







23年9月来自MIT和MIT-IBM实验室的论文“Large Language Model Routing with Benchmark Datasets”。
开源大语言模型 (LLM) 和基准数据集的数量正在迅速增长,可用于LLM性能比较。虽然有些模型在这些基准测试中占据主导地位,但没有一个模型通常能够在所有任务和用例中实现最佳准确率。这项工作的目的是,从一组模型中为新任务选择最佳 LLM。提出了一种新公式,其中基准数据集被重新用于学习 LLM 选择的“路由器”模型,并且该问题可以简化为二元分类任务集。分析从各种基准数据集中学习模型路由器的实用性和局限性,其中不断提高任何单一模型执行所有任务的性能。
选择最佳模型或模型选择,是统计学和机器学习中的经典话题(Bishop & Nasrabadi,2006;Hastie,2009;Raschka,2018)。然而,典型的问题设置却大不相同:交叉验证等经典方法旨在估计在总体分布的样本上训练模型的总体误差。换句话说,目标是找到分布内(ID)测试数据的最佳模型,即从与训练数据相同分布中采样的数据。对于 LLM 来说,“训练”数据的概念相当难以捉摸,因为它们通常在具有数万亿个 token 海量数据集上进行训练,并具有一个简单的下一个 token 预测任务(Radford,2019;Brown,2020)。然而,评估它们的任务通常更具结构性,例如分类和问答,并且特定于训练数据中可能充分或不充分表示的领域。此外,k - fold 交叉验证等技术需要多次训练模型,这对于 LLM 来说是不可行的。
认识到模型选择方法对于分布内(ID)测试数据的局限性(Gulrajani & Lopez-Paz,2021;Koh,2021),最近的研究提出多种方法来选择部署在可能与训练数据不同数据上的模型。这些方法依赖于诸如自举(Xu & Tibshirani,2022)、重加权(Chen,2021b;Maity,2023)、模型一致性或集成(Jiang,2021;Chen,2021a;Ng,2023)或将模型准确率分布与置信度阈值对齐(Guillory,2021;Garg,2022;Yu,2022)等想法。这些方法中的大多数都很难扩展到 LLM 的生成用例;有些需要训练多个模型,有些需要与新任务相关的明确定义的分布内(ID)数据。
先前关于选择 LLM 的工作,主要考虑选择一个能够为给定输入产生最佳生成的 LLM。Liu & Liu (2021)、Ravaut (2022)、Jiang (2023) 训练专用的评分或排名模型,这些模型可应用于模型生成。这些方法需要使用每个候选 LLM 生成输出才能做出决策,如果候选 LLM 数量庞大,则计算量过大。FrugalGPT (Chen,2023) 依次调用 LLM,直到专用的评分模型认为该生成是可接受的。先前的工作需要训练数据,这些数据足以代表每个感兴趣的任务和领域,训练相应的排名和评分模型。
让 {xd1, . . . , xdnd } 成为 D 任务的输入集。每个输入文本 xdi 对应一个参考答案 rid,即对应输入的理想生成。最后,有一个度量 Fd(x,o,r) 可以依赖于任务,并测量输入 x 的响应 o 与参考 r 的对应程度。要在基准上测试 LLMm,m ∈ {1,…,M},对于每个任务 d = 1, . . . , D,其响应生成 {odim = LLMm (xdi)} 并与相应的参考进行比较以获得性能指标 {fdim = Fd(xdi , odim, rdi )}。此时,大多数基准研究将对性能指标取(加权)平均值,并为每个 LLM 报告一个分数,对它们的性能进行排名。相反,本文重新使用这些评估结果来制定监督学习问题,以便根据各种 LLM 在数据点和任务上的表现更好地了解其优势和劣势。
该文将模型优势的学习视为二元监督学习任务来精确表达这个想法,其中特征是跨任务的样本输入嵌入,标签是模型在相应输入上是否“表现良好”,例如生成正确的类标签、正确回答问题或足够好地遵循输入指令。如图所示:从基准数据集中了解候选 LLM(用相应颜色标记)在各种任务(表情符号:问答、推理、总结等)和域(每个方框内的 4 个部分:金融、法律、常识等)上的优势。为每个 LLM 训练一个二元分类器(图的上半部分)来实现这一点。对于新任务,用这些二元分类器对每个 LLM 进行评分,并为用户推荐一个 LLM(图的下半部分)。
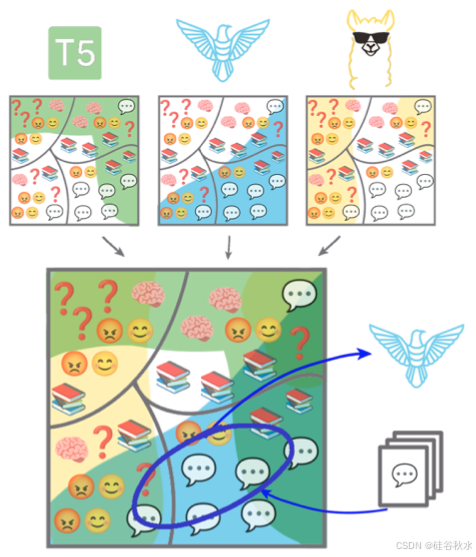
目标是为每个 LLM(m = 1,…,M)学习一个简单的路由函数 gm(x),它可以预测 {f d′im },即相应 LLM 在新任务 d‘ 上的表现。然后,为这项任务选择最佳 LLM 就很简单。为了提高测试时的效率,将路由器 {gm} 要求为仅依赖于输入 x。这与大多数先前关于 LLM 路由的研究形成对比,这些研究首先使用每个候选 LLM 获得生成,然后选择最佳模型(Liu & Liu,2021;Ravaut,2022;Jiang,2023)。由于有成千上万个开源 LLM,因此在测试时为每个输入获得每个 LLM 生成是不可行的。
为了完成问题的表述,用 y(x, m) ∈ {0, 1} 表示模型 m 在输入 x 上的“正确性”。正确性的评估方法如下:使用 LLM m 对输入 xdi 生成响应 odim,将其与相应的参考 rdi 进行比较,如果模型的响应足够好,即 fdim > ηd,则输出 1,否则输出 0,其中 ηd 是某个阈值,可以是特定于任务和/或指标的。对于分类或多项选择问答等任务,y(xdi,m) = fdim,而对于摘要和指导跟随任务中使用的各种评估指标(Zhang,2020;Sellam,2020;Yuan,2021),正确性的概念有助于解释流行指标和任务难度级别的异质性。
为训练一个 LLM 正确性的预测器,求解以下优化问题:设 gm 是任何概率分类器,估计P (y(x, m) = 1|x),而 l 是交叉熵损失

训练正确性预测器时的一个重要考虑因素,是它们泛化分布外 (OOD) 数据的能力,因为目标是估计 LLM 在训练期间未见过新任务 d′ 上的表现。给定来自多个域的数据来训练预测器,这些数据需要推广到未见过的域,这确实是 ML 文献中一个活跃的研究领域。例如,Sun & Saenko (2016);Arjovsky (2019) 提出在用来自多个域的数据进行训练改进 OOD 泛化,而 Koh (2021) 提出 OOD 泛化的基准,展示该问题在各种应用中的挑战性。
这项工作用一个简单的模型作为正确性预测器:用句子transformer (Reimers & Gurevych, 2019) 嵌入所有输入,并使用 k-最近邻分类器 (Cover & Hart, 1967) 作为 {gm}。 kNN 是一个简单的非参数分类器,在多个任务中拟合 LLM 正确性的复杂决策边界,无需进行大量的超参调整。选择这种方法来学习正确性预测器,强调即使使用基本方法也能从基准中学习的实用性,而是专注于问题的特定问题,这个问题在之前的 OOD 泛化工作中尚未被研究过:能否使用不完善的正确性预测器来提高 LLM 路由的质量?
LLM 路由的目标是确定一个 LLM,在给定来自该任务输入 {xd′ }的情况下,在该任务上正确率最高:
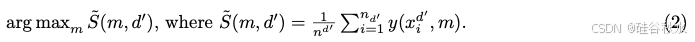
最直观的估计就是使用正确性预测器:

但是在 OOD 数据上准确估计 P(y|x)(即标定)具有挑战性(Ovadia,2019)。同时,即使类概率估计得不好,gm 在对预测概率进行阈值化后仍可能产生准确的预测,这在神经网络中经常发生(Guo,2017)。
然而,这个估计没有考虑到 gm 的潜在“缺陷”,即任务 d‘ 的 OOD 数据准确率较低。为了解决这个问题,对预测 gm 的分布外置信度进行建模:
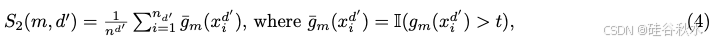
一个简单的OOD置信度模型,将模型准确性计算如下

即 p(d‘, m) ∈ [0, 1] 是 g 对任务 d‘ 中的某个数据点进行正确预测的概率。上述模型可以简述如下:

在这个简单(近似)的模型中,假设 p(d′,m) 在对任务 d‘ 进行调节后不依赖于输入 x。该假设类似于线性回归模型中的同性化误差项假设,并允许将 p(d′,m) 解释为 g 对任务 d’ 数据的边际/整体准确度。
可以将估计 p(d′,m) 的问题视为监督学习任务,利用任务划分的优势。具体来说,为每个任务分配一个任务描述子 u(d),用于测量从任务 d 到其他可用任务组合的数据距离。然后,收集 p(d, m) 的值,即 gm 在 d 上的准确度,并拟合非参数回归模型以根据 u(d) 预测 p(d, m)。在测试时,根据输入 {xdi′} 计算新任务 d′ 的 u(d′),并使用拟合的回归模型预测 p(d′,m)。一般来说,可以考虑更复杂、更高维的任务描述子 u(d),但在这里,为简单起见,将其保持为一维,并使用一个高斯核平滑器(也称为 Nadaraya-Watson 估计器)作为非参数回归器。
最后,给定 LLM 正确性模型,即公式 (6),S(m, d‘) 是一个随机变量,分布为两个伯努利随机变量(缩放)的一个和。为了得出 LLM 路由的最终分数,取其期望值:
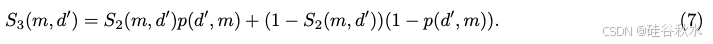
当选择具有 S3 分数的 LLM 时,会根据正确性模型(6)考虑 arg max 标准的替代方案,当不确定候选模型是否会更好时,该方案在基准数据集中取平均默认为最好模型:
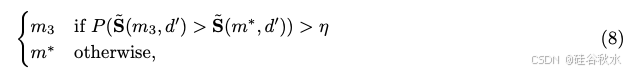
其中 η = 0.6,最佳模型 m*如下



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









