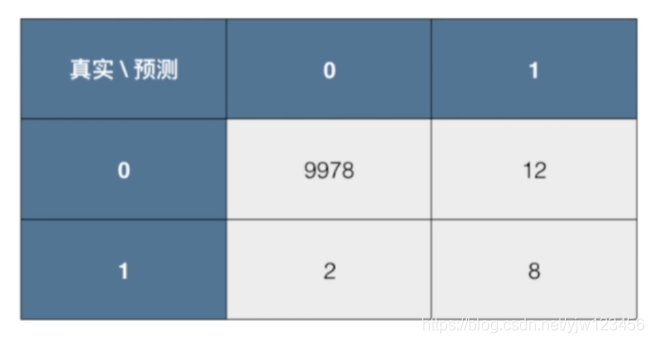
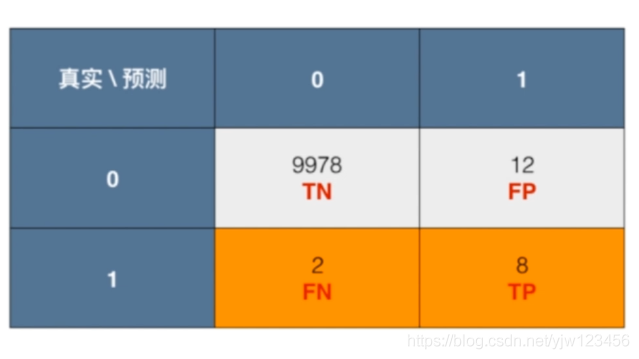
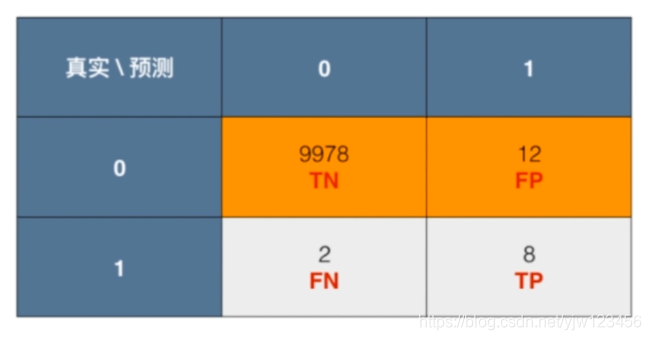
下面以癌症预测为例,假设有10000个人,通过某个算法预测结果(这里1代表患有癌症,阳性;0代表阴性,不患癌症),得到的混淆矩阵如下:
精确率和召回率
有了混淆矩阵,就可以引入两个指标:精准率(precision)和召回率(recall)。
精准率:
p
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
precision = \frac{TP}{TP + FP}
precision=TP+FPTP
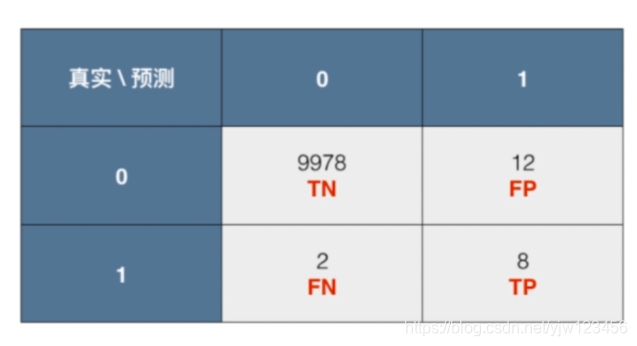
还是看刚才的例子,这里我们标出相应的TN,FP,FN,TP。然后就可以得到
精准率 = 8 / (8 + 12) = 40%
可以看到,精准率就是预测为正例( T P + F P TP + FP TP+FP)的那些数据里预测正确( T P TP TP)的数据比例。
为什么它叫精准率,因为通常在有偏的数据中,我们通常将关注的设为1(Positive)。在癌症预测中,40%的精准率代表,每做一次患病的预测,只有40%的概率是正确的。
从图中可以看到,精准率的分母是预测值为1的那一列。
召回率:
r
e
c
a
l
l
=
T
P
T
P
+
F
N
recall = \frac{TP}{TP+FN}
recall=TP+FNTP
在癌症预测例子中,召回率=8 / (8 + 2) = 80%
召回率就是真实为正例(
F
N
+
T
P
FN+TP
FN+TP)的那些数据里预测正确(
T
P
TP
TP)的数据比例。
在癌症预测例子中,就是10000个人里面,共有10个癌症患者,其中成功预测出了8个。
从图中可以看到,召回率的分母是真实值为1的那一行。
现在,以预测癌症为例,假设有10000个人,其中有10个人患有癌症,我们的系统预测所有人都是健康的。根据这一情况,我们画出混淆矩阵。
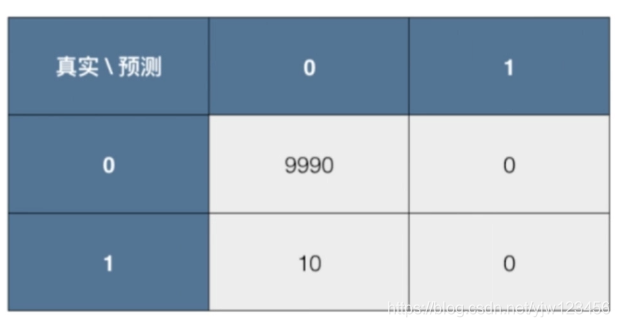
在这个系统中,准确率=9990 / (10000) = 99.9%
精准率 = 0 / (0+0) = 0 无意义,分母为0是无意义的,我们也认为这个预测结果也是无意义的,然后给个最低值0
召回率 = 0 / (10 + 0) = 0 ,说明患有癌症的一个都没预测出来。
这就是精准率和召回率在有偏的数据中的意义。
还是一样的,下面我们编程实现这些指标。
代码实现混淆矩阵、精准率和召回率
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
# 产生偏斜数据
# 变成二分类问题,大多数偏向于0类别
y[digits.target==9] = 1
y[digits.target!=9] = 0
# 拆分数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
# 使用逻辑回归进行训练
log_reg = LogisticRegression()
log_reg.fit(X_train,y_train)
print(log_reg.score(X_test,y_test)) # 0.9755555555555555
下面我们用上面学到的精准率和召回率来进行评估看看。
首先得到预测结果,可以看到,是一个非0即1的数组。
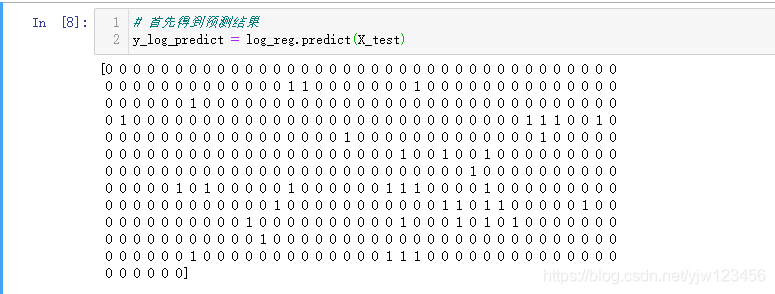
根据numpy的数组运算,就可以写出下面几个函数:
def TN(y_true,y_predict):
# 真实是0,预测也是0
return np.sum((y_true == 0) & (y_predict == 0))
def FP(y_true,y_predict):
# 真实是0,预测是1
return np.sum((y_true == 0) & (y_predict == 1))
def FN(y_true,y_predict):
# 真实是1,预测是0
return np.sum((y_true == 1) & (y_predict == 0))
def TP(y_true,y_predict):
# 真实是1,预测也是1
return np.sum((y_true == 1) & (y_predict == 1))
# 混淆矩阵
def confusion_matrix(y_true,y_predict):
return np.array([
[TN(y_true,y_predict),FP(y_true,y_predict)],
[FN(y_true,y_predict),TP(y_true,y_predict)],
])

调用混淆矩阵函数,就可以得到混淆矩阵结果(去掉了表头)。
接下来计算精准率和召回率。
# 定义精准率函数
def precision_score(y_true, y_predict):
tp = TP(y_true,y_predict)
fp = FP(y_true,y_predict)
return tp / (tp + fp) if tp + fp != 0 else 0
# 定义召回率函数
def recall_score(y_true, y_predict):
tp = TP(y_true,y_predict)
fn = FN(y_true,y_predict)
return tp / (tp + fn) if tp + fn != 0 else 0

这就是通过代码实现计算混淆矩阵、精准率和召回率的例子。
sklearn其实已经帮我们实现好了计算这些指标的函数,下面看一下是如何使用的:
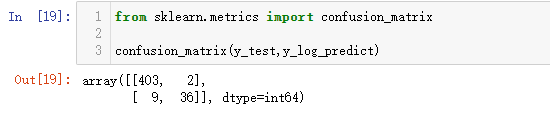
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_log_predict)
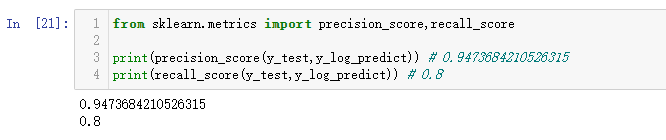
from sklearn.metrics import precision_score,recall_score
print(precision_score(y_test,y_log_predict)) # 0.9473684210526315
print(recall_score(y_test,y_log_predict)) # 0.8
现在我们学会了两个指标,那么如何解读这两个指标呢。请继续阅读。
F1 Score
如何使用这两个指标呢,其实和使用的场景有关。
在不同的应用场景下,我们的关注点不同,例如,在预测股票的时候,我们更关心精准率,即我们预测上涨(Positive)的那些股票里,真的上涨了的有多少;
而在预测癌症的场景下,我们更关注召回率,即真的患癌的那些人里我们预测错了情况应该越少越好,因为真的患癌如果没有检测出来,结果是很严重的。
还有一些场景,可能需要同时关注精准率和召回率,此时引入一个新的指标:F1 Score,它就是兼顾精准率和召回率的指标。
F1 Score:
F
1
=
2
⋅
p
r
e
c
i
s
i
o
n
⋅
r
e
c
a
l
l
p
r
e
c
i
s
i
o
n
+
r
e
c
a
l
l
F1 = \frac{2 \cdot precision \cdot recall}{precision + recall}
F1=precision+recall2⋅precision⋅recall
F1 Score 是精准率和召回率的调和平均值,把F1 Score取倒数,就得:
1 F 1 = 1 2 ( 1 p r e c i s i o n + 1 r e c a l l ) \frac{1}{F1} = \frac{1}{2} \left( \frac{1}{precision } + \frac{1}{recall} \right) F11=21(precision1+recall1)
调和平均值的性质就是,只有当精准率和召回率二者都非常高的时候,它们的调和平均才会高。如果其中之一很低,调和平均就会被拉得接近于那个很低的数。
下面我们通过代码实现以下这个F1 Score:
import numpy as np
def f1_score(precision,recall):
try:
return 2 * precision * recall /(precision + recall)
except:
# 如果分母为0
return 0.0
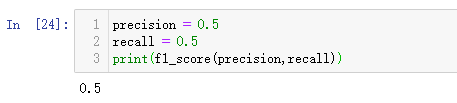
如果精准率和召回率相等的话,那么F1 Score就返回相等的这个值。

可以看到,有一个较小,都会大大拉低F1 Score的值,如果是算术平均的话就是0.5了,这就是F1 Score的优势。
因此,精准率和召回率要同时比较好时,F1 Score才会比较高。
precision = precision_score(y_test,y_log_predict) # 0.9473684210526315
recall = recall_score(y_test,y_log_predict) # 0.8
print(f1_score(precision,recall)) # 0.8674698795180723
我们用上一节得到的精确率和召回率代入f1_score函数中,得到具体的F1 Score为0.867。
精准率和召回率的平衡
那我们只要让精准率和召回率都变大,我们的F1 Score也会变得很大。但是,其实精准率和召回率有一定的矛盾关系。如果精准率变高,召回率就会下降;反之亦然。 因此,重点是如何找到这二者之间的平衡。
以逻辑回归为引子
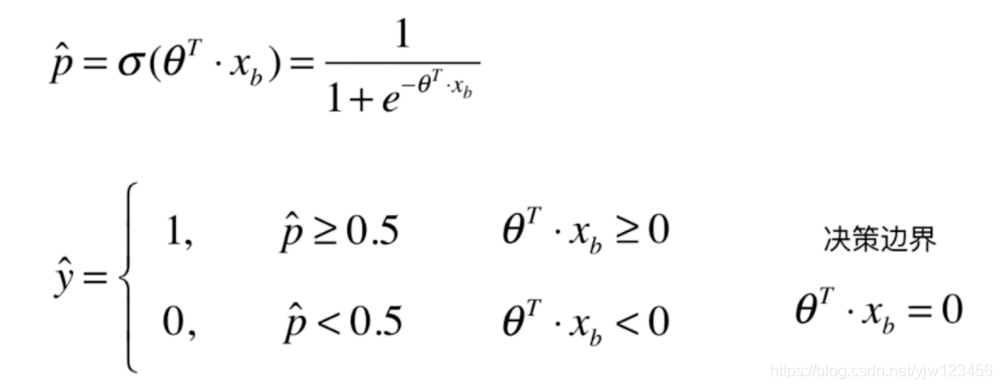
逻辑回归计算出的
p
^
\hat p
p^如果大于等于0.5,分类为1;否则分类为0。 这样我们得到决策边界
θ
T
⋅
x
b
=
0
\theta^T \cdot x_b = 0
θT⋅xb=0。
如果我们不是令决策边界等于0,而是定义一个阈值threshold。
令
θ
T
⋅
x
b
=
t
h
r
e
s
h
o
l
d
\theta^T \cdot x_b = threshold
θT⋅xb=threshold
此时如果
θ
T
⋅
x
b
>
t
h
r
e
s
h
o
l
d
\theta^T \cdot x_b >threshold
θT⋅xb>threshold,就让它分类为1;否则分类为0。
也就是说,我们可以通过改变这个阈值,来影响分类结果,下面我们来看会如何影响分类结果。
我们以 θ T ⋅ x b \theta^T \cdot x_b θT⋅xb的值画一个轴,定义其为score。
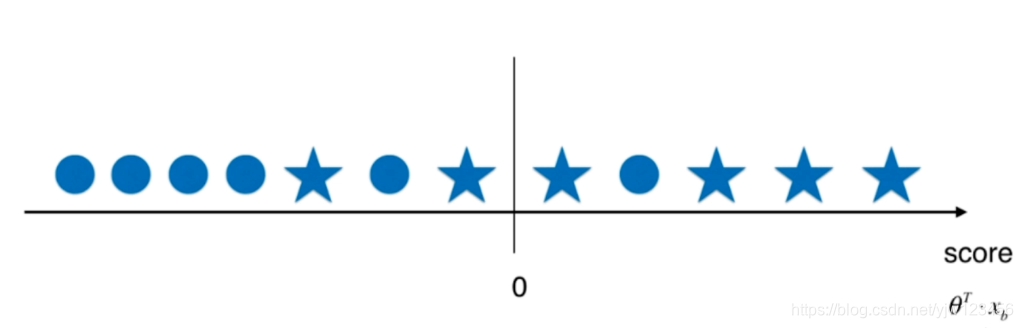
图5是以0为阈值时,分类的结果。其中轴上面的五角星和圆圈代表不同的样本,假设五角星是我们关注的样本,真实类别为1;而圆圈代表类别为0。
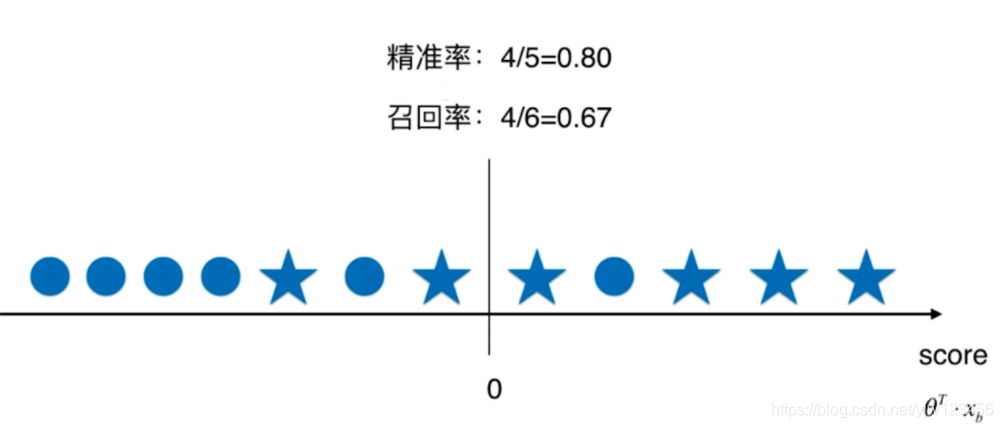
而召回率是,真实为1的数据里,预测正确的比例:4/6 = 0.67。
如果我们挪动阈值,那么精准率和召回率会怎样变化呢?
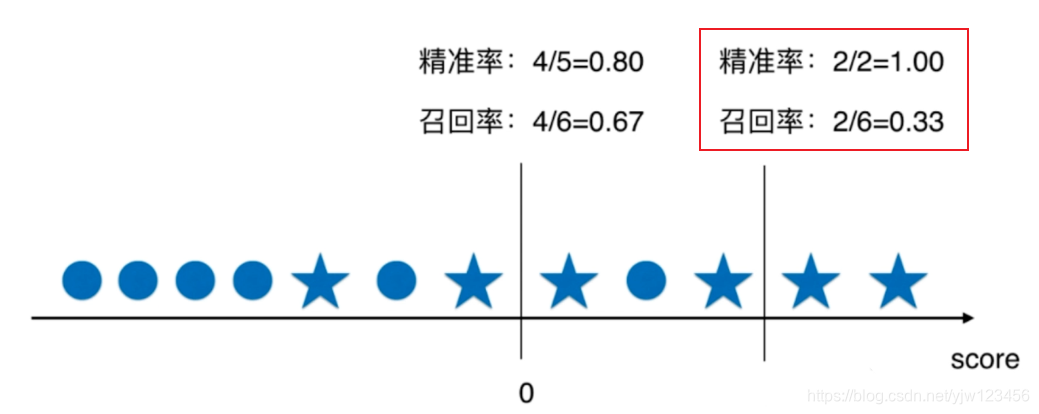
这是我们将分类阈值变大之后的结果,如果变小呢?
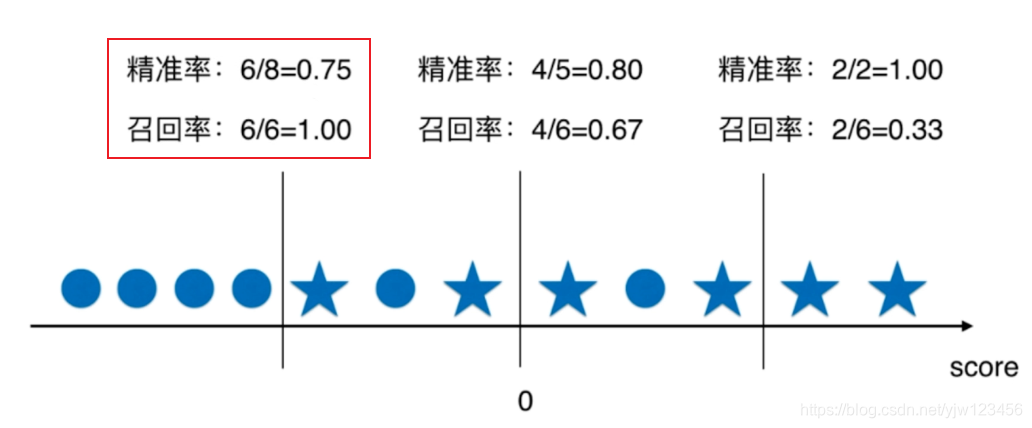
总结一下,看图8,随着阈值的增大,精准率变高,同时召回率变低。
从这可以看到精准率和召回率的矛盾。
如果我们思考一下,要想精确率变高,那么只有相当有把握的,我们才会分类为1,此时就有可能排除掉很多实际上为1的样本。
如果想要召回率升高,那么哪怕把握不高,我们也判断为1,这样就会包含很多实际为0的样本。
下面使用程序来看一下它们的关系。
# 逻辑回归默认以0为阈值进行判断的,我们无法这个阈值。
# 但是逻辑回归可以输出得到的分数
decision_scores = log_reg.decision_function(X_test)
decision_scores[:10]

print(np.min(decision_scores),np.max(decision_scores)) # -85.71086856567963 19.87471653041543
# 我们可以利用这个分数来进行自定义判断
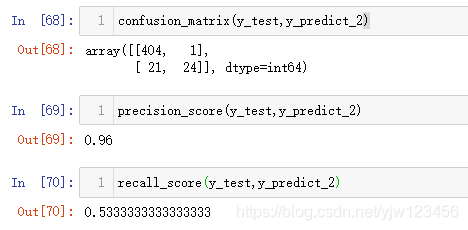
y_predict_2 = np.array(decision_scores >= 5, dtype='int')
confusion_matrix(y_test,y_predict_2)
我们把基于decision_scores >= 5的结果转换为1和0的预测结果,然后得到混淆矩阵。
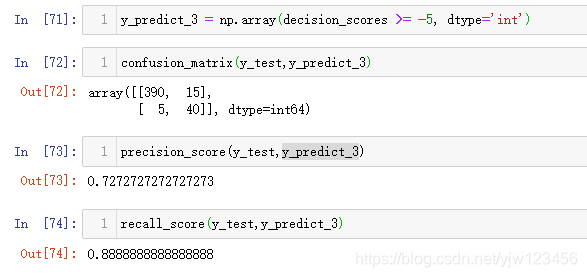
下面我们可以调低阈值,然而再次看结果:
精准率-召回率曲线
上一小节我们通过代码的方式,来看到了精确率和召回率之间的平衡关系。本小节,我们通过绘图的方式让大家更直观的看到这种关系。
from sklearn.metrics import precision_score,recall_score
import matplotlib.pyplot as plt
precisions = [] # 保存每个threshold的精准率
recalls = [] # 保存每个threshold的召回率
# 以decision_scores的最小值为起点,最大值为终点,步长为0.1,定义一个数组
thresholds = np.arange(np.min(decision_scores),np.max(decision_scores),0.1)
for threshold in thresholds:
y_predict = np.array(decision_scores >= threshold, dtype='int')
precisions.append(precision_score(y_test,y_predict))
recalls.append(recall_score(y_test,y_predict))
plt.plot(thresholds, precisions)
plt.plot(thresholds, recalls)
plt.show()
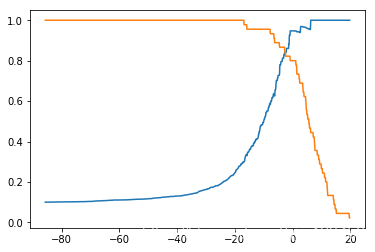
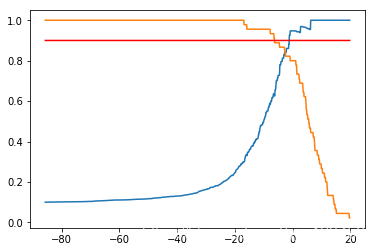
还有一种曲线叫Precisioni-Recall曲线,就是以精确率为横轴,召回率为纵轴画的曲线。
plt.plot(precisions, recalls)
plt.show()
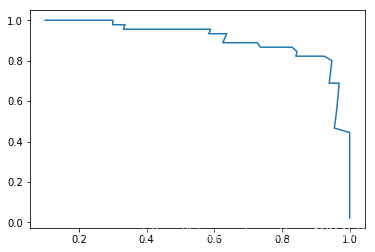
当然,sklearn也帮我们封装好了画精确率-召回率曲线的方法。
from sklearn.metrics import precision_recall_curve
# sklearn会自动进行分隔,同样可以得到每个阈值对应的精确率和召回率
precisions,recalls,thresholds = precision_recall_curve(y_test,decision_scores)
plt.plot(thresholds, precisions[:-1]) # precisions会比thresholds多一个值
plt.plot(thresholds, recalls[:-1])
plt.show()
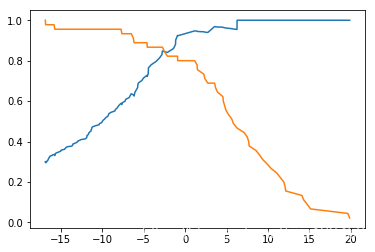
plt.plot(precisions, recalls)
plt.show()
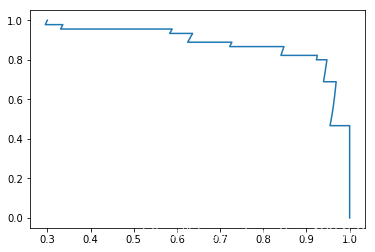
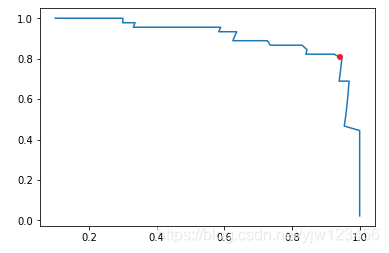
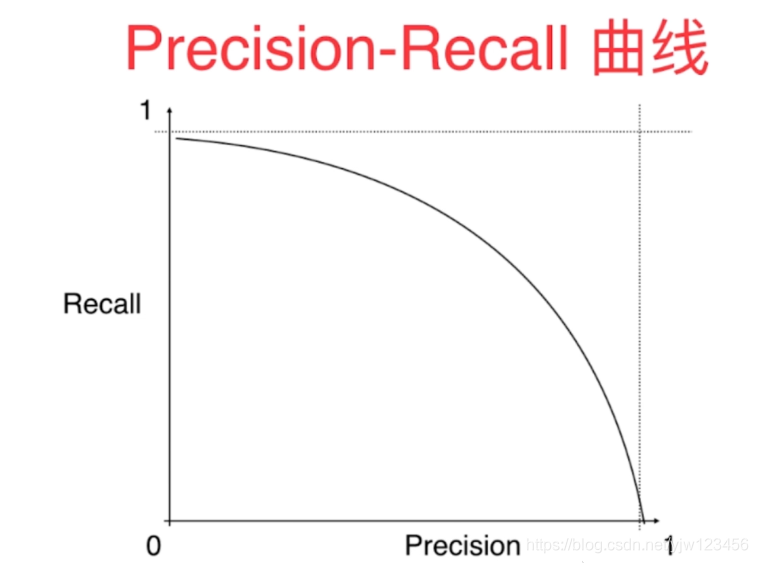
根据这些图可以得出,Precision-Recall曲线大概是下面这样的一种趋势:
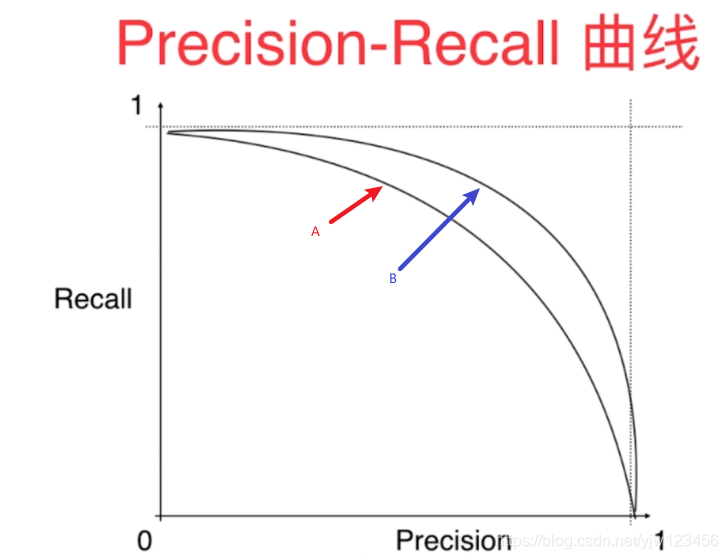
因此可以看出,该曲线也可以作为一个选择模型、选择算法、选择超参数的指标。
对于这个指标,外面说里外会有些抽象,因此可以用该曲线和x,y轴所包的面积(PR曲线面积)来看。面积越大,模型越好。
虽然这样可以,但是大多数情况下我们不用PR曲线面积来衡量模型的好坏。
而是用ROC曲线,请看下小节。
ROC曲线
描述的TPR(True Positive Rate)和FPR(False Positive Rate)之间的关系。
啥是TPR和FPR呢,TPR其实就等于召回率。
T
P
R
=
T
P
T
P
+
F
N
TPR = \frac{TP}{TP + FN}
TPR=TP+FNTP
如图17所示,TPR就是用TP除以真实值为1的这一行。
F P R = F P T N + F P FPR = \frac{FP}{TN+ FP} FPR=TN+FPFP
简单来说,TPR就是预测为1,并且预测对了的数量占真实为1的比例;
FPR就是预测为1,但是预测错了的数量占真实为0的比例;
类似召回率和精确率,TPR和FPR之间也存在一定关系。我们来看下是什么关系。

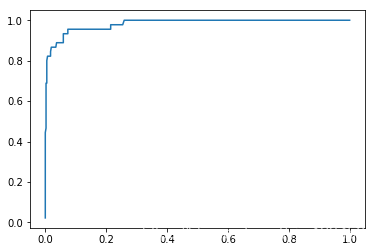
可以看到,随着阈值逐渐降低,FPR和TPR都是逐渐升高,它们有一种正相关关系。
而ROC曲线正是刻画它们之间这种关系的曲线。
下面通过代码来画ROC曲线:
def TPR(y_true, y_predict):
tp = TP(y_true,y_predict)
fn = FN(y_true,y_predict)
try:
return tp/(tp + fn)
except:
return 0.0
def FPR(y_true, y_predict):
fp = FP(y_true,y_predict)
tn = TN(y_true,y_predict)
try:
return fp/(fp + tn)
except:
return 0.0
import matplotlib.pyplot as plt
fprs = []
tprs = []
thresholds = np.arange(np.min(decision_scores),np.max(decision_scores),0.1)
for threshold in thresholds:
y_predict = np.array(decision_scores >= threshold,dtype='int')
tprs.append(TPR(y_test,y_predict))
fprs.append(FPR(y_test,y_predict))
plt.plot(fprs,tprs)
plt.show()
sklearn计算FPR和TPR也非常简单:
from sklearn.metrics import roc_curve
fprs,tprs,thresholds = roc_curve(y_test,decision_scores)
plt.plot(fprs,tprs)
plt.show()
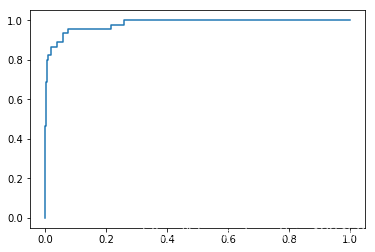
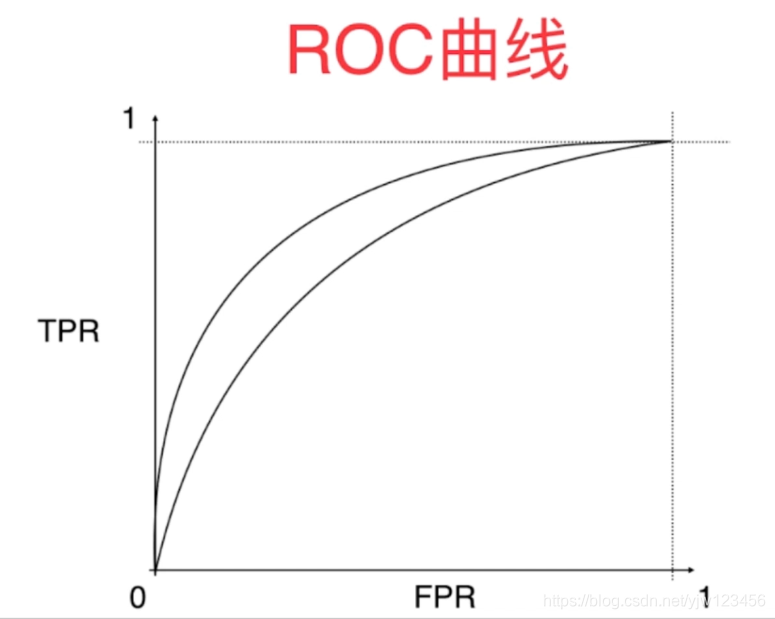
对于ROC曲线来说,我们通常关注的是曲线下面面积的大小。
面积越大,代表模型越好。
在x(FPR)越小的时候(犯False Positive错误越少的时候),如果曲线的值(TPR)越高(得到True Positive正确结果越多)的时候,曲线就会很高,也就是面积就会很大。
sklearn提供了一个方法来求这个面积:
from sklearn.metrics import roc_auc_score
roc_auc_score(y_test,decision_scores)

计算的面积称为AUC (Area Under Curve),取值范围[0.5,1],这里得到的是0.98。
多分类问题中的混淆矩阵
上面我们看的都是基于二分类问题的,本小节来看下针对多分类问题,如何定义混淆矩阵。
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
digits = datasets.load_digits()
X = digits.data
y = digits.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.8,random_state=666)
log_reg = LogisticRegression()
log_reg.fit(X_train,y_train)
print(log_reg.score(X_test,y_test)) # 0.9408901251738526
首先还是以手写数字为例,不过这次完整的保留了10个类别。
from sklearn.metrics import precision_score
y_predict = log_reg.predict(X_test)
# 通过制定average='micro'来计算多分类的精确率
precision_score(y_test,y_predict,average='micro')
上面是如何计算多分类问题下的精确率。
我们重点来看下混淆矩阵:
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_predict)
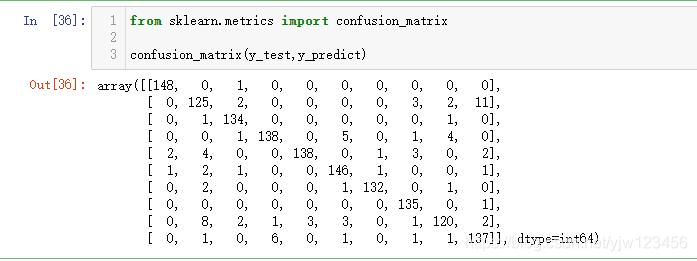
可以看到,在10个类别的分类任务中,混淆矩阵是一个10x10的矩阵。
此时,对角线上的值都比较大,对角线代表预测正确的数量,说明预测正确的较多。
from sklearn.metrics import confusion_matrix
cfm = confusion_matrix(y_test,y_predict)
plt.matshow(cfm, cmap=plt.cm.gray) #画矩阵
plt.show()

在上图中,越亮的方块代表数值越大,越暗的方块代表数值越小。
不过我们关注预测正确的部分是没有意义的,我们真正关心的是预测错误的地方。
# 首先计算每行的样本数
row_numbers = np.sum(cfm,axis=1)
# 得到新的矩阵,用每行的数字除以每行的数字总和
err_matrix = cfm / row_numbers
# 我们不关心对角线上预测正确的数量,因此填充对角线上的值为0
np.fill_diagonal(err_matrix,0)
err_matrix
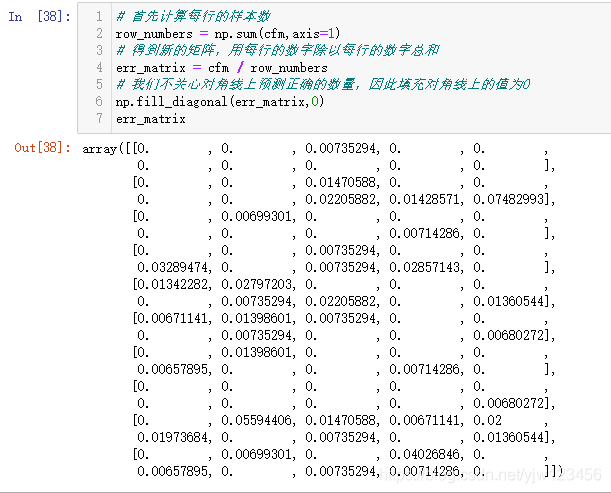
将对角线上的值设成0后,得到我们关注的错误矩阵。
下面我们按照之前的方式绘制这个矩阵:
plt.matshow(err_matrix, cmap=plt.cm.gray)
plt.show()
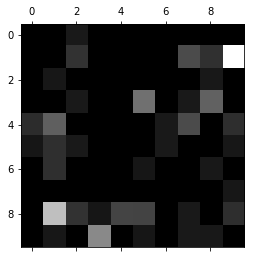
通过这样的一个图,我们就可以知道在哪里犯错比较多,同时还知道错在哪了。















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











