









简介
model_zoo/model_zoo.py内定义了很多预训练模型和对应的超参数
目标检测COCO-detection:Faster R-CNN, RetinaNet, RPN and Fast R-CNN
实例分割COCO-InstanceSegmentation: Mask R-CNN
姿态检测COCO-Person-Keypoint: keypoint R-CNN
全景分割COCO-PanopticSegmentation: Panoptic FPN
python demo/demo.py --config-file configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml \
--input input1.jpg \
--output . \
--opts MODEL.WEIGHTS detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl
说明一下:
-config-file configs/COCO-… 读取 model 配置
–input input1.jpg 设置输入。 input1.jpg 位于根目录
–output . |设置输出路径,这里设为根目录
Detectron2库安装
Detectron2使用指南
深度学习 | Detectron2使用指南_JUST LOVE SMILE的博客-CSDN博客_detectron2使用文章目录1. Detectron2安装1.1 Linux1.2 Windows1.2.1 VS2019 C++编译环境1.2.2 pycocotools1.2.3 Detectron22. 自定义数据集2.1 关于COCO格式2.2 注册数据集2.3 可视化工具2.4 自定义数据增强3. 自定义模型3.1 特征提取网络(backbone)3.2 候选框生成器(proposal_generator)3.3 检测器(roi_heads)3.4 模型框架(meta_arch)4. 模型训练4.1 默认训练4.2 https://blog.csdn.net/qq_43701912/article/details/123590274?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-123590274-blog-116749084.pc_relevant_default&spm=1001.2101.3001.4242.1&utm_relevant_index=2Detectron2的模型是分模块的,它将目标检测模型拆分为了4个核心模块:
https://blog.csdn.net/qq_43701912/article/details/123590274?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-123590274-blog-116749084.pc_relevant_default&spm=1001.2101.3001.4242.1&utm_relevant_index=2Detectron2的模型是分模块的,它将目标检测模型拆分为了4个核心模块:backbone,proposal_generator,roi_heads以及meta_arch
在detectron2/modeling/backbone 里有FPN,RegNet 和ResNet
detectron2/modeling里还有
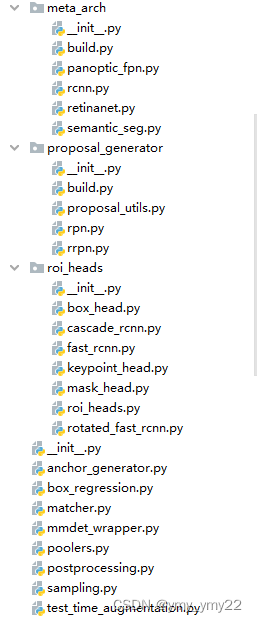
在projects里还有一些其他的任务网络

训练
tools/内有lightning_train_net, plain_train_net, train_net
tools/train_net.py --config-file configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml --num-gpus 1 SOLVER.IMS_PER_BATCH 2 SOLVER.BASE_LR 0.0025制作自己的Detectron2预训练模型 - 知乎项目初期样本量较少,随着项目进展,样本数量不断增多,同一个项目需要不断迭代,训练多次,不用每次训练从0开始,可以基于前面的模型进行微调,缩短训练时间。 方法如下: import torch # 默认加载 net = torch.l… https://zhuanlan.zhihu.com/p/147336249detectron2 下载预训练模型中断导致无法运行_sysu_first_yasuo的博客-CSDN博客在使用detectron2的R101的faster-rcnn和retinanet时如果会自动加载预训练的R101 backbone解决方法有两个,一个是覆盖yaml中model weight的设定,设为空字符串:cfg.MODEL.WEIGHTS = ''另一个是用vpn把这个backbone下载下来再弄到本地,同样要修改cfg.MODEL.WEIGHTS为你下载下来的文件的地址...https://blog.csdn.net/weixin_44326452/article/details/106070988?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~aggregatepage~first_rank_ecpm_v1~rank_v31_ecpm-3-106070988-null-null.pc_agg_new_rank&utm_term=detectron2%E6%80%8E%E6%A0%B7%E9%80%89%E6%8B%A9%E9%A2%84%E8%AE%AD%E7%BB%83%E6%A8%A1%E5%9E%8B&spm=1000.2123.3001.4430Detectron2 “快速开始” Detection Tutorial Colab Notebook 详细解读_Yukaz123的博客-CSDN博客Detectron快速上手官方 Colab Notebook 上 Getting Started 部分阅读:1. 使用预训练的Detectron2模型下载一张图片,我们需要创建detectron2 config,随后根据config创建一个Default Predictor去进行单张图片推理。cfg = get_cfg() # 获取 Default Config# 根据 mask_rcnn_R_50_FPN_3x.yaml 的配置文件更新 configcfg.merge_from_file(mohttps://blog.csdn.net/weixin_42174674/article/details/116289893
https://zhuanlan.zhihu.com/p/147336249detectron2 下载预训练模型中断导致无法运行_sysu_first_yasuo的博客-CSDN博客在使用detectron2的R101的faster-rcnn和retinanet时如果会自动加载预训练的R101 backbone解决方法有两个,一个是覆盖yaml中model weight的设定,设为空字符串:cfg.MODEL.WEIGHTS = ''另一个是用vpn把这个backbone下载下来再弄到本地,同样要修改cfg.MODEL.WEIGHTS为你下载下来的文件的地址...https://blog.csdn.net/weixin_44326452/article/details/106070988?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~aggregatepage~first_rank_ecpm_v1~rank_v31_ecpm-3-106070988-null-null.pc_agg_new_rank&utm_term=detectron2%E6%80%8E%E6%A0%B7%E9%80%89%E6%8B%A9%E9%A2%84%E8%AE%AD%E7%BB%83%E6%A8%A1%E5%9E%8B&spm=1000.2123.3001.4430Detectron2 “快速开始” Detection Tutorial Colab Notebook 详细解读_Yukaz123的博客-CSDN博客Detectron快速上手官方 Colab Notebook 上 Getting Started 部分阅读:1. 使用预训练的Detectron2模型下载一张图片,我们需要创建detectron2 config,随后根据config创建一个Default Predictor去进行单张图片推理。cfg = get_cfg() # 获取 Default Config# 根据 mask_rcnn_R_50_FPN_3x.yaml 的配置文件更新 configcfg.merge_from_file(mohttps://blog.csdn.net/weixin_42174674/article/details/116289893
常用命令
tools/train_net.py --config-file configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x_VCM.yaml --num-gpus 1
python demo\demo.py --input input.jpg
python tools/analyze_model.py --task flop --config-file configs/COCO-Detection/faster_rcnn_R_50_C4_1x.yamlmmdet转detectron2
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
from collections import OrderedDict
import torch
import argparse
from collections import OrderedDict
import mmcv
import torch
arch_settings = {50: (3, 4, 6, 3), 101: (3, 4, 23, 3)}
def convert_bn(blobs, state_dict, caffe_name, torch_name, converted_names):
# detectron replace bn with affine channel layer
state_dict[torch_name + '.bias'] = blobs[caffe_name +'.bias']
state_dict[torch_name + '.weight'] = blobs[caffe_name +'.weight']
# bn_size = state_dict[torch_name + '.weight'].size()
state_dict[torch_name + '.running_mean'] = blobs[caffe_name +'.running_mean']
state_dict[torch_name + '.running_var'] = blobs[caffe_name + '.running_var']
converted_names.add(caffe_name + '.bias')
converted_names.add(caffe_name + '.weight')
converted_names.add(caffe_name +'.running_mean')
converted_names.add(caffe_name + '.running_var')
def convert_conv_fc(blobs, state_dict, caffe_name, torch_name, converted_names):
state_dict[torch_name + '.weight'] = blobs[caffe_name +'.weight']
converted_names.add(caffe_name + '.weight')
if caffe_name + '.bias' in blobs:
state_dict[torch_name + '.bias'] = blobs[caffe_name +'.bias']
converted_names.add(caffe_name + '.bias')
def convert(src, dst, depth):
"""Convert keys in detectron pretrained ResNet models to pytorch style."""
# load arch_settings
if depth not in arch_settings:
raise ValueError('Only support ResNet-50 and ResNet-101 currently')
block_nums = arch_settings[depth]
# load caffe model
caffe_model = torch.load(src, map_location='cpu') #mmcv.load(src, encoding='latin1')
blobs = caffe_model['blobs'] if 'blobs' in caffe_model else caffe_model
blobs = blobs['state_dict']
# convert to pytorch style
state_dict = OrderedDict()
converted_names = set()
convert_conv_fc(blobs, state_dict, 'roi_head.bbox_head.fc_cls', 'roi_heads.box_predictor.cls_score', converted_names)
convert_conv_fc(blobs, state_dict, 'roi_head.bbox_head.fc_reg', 'roi_heads.box_predictor.bbox_pred', converted_names)
convert_conv_fc(blobs, state_dict, 'roi_head.bbox_head.shared_fcs.0', 'roi_heads.box_head.fc1', converted_names)
convert_conv_fc(blobs, state_dict, 'roi_head.bbox_head.shared_fcs.1', 'roi_heads.box_head.fc2', converted_names)
convert_conv_fc(blobs, state_dict, 'rpn_head.rpn_conv', 'proposal_generator.rpn_head.conv', converted_names)
convert_conv_fc(blobs, state_dict, 'rpn_head.rpn_cls', 'proposal_generator.rpn_head.objectness_logits', converted_names)
convert_conv_fc(blobs, state_dict, 'rpn_head.rpn_reg', 'proposal_generator.rpn_head.anchor_deltas', converted_names)
convert_conv_fc(blobs, state_dict, 'backbone.conv1', 'backbone.bottom_up.stem.conv1', converted_names)
convert_bn(blobs, state_dict, 'backbone.bn1', 'backbone.bottom_up.stem.conv1.norm', converted_names)
for i in range(0, 4):
convert_conv_fc(blobs, state_dict, f'neck.lateral_convs.{i}.conv', f'backbone.fpn_lateral{i+2}', converted_names)
convert_conv_fc(blobs, state_dict, f'neck.fpn_convs.{i}.conv', f'backbone.fpn_output{i + 2}', converted_names)
for i in range(1, len(block_nums) + 1):
for j in range(block_nums[i - 1]):
if j == 0:
convert_conv_fc(blobs, state_dict, f'backbone.layer{i}.{j}.downsample.0', f'backbone.bottom_up.res{i + 1}.{j}.shortcut', converted_names)
convert_bn(blobs, state_dict, f'backbone.layer{i}.{j}.downsample.1', f'backbone.bottom_up.res{i + 1}.{j}.shortcut.norm', converted_names)
for k in range(1, 4):
convert_conv_fc(blobs, state_dict, f'backbone.layer{i}.{j}.conv{k}', f'backbone.bottom_up.res{i + 1}.{j}.conv{k}',converted_names)
convert_bn(blobs, state_dict, f'backbone.layer{i}.{j}.bn{k}', f'backbone.bottom_up.res{i + 1}.{j}.conv{k}.norm', converted_names)
# check if all layers are converted
for key in blobs:
if key not in converted_names:
print(f'Not Convert: {key}')
# save checkpoint
checkpoint = dict()
checkpoint['model'] = state_dict
torch.save(checkpoint, dst)
def main():
parser = argparse.ArgumentParser(description='Convert model keys')
parser.add_argument('src', help='src detectron model path')
parser.add_argument('dst', help='save path')
parser.add_argument('depth', type=int, help='ResNet model depth')
args = parser.parse_args()
convert(src, dst, depth)
if __name__ == '__main__':
main()
注意:coco数据集的PIXEL_STD需要修改

















 2026
2026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









