






本文主要介绍使用virtualenv库生成venv,进而部署/运行Stable-Audio-Open-1.0文生音频模型的方法。
1. 在线体验
本文代码已部署到百度飞桨AI Studio平台,以供大家在线体验。
项目链接:Stable Audio 在线体验
注意:Stable-Audio-Open-1.0 (默认fp32模式)显存峰值占用接近15GB。
2. 环境部署
python版本:3.10.10
virtualenv环境部署代码如下:
git clone https://github.com/Stability-AI/stable-audio-tools.git
cd stable-audio-tools
pip install -U virtualenv
python -m virtualenv venv
source venv/bin/activate
pip install stable_audio_tools安装stable_audio_tools库会自动安装以下依赖库:
aeiou==0.0.20
alias-free-torch==0.0.6
auraloss==0.4.0
descript-audio-codec==1.0.0
einops==0.7.0
einops-exts==0.0.4
ema-pytorch==0.2.3
encodec==0.1.1
gradio>=3.42.0
huggingface_hub
importlib-resources==5.12.0
k-diffusion==0.1.1
laion-clap==1.1.4
local-attention==1.8.6
pandas==2.0.2
pedalboard==0.7.4
prefigure==0.0.9
pytorch_lightning==2.1.0
PyWavelets==1.4.1
safetensors
sentencepiece==0.1.99
s3fs
torch>=2.0.1
torchaudio>=2.0.2
torchmetrics==0.11.4
tqdm
transformers
v-diffusion-pytorch==0.0.2
vector-quantize-pytorch==1.9.14
wandb==0.15.4
webdataset==0.2.48
x-transformers<1.27.03. 模型下载
原始链接:https://huggingface.co/stabilityai/stable-audio-open-1.0
镜像链接:https://hf-mirror.com/stabilityai/stable-audio-open-1.0 (需登录下载)
镜像链接:https://hf-mirror.com/audo/stable-audio-open-1.0 (可直接下载)
这里采用wget下载模型文件(4.5GB),下载代码:
mkdir stable-audio-open-1.0
cd stable-audio-open-1.0
wget https://hf-mirror.com/audo/stable-audio-open-1.0/resolve/main/LICENSE
wget https://hf-mirror.com/audo/stable-audio-open-1.0/resolve/main/model.safetensors
wget https://hf-mirror.com/audo/stable-audio-open-1.0/resolve/main/model_config.json
wget https://hf-mirror.com/audo/stable-audio-open-1.0/resolve/main/README.md4. 运行
Stable-Audio-Open-1.0的运行很简单,激活虚拟环境后运行 stable-audio-tools/run_gradio.py 文件即可(可以通过 --model-config /path/to/model/config --ckpt-path /path/to/wrapped/ckpt 从自定义路径加载 model_config.json 和 model.safetensors 文件)。
代码如下:
cd stable-audio-tools
source venv/bin/activate
python run_gradio.py --model-config stable-audio-open-1.0/model_config.json --ckpt-path stable-audio-open-1.0/model.safetensors5. 文生音频示例
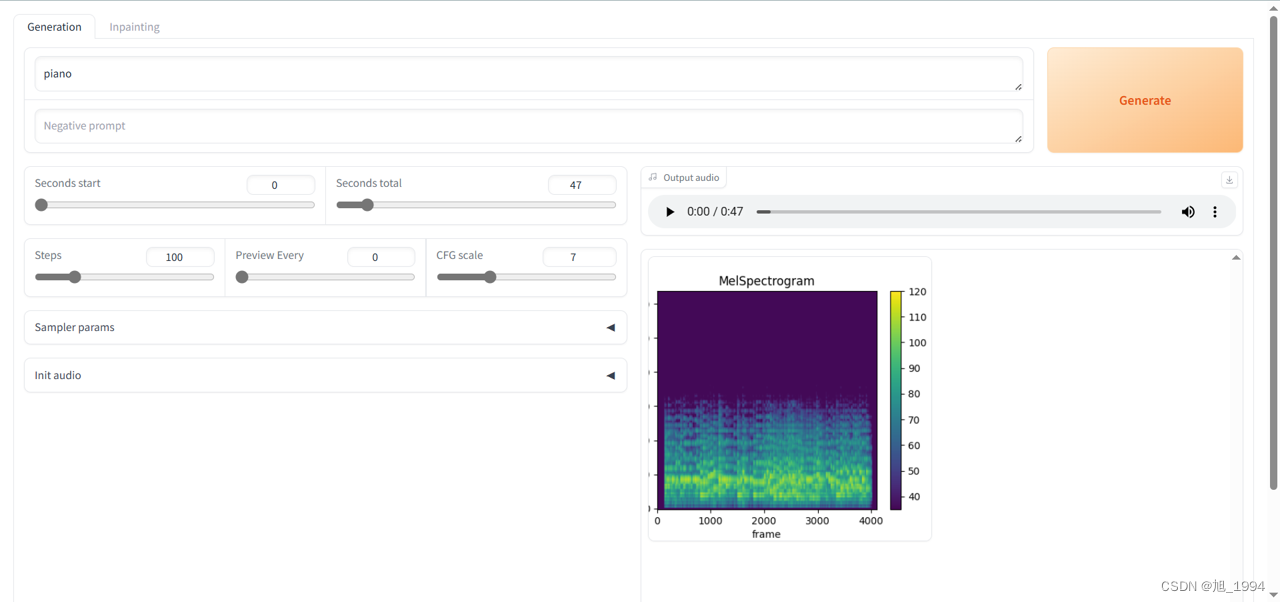
这里尝试使用乐器名称作为提示词,生成音频文件见文章绑定资源(好像非VIP无法下载,建议去百度飞桨平台在线体验)。

















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









