









Hashmap底层数据结构
jdk1.7之前,Hashmap底层数据结构是数组+链表实现的,1.8之后采用了红黑树对Hashmap进行了优化。
数组
使用一-段连续存储单元存储数据。对于指定下标的查找,时间复杂度为O(1),对于一般的插入删除操作, 涉及到数组元素的移动,其平均复杂度为O(n)
链表
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
红黑树(>jdk7)
红黑树(Red Black Tree) 是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。
红黑树是在1972年由Rudolf Bayer发明的,当时被称为平衡二叉B树(symmetric binary B-trees)。后来,在1978年被 Leo J. Guibas 和 Robert Sedgewick 修改为如今的“红黑树”
红黑树是一种特化的AVL树(平衡二叉树),都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。
它虽然是复杂的,但它的最坏情况运行时间也是非常良好的,并且在实践中是高效的: 它可以在O(log n)时间内做查找,插入和删除,这里的n 是树中元素的数目。
HashMap原理
先明白几个变量
初始容量
initialCapacity 必须要是2的指数次幂,保证HashMap在扩容时安全需求和性能需求
加载因子
loadFactor = 0. 75(默认是0.75)
threshold = initialCapacity * loadFactor 扩容阀值
jdk1.7之前,Hashmap底层数据结构是数组+链表实现的,这两种数据结构是怎么配合使用的呢?如下图所示。

初始化数据结构
这是一个构造函数,可以看出数组的构建不是在构造方法中的,构造方法只是判断初识容量、和加载因子是否合法,非法就抛异常,最后的init()方法是一个空方法。

- 在第一次调用
put()方法时,会判断table是否初始化,第一次调用肯定是没有的,只是对一个成员属性进行了赋值,在inflateTable()方法中会进行一个数据结构的初始化。

注释中说明:Find a power of 2>=toSize,如果给的初始容量,在范围内但是不是2的幂次方,在做初始化时roundUpToPowerOf2()会进行更改扩容阈值。这里也可以看出table就是一个数组。


添加元素
-
hash()根据key的hashCode计算hash值,通过hash值跟数组的长度去进行计算,这个元素应该放在哪个索引位置。

这里为什么不直接使用hashCode()得到的值作为hash值呢?因为hashCode出现hash碰撞的几率很大,这样会使得链表长度增长,查询效率变低。所以这里通过“位扰动”(就是一系列的位运算等)的方式让hash散列,减少hash碰撞。返回值是一个int。 -
indexFor():通过hash值计算出在table数组的具体索引位置,这里采用的是hash值和table数组长度减一求与运算的方式。
为什么不是直接用hash值%16取模呢?因为首先效率没有二进制运算效率高(其实取模,计算机还是把数组转换为二进制去计算的),散列度也不高(散列度要求高是为了让数组的每个索引位置(坑位)都能均匀的分布元素)还有为什么要length-1。
因为数组下标定位:h & length-1 (数组初识长度为16) h就是计算出来的hash值
length不减1:
h 1010 1111 0001 0101 ……
length 0001 0000 0001 0000 ……
结果: 0000 0000 0001 0000 ……
不减一时发现结果要么是0要么是16,散列度差,而16时还会下标越界异常
length-1的情况:
h 1010 1111 0001 0101 ……
length-1 0000 1111 0000 1111 ……
结果: 0000 1111 0000 0101 ……
减一后计算结果就在0~15之间,这也就是为什么要求要容量必须是2的指数次幂的原因,这样就能刚好产生 0~N (每一位)的位置索引了。

- 找到对应索引下标时,会遍历该下标下的链表,如果该下标下的链表不为空,说明之前就发生过hash碰撞,就接着去判断:要插入元素的hash和当前遍历元素的hahs是否相等,且要插入元素的key和当前遍历元素的key是否相等,如果相等,那么就更新旧值为新值。
- 如果该下标下还没有链表存在,也就是这个待插入元素将是该下标的第一个元素,这就会去添加元素了,此时会调用
addEntry()添加。
这里可能会触发扩容机制,size>扩容阈值并且待插入位置也有元素,才能进行扩容,两个条件缺-一个都不会去扩容

createEntry():创建新的节点,并且采用头插法将该元素插入到改下标下的链表中。这里的bucketIndex就是该下表值,先是吧该下标的链表首元素记录在e中,然后在修改他赋上新元素。添加元素成功。
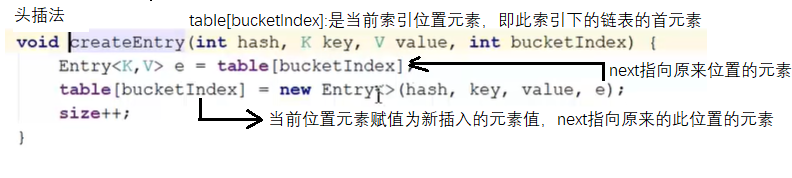
Entry结构如下:

数组扩容
addEntry()方法中,size>扩容阈值并且待插入位置也有元素,才能进行扩容,两个条件缺-一个都不会去扩容两个条件满足时,会触发扩容机制。
- 这里可以看出调用
resize(2*table.length),说明每次扩容默认是扩为原来数组长度的2倍,这个倍数也同样满足了2的指数幂这个条件。

- initHashSeenAsNeeded():返回一个Boolean值作为transfer方法的参数传递,是判断是否要进行重新hash的依据。

transfer():扩容后的新数组,保证元素不丢失,肯定要把原来数组的元素一一拷贝到新数组中,transfer方法就是做这个事情的。而死锁也是在这里产生的。该方法执行完后,元素位置倒置,因为在复制到新数组的时候,对应位置的链表复制也是采用头插法,而且是从下标位置开始遍历的(那么这个开始位置复制完成就变成尾了),类似于先进后出的道理一样,原来的头复制到新数组后会变成尾,而原来的尾复制到新数组后反而变成了头,就出现链表元素倒置。如果多线程下很有可能会让链表成环,出现死循环,即死锁现象。
代码中int i=indexFor(e.hash,newCapacity)会根据扩容后新的容量和要复制的元素的hash值再次求对应的下标位置。

原理图

源码执行图

jdk1.8优化了这个问题,但是官方建议在并发情况下还是不使用HashMap,因为可能导致元素丢失的情况,建议使用ConcurrentHashMap,他的底层实现和HashMap一样,只是引入了一些原子操作。















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









