









23年8月北邮的论文“Rethinking Mobile AI Ecosystem in the LLM Era”。
智能手机已经发展成为托管大量本地深度学习模型的中心。推动这项工作的一个关键实现是这些模型之间明显的碎片化,其特征是不同的体系结构、运算符和实现。这种碎片化给硬件、系统设置和算法的全面优化带来了巨大负担。
在大型基础模型最近取得进展的推动下,这项工作为移动人工智能引入了一种开创性的范式:移动操作系统和硬件之间的协作管理方法,监督一个能够服务于广泛移动人工智能任务(如果不是全部)的基础模型。这个基础模型位于NPU中,不受应用程序或操作系统修订的影响,类似于固件。同时,每个应用程序都提供了一个简洁、离线微调的“适配器”,专门用于不同的下游任务。从这个概念中出现了一个被称为M4的具体实例。它融合了精选的公开可用的大语言模型(LLM),促进了动态数据流。这一概念的可行性通过创建一个详尽的基准来证明,该基准包括跨越50个数据集的38个移动人工智能任务,包括计算机视觉(CV)、自然语言处理(NLP)、音频、传感和多模态输入等领域。跨越这一基准,M4展示了其深刻的性能。
M4:可组合的移动基础模型,一个多模态移动基础模型的架构设计和实现。与CoDi等直接使用(Nx)重编码器来对齐多模态输入数据和(Mx)重解码器来生成特定数据格式的现有方法不同,M4在两者之间添加了一个主干模块(“窄腰”),该模块理解每个下游任务并解释其原因。通过这种“N-1-M”设计,与传统的“N-M”架构相比,M4能够实现更好的精度和参数效率。此外,M4可以根据其特征(输入/输出模态、复杂理解的需要等)被各种任务部分激活。完全原型化M4,只有HuggingFace[90]公开的预训练模型,这保证了M4的可重复性,也证明了它与现有LLM生态系统的兼容性。总的来说,M4包含9.2B的参数,需要7.5GB的峰值内存。这样的尺寸现在只有在高端移动设备上才能承受得起,但对于内存/存储容量每年都在显著增加的更多公共设备来说,这很快就是可行的。
mAIBench:一个全面的移动人工智能基准。M4目前包括38个重要的移动AI任务和50个经典数据集。任务包括五种不同的输入/输出数据模态(视觉、文本、音频、IMU和混音)。每个任务还与特定于任务的模型相链接,该模型代表前LLM时代的DNN(例如,用于图像分类的ResNet-152[26]和用于输入tokens预测的LSTM[29])。
如图是M4的架构图:其包括三个部分
多模态嵌入是通过将多模态输入数据转换为统一表示(即矢量)来对齐不同模态的内容。它通常被实现为每个模态的一组transformer编码器[20],除了音频具有两个独立的编码器来区分上下文信息(例如,背景噪声、说话者情绪)和口语(例如,自动语音识别)。
基础主干是理解和推理输入数据。它封装了丰富的知识来理解复杂的嵌入数据,执行特定任务的推理,并为生成器生成易于理解的输出。由于语言已被公认为最具代表性的数据类型[13,58,81],因此它使用了在大量文本数据集上训练的基于解码器架构。主干是M4最重(计算)的部分。
多模态嵌入是将基础主干的输出调整为任务特定的数据格式。对于分类任务,它只是一个具有softmax层的MLP;对于图像任务,它是一个stable diffusion模型[68]。
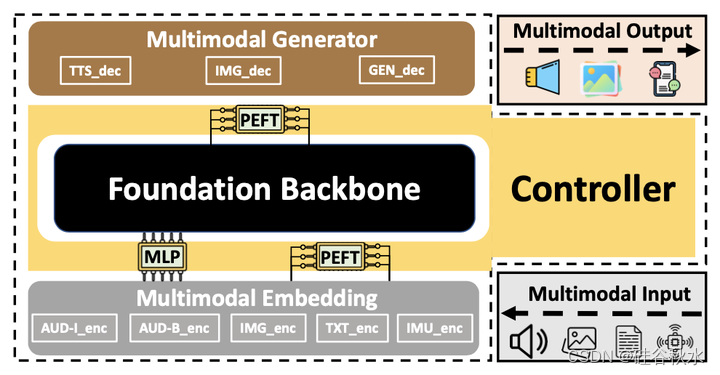
M4包含三个可训练部分,可针对下游移动人工智能任务进行微调:两个PEFT模块分别插入到多模态嵌入和基础主干中;以及一个MLP层,使多模态嵌入的输出适应于基础主干的所需表示。在实验中,用LoRA作为默认的PEFT方法,但也报告了其他PEFT方法的结果。与M4的预训练部分相比,可训练参数大小微不足道,也比传统的最先进DNN小得多。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









