






 文章探讨了如何通过余弦注意力和残差后正则化提高大规模视觉模型的稳定性,以及如何通过对数空间位置偏置和自监督预训练方法如SimMIM减少对有标记数据的依赖。Swin-TV2模型在视觉任务中取得SOTA成绩,同时文章还提及了内存优化技术如零冗余优化器和序列化自注意力计算。
文章探讨了如何通过余弦注意力和残差后正则化提高大规模视觉模型的稳定性,以及如何通过对数空间位置偏置和自监督预训练方法如SimMIM减少对有标记数据的依赖。Swin-TV2模型在视觉任务中取得SOTA成绩,同时文章还提及了内存优化技术如零冗余优化器和序列化自注意力计算。
1.引言
作者提出,目前已经证明大规模的模型可以显著提升NLP问题的表现,本文旨在探索一个大规模的计算机视觉模型,并且着手解决以下三类问题:大规模视觉模型的不稳定性、预训练使用的数据与微调使用的数据之间存在的分辨率差异性问题以及对更大规模的有标记数据需求问题 作者提出,目前已经证明大规模的模型可以显著提升nLP问题的表现,本文旨在探索一个大规模的计算机视觉模型,并且着手解决以下三类问题:大规模视觉模型的不稳定性、预训练使用的数据与微调使用的数据之间存在的分辨率差异性问题以及对更大规模的有标记数据需求问题。
| 技术 | 解决问题 |
| 使用余弦attention的残差后正则方法 | 提升模型稳定性 |
| 对数空间下的连接位置偏置方法 | 更有效的将低分辨率数据下训练得到的模型迁移到高分辨率数据的下游任务 |
| 自监督的预训练方法,SimMIM | 减少对有标记数据的大量需求 |
2.三个问题和改进思路
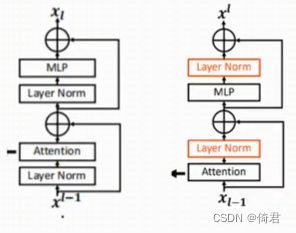
2.1 使用余弦attention的残差后正则方法
大型视觉模型训练过程中的不稳定性,在大型模型中,跨层激活振幅的差异变得显著更大。仔细观察原始架构会发现,这是由直接添加回主分支的残差单元的输出引起的。结果是激活值是逐层累积的,因此更深层的振幅明显大于早期层的振幅。
作者认为这是因为,在一个attention前应用LayerNorm,会使得到的输出直接相加传入后面网络,这样一来层间的activaion value差距就会变大。于是就把LN放在了attention后面,在进行残差连接之前起到一个归一化的作用。而且在训练最大的模型时,每六层就添加一个额外的LN层,使模型更稳定。但由于缺少了前面的LN会导致算出的QKT偏大或偏小,在经过softmax后会变得不那么温和,导致系数更加极端(某几个v起决定作用)
Sim(q,kj) = cos(q,kz)/T+Bij,
其中B是像素i与j之间的相对位置偏差;T是一个可学习的标量,不分头和层,T大于0.01。余弦函数是自然归一化的,因此可以有较小的注意值。
2.2 对数空间下的连接位置偏置方法
许多下游视觉任务,如对象检测和语义分割,需要高分辨率的输入图像或大的注意力窗口。低分辨率预训练和高分辨率微调之间的窗口大小变化可能相当大。利用对数间隔连续位置偏移(LogCPB)将低分辨率图像预先训练的模型转移到高分辨率输入的下游任务。
在Swin-TV1中使用的相对位置编码将位置bias参数化并且设置为可学习。
Attention(Q, K,V) =SoftMax(QKT /√d+BV
在Swin-T v1中使用相对位置编码对每个窗口中patch的相对位置关系进行了编码。公式中的B即为相对位置编码矩阵。
当预训练和fine-tune图片或窗口尺寸改变时,位置编码是不匹配的,采用bi-cubic方法,但此方法是次优的,而且在线性空间做外推( extrapolation),当尺寸差距过大时,外推比是很大的。作者首先把V1中可直接学习的相对位置bias改为使用一个meta网络(两层MLP中间一层Relu)预测相对位置bias,这样避免了使用插值法迁移B
B(A.z,Ag)= G(Ar,Ay)
但是当分辨率差别过大时仍然是有较大的预测外推比,作者通过一个映射把相对位置bias投影到对数空间。

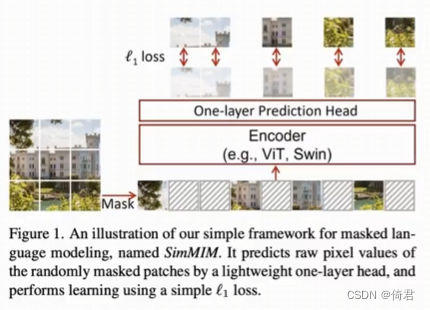
2.3 自监督的预训练方法,SimMIM
本文采用了SimMIM的自监督方法,在7000万张图片的数据集(是之前工作使用的JFT-3B数据集的1/40))上训练了一个30亿参数的模型。并在4个视觉benchmark上达到了SOTA。
与MAE不同SimMIM在随机掩码图像后,把被掩码和未被掩码的patch全都输入Encoder,而且直接采用轻量级的一层线性预测头预测。
3.其余改进技术
本文还采用了一些技术来节省GPU的内存。
3.1 零冗余优化器(Zero-Redundancy Optimizer)
零冗余优化器(Zero-Redundancy Optimizer),将模型参数和相应的优化状态分割并分配到多个gpu中,这大大降低内存消耗。
3.2 激活检验点(Activation check-pointing)
激活检验点(Activation check-pointing),是一种通过清除某些层的激活值并在反向传递期间重新计算它们来减少内存使用的技术。实际上,这以额外的计算时间换取了内存使用的减少。本文中使用这项技术使训练速度慢了30%。
3.3 序列化自注意力计算(Sequential self-attention computation)
序列化自注意力计算(Sequential self-attention computation),作者发现,当图像的分辨率为1536×1536,窗口大小为32×32时,常规的A100gpu(40GB内存)仍然无法训练,自注意模块构成了一个瓶颈。为了缓解这一问题,本文按顺序实现了自注意计算,而不是使用之前的批处理计算方法。这种优化应用于前两个阶段的层,对整体训练速度的影响很小。
4.总结
通过本文提出的技术可以训练一个30亿参数的模型,而且可以用1,536×1,536分辨率的图片进行训练。res-post-norm方法和cosine attention可以更容易的把模型推向更大规模。对数空间的连续位置偏置方法可以更高效的在不同的windows size之间做迁移。Swin-TV2模型在四个代表性的视觉benchmark上创造了新的记录。作者希望在这个方向继续努力,可以弥补CV模型与语言模型之间的差距,并且对两个领域的联合模型发展作出贡献。
5.缺陷分析
作者沿用了SwinV1的架构,仅对attention、位置编码、LayerNorm的位置进行了修改,并未对架构进行修改,创新性不强。此外,使用cosine attention会使计算量增加。同时内存占用也仍是问题,尽管作者使用了一些技术来降低内存占用,但是是以牺牲训练速度为代价的。
ps:借鉴参考源于某组会PPT以及相关视频讲解。















 78
78











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









