







网页源代码如下(2022.10.11):
找到目标所在的父标签、子标签后,实现代码

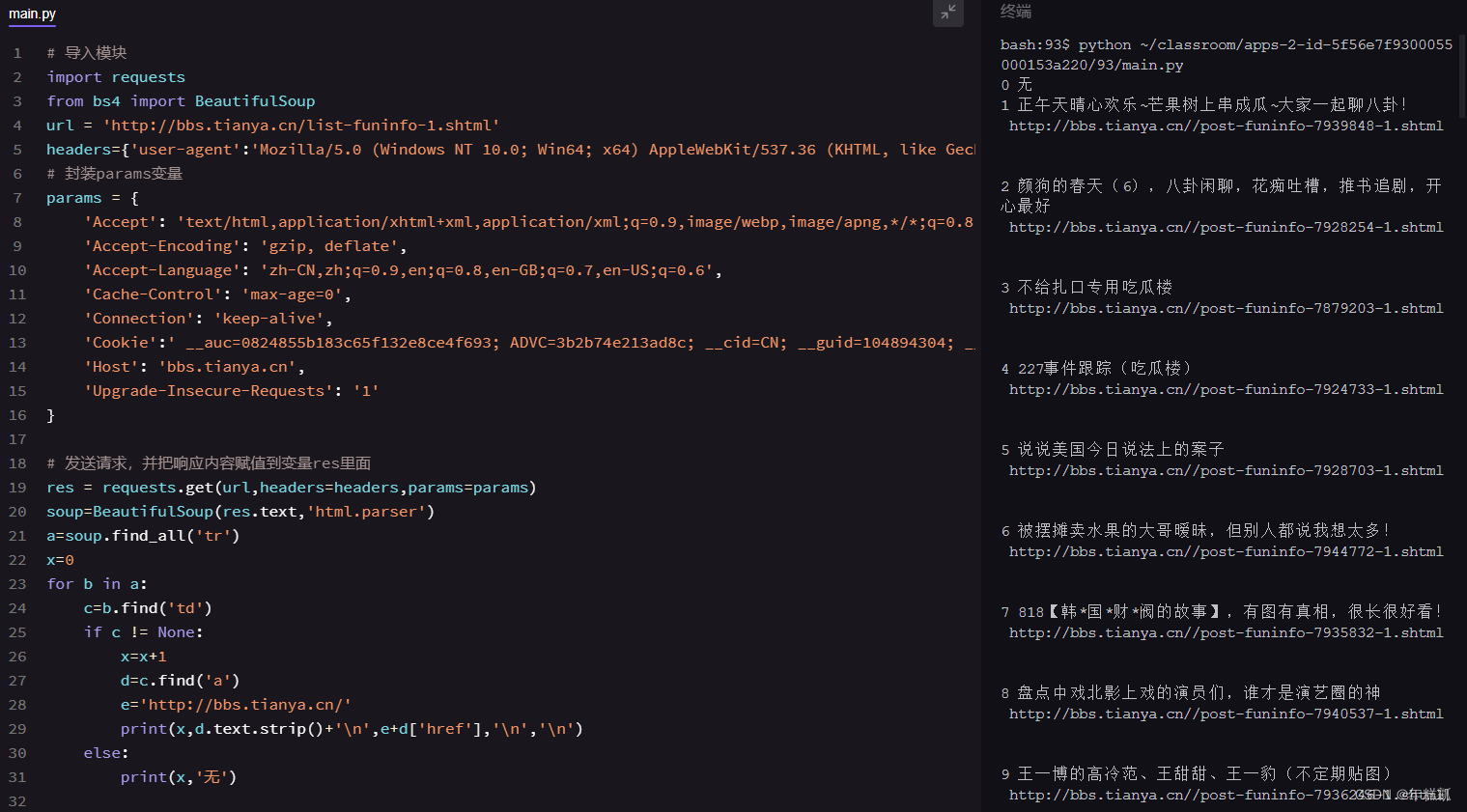
代码如下:
#导出bs4,requests库
import bs4,requests
#伪装请求头
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
#编辑url网址
url='http://bbs.tianya.cn/list-funinfo-1.shtml'
#requests.get()方法
res=requests.get(url,headers=headers)
#利用BeatifulSoup方法
info_1=bs4.BeautifulSoup(res.text,'html.parser')
#利用BeautifulSoup的find.all(),并写上标签‘tr’,和属性class_和属性值‘bg’
info_2=info_1.find_all('tr',class_="bg")
#利用循环取值
for info_3 in info_2:
#用find()里面写上标签‘a’
info_4=info_3.find('a')
#输出text格式,并用strip()去掉空格
print(info_4.text.strip())
















 2388
2388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









