







 文章介绍了Go语言编程的一些最佳实践,包括编码规范如使用gofmt格式化代码、注释、命名规范等,以及性能优化建议,如依靠数据做决策,避免过早优化,预分配内存以减少切片和map的内存拷贝,使用strings.Builder提升字符串拼接效率,并提到了性能调优工具如pprof的重要性。
文章介绍了Go语言编程的一些最佳实践,包括编码规范如使用gofmt格式化代码、注释、命名规范等,以及性能优化建议,如依靠数据做决策,避免过早优化,预分配内存以减少切片和map的内存拷贝,使用strings.Builder提升字符串拼接效率,并提到了性能调优工具如pprof的重要性。
Go 高质量编程 & 性能调优
1. 高质量编程
1.1简介
-
编写的代码能够达到正确可靠、简洁清晰、无性能隐患的目标就能称之为高质量代码
-
实际应用场景千变万化,各种语言的特性和语法各不相同,但是高质量编程遵循的原则是相通的
-
高质量的编程原则:
-
简单性
消除多余的复杂性,以简单清晰的逻辑编写代码
-
可读性
编写可维护代码的第一步是确保代码可读
-
生产力
团队整体工作效率非常重要
-
1.2编码规范
-
代码格式
使用 gofmt 自动格式化代码,保证所有的 Go 代码与官方推荐格式保持一致
-
公共符号始终要注释
包中声明的每个公共的符号:变量、常量、函数以及结构都需要添加注释代码是最好的注释
注释应该提供代码未表达出的上下文信息
-
命名规范
-
variable
- 简洁胜于冗长
- 缩略词全大写,但当其位于变量开头且不需要导出时,使用全小写
- 变量距离其被使用的地方越远,则需要携带越多的上下文信息
- 全局变量在其名字中需要更多的上下文信息,使得在不同地方可以轻易辨认出其含义
-
function
- 函数名不携带包名的上下文信息,因为包名和函数名总是成对出现的
- 函数名尽量简短
- 当名为 foo 的包某个函数返回类型 Foo 时,可以省略类型信息而不导致歧义
- 当名为 foo 的包某个函数返回类型 T 时(T 并不是 Foo),可以在函数名中加入类型信息
-
package
- 只由小写字母组成。不包含大写字母和下划线等字符
- 简短并包含一定的上下文信息。例如 schema、task 等
- 不要与标准库同名。例如不要使用 sync 或者 strings
-
-
控制流程
- 避免嵌套,保持正常流程清晰
- 如果两个分支中都包含 return 语句,则可以去除冗余的 else
- 尽量保持正常代码路径为最小缩进,优先处理错误情况/特殊情况,并尽早返回或继续循环来减少嵌套,增加可读性
-
错误和异常处理
-
简单错误处理
优先使用 errors.New 来创建匿名变量来直接表示该错误。有格式化需求时使用 fmt.Errorf
-
错误的 Wrap 和 Unwrap
在 fmt.Errorf 中使用 %w 关键字来将一个错误 wrap 至其错误链中

-
错误判定
-
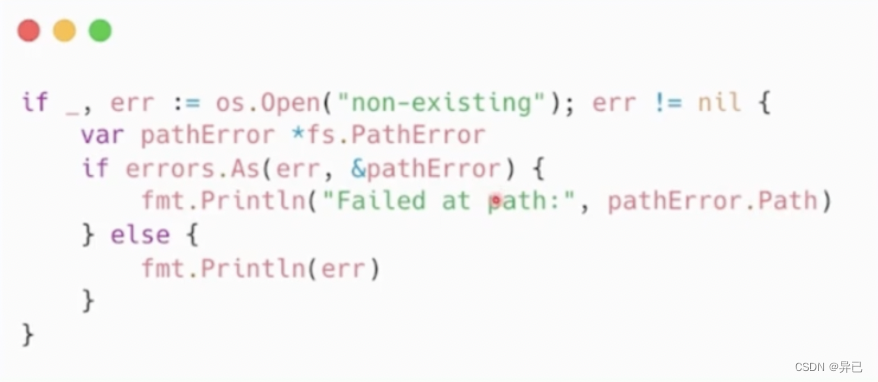
使用 errors.Is 可以判定错误链上的所有错误是否含有特定的错误。
-
在错误链上获取特定种类的错误,使用 errors.As
-
-
panic
- 不建议在业务代码中使用 panic
- 如果当前 goroutine 中所有 deferred 函数都不包含 recover 就会造成整个程序崩溃
- 当程序启动阶段发生不可逆转的错误时,可以在 init 或 main 函数中使用 panic
- github.com/Shopify/sar…
-
recover
-
recover 只能在被 defer 的函数中使用,嵌套无法生效,只在当前 goroutine 生效
-
如果需要更多的上下文信息,可以 recover 后在 log 中记录当前的调用栈。
-
-
2. 性能优化建议
-
性能调优原则
- 要依靠数据不是猜测
- 要定位最大瓶颈而不是细枝末节
- 不要过早优化
- 不要过度优化
-
slice 预分配内存
– 类比 c++ vector。reserve() 进行预分配内存,防止后续插入导致不断进行内存销毁和分配
- 在尽可能的情况下,在使用 make() 初始化切片时提供容量信息,特别是在追加切片时
- 原理
- ueokande.github.io/go-slice-tr…
- 切片本质是一个数组片段的描述,包括了数组的指针,这个片段的长度和容量(不改变内存分配情况下的最大长度)
- 切片操作并不复制切片指向的元素,创建一个新的切片会复用原来切片的底层数组,因此切片操作是非常高效的
- 切片有三个属性,指针(ptr)、长度(len) 和容量(cap)。append 时有两种场景:
- 当 append 之后的长度小于等于 cap,将会直接利用原底层数组剩余的空间
- 当 append 后的长度大于 cap 时,则会分配一块更大的区域来容纳新的底层数组
- 因此,为了避免内存发生拷贝,如果能够知道最终的切片的大小,预先设置 cap 的值能够获得最好的性能
- 另一个陷阱:大内存得不到释放
- 在已有切片的基础上进行切片,不会创建新的底层数组。因为原来的底层数组没有发生变化,内存会一直占用,直到没有变量引用该数组
- 因此很可能出现这么一种情况,原切片由大量的元素构成,但是我们在原切片的基础上切片,虽然只使用了很小一段,但底层数组在内存中仍然占据了大量空间,得不到释放
- 推荐的做法,使用 copy 替代 re-slice
-
map 预分配内存
map 为hash map , 为了保证近似O(1)的时间复杂度进行查找,当元素数量大于容量的 1/2(可设置)时,需要重新分配内存,再hash。所以预分配内存可以减少再hash次数 。 – 类比 Redis hset
- 原理
- 不断向 map 中添加元素的操作会触发 map 的扩容
- 根据实际需求提前预估好需要的空间
- 提前分配好空间可以减少内存拷贝和 Rehash 的消耗
- 原理
-
使用 strings.Builder
- 常见的字符串拼接方式
-
- strings.Builder
- bytes.Buffer
-
- strings.Builder 最快,bytes.Buffer 较快,+ 最慢
- 原理
- 字符串在 Go 语言中是不可变类型,占用内存大小是固定的,当使用 + 拼接 2 个字符串时,生成一个新的字符串,那么就需要开辟一段新的空间,新空间的大小是原来两个字符串的大小之和
- strings.Builder,bytes.Buffer 的内存是以倍数申请的
- strings.Builder 和 bytes.Buffer 底层都是 []byte 数组,bytes.Buffer 转化为字符串时重新申请了一块空间,存放生成的字符串变量,而 strings.Builder 直接将底层的 []byte 转换成了字符串类型返回
- 常见的字符串拼接方式
-
使用空结构体节省内存
- 空结构体不占据内存空间,可作为占位符使用
- 比如实现简单的 Set
- Go 语言标准库没有提供 Set 的实现,通常使用 map 来代替。对于集合场景,只需要用到 map 的键而不需要值
-
使用 atomic 包
- 原理
- 锁的实现是通过操作系统来实现,属于系统调用,atomic 操作是通过硬件实现的,效率比锁高很多
- sync.Mutex 应该用来保护一段逻辑,不仅仅用于保护一个变量
- 对于非数值系列,可以使用 atomic.Value,atomic.Value 能承载一个 interface{}
- 原理
-
性能调优工具
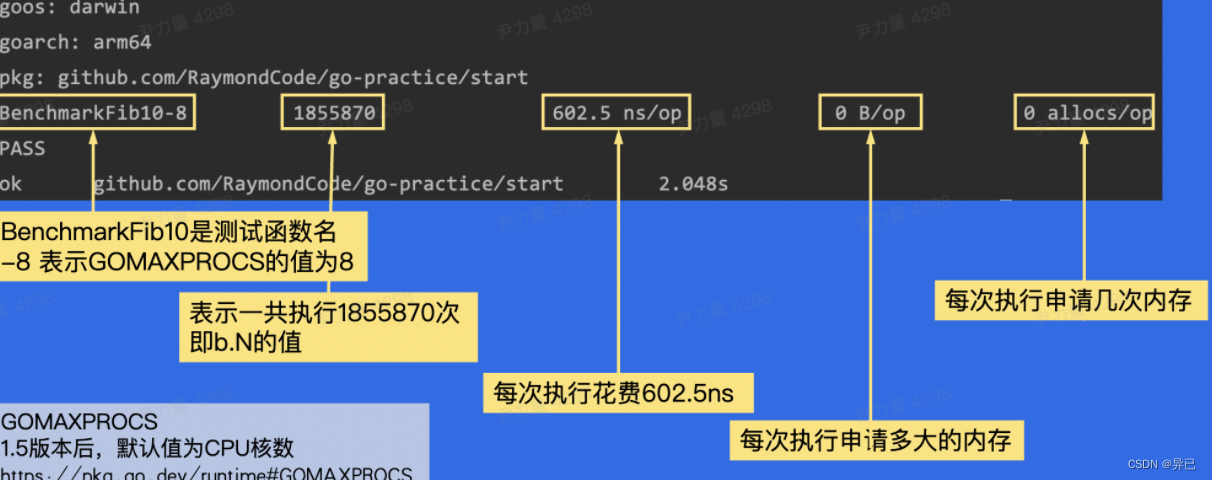
- pprof
推荐看这位大佬的博客(绘制火焰图)
https://blog.wolfogre.com/posts/go-ppof-practice/
图片均来自字节青训营课程,博客作为自己学习记录,如有侵权,麻烦联系删除。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









