






文生音乐
模型介绍
环境准备
这里使用的运行环境是 ComfyUI,请将ComfyUI升级到最新版本。
没有ComfyUI的同学建议先使用云环境来运行,无需复杂且容易出错的环境配置,待有应用价值了,再到本地折腾也不迟。我的云镜像:好易智算
模型下载后放到基础模型目录,一般是 ComfyUI/models/checkpoints 目录。
模型下载后放到clip目录,一般是 ComfyUI/models/clip 目录。
访问 huggingface 不方便的同学可以发消息“文生音频”到我的公众号“萤火AI绘画”即可获取相关模型。
工作流
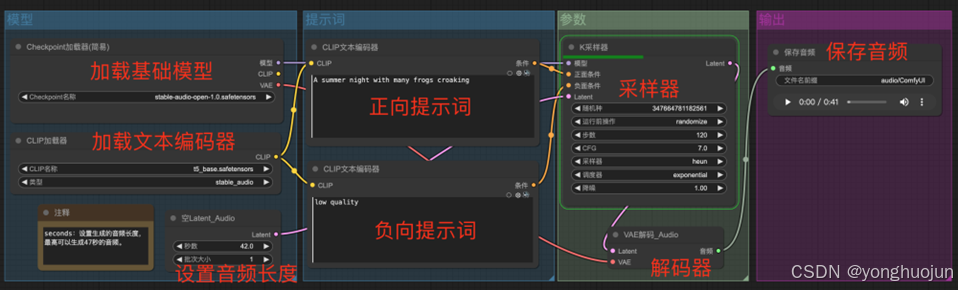
- steps: 生成音频步数:10-150
- cfg_scale: 取值范围是1到15,默认值为6,值越高,生成的内容通常更紧密地符合给定的描述,但可能失去一些创造性。
- sampler_type: 采样类型,有dpmpp-3m-sde、dpmpp-2m-sde、heun、lms、dpmpp-2s-ancestral、dpm-2、dpm-fast六种采样类型。
资源下载
本文用到的插件、提示词、工作流和模型都已经整理好,下载地址:夸克网盘分享
另外我还免费分享了几十条ComfyUI工作流,给我的公/众\号 “萤火AI绘画” 发消息 “工作流” 即可获取。
如果你需要全面学习AI绘画,获取更加好用的高级工作流,请点击下方链接或者扫码订阅小册:小报童

















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









