









23年12月来自Nvidia公司、Wisconsin-Madison分校,Michigan大学和斯坦福大学的论文“Dolphins: Multimodal Language Model For Driving“。
寻求能够以类人的理解和响应能力在复杂的现实世界场景中导航的自动驾驶车。这篇论文介绍Dolphins,一种视觉语言模型(VLM),旨在吸收类人能力,作为一种对话式驾驶助手。Dolphins擅长处理包括视频(或图像)数据、文本指令和历史控制信号的多模态输入,生成与所提供的指令相对应的有见识输出。在开源预训练的视觉语言模型OpenFlamingo的基础上,首先采用落地思维链(GCoT)过程增强Dolphins的推理能力。然后,构建特定于驾驶的指令数据和指令微调,将Dolphins定制到驾驶领域。利用BDD-X数据集,将四个不同的AV任务设计并整合到Dolphins中,促进其对复杂驾驶场景的全面理解。因此,Dolphins的特征分为两个维度:(1)对复杂和开放世界长尾驾驶场景提供全面理解并解决一系列AV任务的能力,以及(2)涌现的类人能力,包括上下文学习的无梯度即刻适应和反思的错误恢复。
背景问题
与人类驾驶员相比,现有的自动驾驶系统表现出许多局限性,包括:(1)整体理解和解释:现有的数据驱动自动驾驶系统(ADS)往往无法全面理解和解释动态和复杂的场景,尤其是开放世界驾驶环境长尾分布中的场景[9,10]。例如,考虑到一个球弹到路上,然后一个孩子追着它跑的场景,人类驾驶员可以利用常识、过去的经验和对人类行为的基本理解,立即推断出潜在的危险,并采取相应的行动来防止任何事故的发生。相比之下,现有的ADS可能很难在没有事先接触大量类似数据的情况下准确解释这种情况。这种缺乏整体理解的情况限制了系统在可能位于数据分布长尾处的意外场景中进行良好泛化的能力[11,12]。(2) 即时学习和适应:与只需几个例子就能立即学习和适应新场景的人类驾驶员不同,现有的ADS需要大量数据进行广泛的训练来处理新情况。例如,人类驾驶员在遇到一到两次新道路障碍物后,可以快速学会在其周围导航,而ADS可能需要暴露在许多类似的场景中才能学到相同的功课。(3) 反思和错误恢复:现有的ADS通常在操作过程中采用前馈处理,缺乏基于反馈和指导的实时校正能力。相比之下,人类驾驶员可以根据反馈实时纠正他们的驾驶行为。例如,如果人类驾驶员转弯错误,他们可以根据错误反馈快速调整决策,而ADS可能难以从错误反馈中快速恢复[13,14]。
相关工作
用大语言模型(LLM)作为驾驶智体处理与自动驾驶相关的任务,如感知、推理、规划和其他相关任务。例如,DriveLikeHuman[25]设计了一种新的范式来模拟基于LLM的人类学习驾驶过程,而GPT Driver[26]则利用GPT-3.5来帮助自动驾驶进行可靠的运动规划。同样,SurralDriver[27]使用CARLA模拟器构建了一个基于LLM的DriverAgent,该DriverAgent具有记忆模块,包括短期记忆、长期指南和安全标准,可以模拟人类驾驶行为,以了解驾驶场景、决策和执行安全行动。DriveLM[28]和NuPrompt[29]介绍了基于NuScenes数据集的驾驶任务[30]。具体而言,DriveLM利用思维图(GoT)的思想,将图式的QA对连接起来,以便用LLM强大的自动驾驶推理能力做出决策并确保可解释的规划。NuPrompt用LLM来制定一种基于提示的驾驶任务,该任务侧重于目标跟踪。然而,这些方法只接受语言输入,缺乏丰富的视觉特征。
Dolphins的新点
为了使VLM具备全面的理解能力和类人能力,需要在自动驾驶汽车(AV)背景中对其进行落地部署,支持各种任务。然而,AV中有限的特定任务标记数据对这种落地实现提出了挑战。为了解决这一问题,初步先利用用于自定义VQA数据集的思维链(CoT)原理[46],在VLM中促进综合推理。具体来说,丰富现有数据集,在粗级别上涵盖所有功能,设计了一个视频-文本交织数据集。在此数据集上调整VLM使其能够开发处理细粒度任务的能力。
GCoT指令调优
基于细粒度理解的推理能力在AD中至关重要。这是因为模型需要在视觉输入中感知目标的空间信息,推断它们与自车的关系和互动。大多数VLM缺乏对视觉模态(如图像和视频)的细粒度多模态理解,主要是由于它们在视觉语言预训练中的粗粒度对齐[58,59]。尽管HiLM-D[54]通过提供高分辨率图像和在自动驾驶(AD)中添加检测模块,提供了对VLM的细粒度理解能力,但它受到现有数据集质量的限制。为了进一步提高对VLM的细粒度理解,作者设计了基于落地CoT(GCoT)的指令调优,并开发了一个基于这种能力的数据集。
作者定义了一个通用流水线,用ChatGPT生成GCoT响应,丰富当前的VQA数据集。如图所示,这个过程分为三个步骤:(1)简要描述图像的内容。(2) 识别问题中的目标并描述其空间位置。(3) 如果问题需要推理,请在此步骤中提供推理过程。最后,将ChatGPT在这三个步骤中生成的句子组合起来,并在末尾附加“所以答案是{answer}”,形成完整的GCoT响应。这种方法在具有GCoT响应的不同视觉数据上训练模型,它学会以循序渐进的方式阐明各种场景和目标的推理过程,这些场景和目标可能不是驾驶特有的,但对培养基本推理技能至关重要。

自动驾驶设计的指令任务
对于自动驾驶相关的视频理解,包括四项对感知、预测和规划至关重要的任务,如图所示数据集:(1)行为理解。为了预测BDD-X数据集中的动作描述标签,用DriveGPT4[55]中相同的描述指令(记为Qa)来指导模型学习视频中的自车行为。(2) 行为推理。与行为理解任务类似,用DriveGPT4的正当性指令(记为Qj)使模型能够解释自车的行为。(3) 控制信号预测。在BDD-X数据集中,不同视频片段的持续时间各不相同。因此,在该任务中,所提供的历史控制信号的数量取决于视频片段的持续时间。VLM需要基于这些控制信号(例如,速度、油门和转向角)来预测下一秒自车的速度和转向角。(4) 详细对话。以上三项任务倾向于传统的视觉语言任务(简短回答)。因此,旨在引入更详细的对话,提高为人类倾向的反应(长答案)所需要的指令泛化能力。具体而言,依靠ChatGPT[61]的上下文学习能力来丰富动作描述和推理标签,生成交通规则、行为的潜在风险、驾驶预防措施等方面人类倾向的反应。
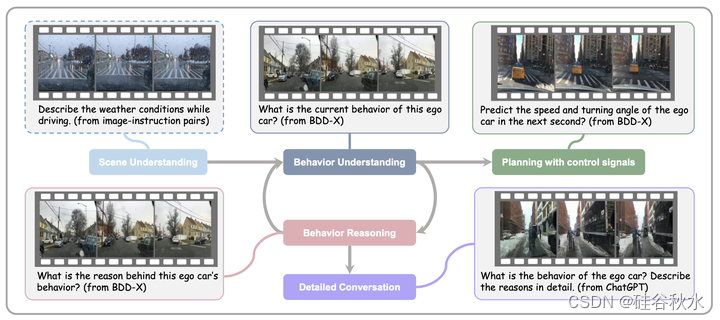
为了构建适合端到端自动驾驶系统的数据集,收集来自BDD-X数据集的视频片段和标签[24]。BDD-X数据集包括大约7000个视频,每个视频被细分为多个片段,每个片段都传达了自车的不同行为以及相应的文本注释。总共有大约25000个例子,注释包括动作描述(例如“汽车停止”)和动作推理(例如“因为红绿灯”)。继之前的 DriveGPT4[55]之后,用BDD-X数据集开发了用于自动驾驶的视觉指令跟从数据集,该数据集由四个不同的自动驾驶相关任务及其相应指令组成。然而,由于任务和指令多样性的限制,在该数据集上训练的VLM在对未见过的任务零样本泛化能力方面表现出显著的缺陷。因此,用多模态上下文指令调优[38]来帮助模型在自动驾驶相关任务中通过少数注释示例快速适应新指令。
与设计的任务相结合,所提出的数据集包括32k个视频-指令-答案三元组,其中11k个属于ChatGPT生成的详细会话任务。剩下的三个任务共同包含来自BDD-X数据集标签的21k个三元组。注意:构建数据集的提议任务是一个粗粒度集,可以通过CoT过程更好地解决。因此,基于CoT落地的模型被迫在这些任务之外涌现不同的能力,以便在指令调优过程中在构建的数据集上获得良好的结果。
自动驾驶的多模态上下文指令调整
在NLP中,具有上下文示例的训练模型被广泛认为有利于促进模型从几个输入-输出示例中学习新任务的能力,这些示例被称为少样本提示[57,62,63,64,65]。在视觉指令调整方面,Otter[38]引入了上下文指令调整,以保持VLM的少样本上下文学习能力。受这些工作的启发,将上下文指令调整引入自动驾驶领域。该领域目前面临着多种指令跟从数据集的严重短缺。作者的目标是增强VLM的上下文学习能力,促进自动驾驶相关任务中模型的泛化。
为了实现上述目标,用OpenFlamingo[18]作为基础VLM。OpenFlamingo是Flamingo[35]的重新实现,在图像-文本交织数据集Lion-2B[66]和MMC4[67]数据集的集成上进行训练,增强其上下文学习能力。自动驾驶相关指令数据集采用了包括视频-指令-答案三元组的格式。因此,采用检索方法为每个三元组选择上下文中的示例。
本质上,视频中类似于自车行为的例子更有可能被选中。之前工作观察到,与图像特征相比,基于文本相似性的上下文示例检索在保持VLM的上下文学习能力方面更有效。假设这个结论同样适用于视频-文本对。因此,只用文本嵌入相似性检索的上下文示例,并在训练阶段将上下文示例限制为每个三元组最大k=3。
训练的模型架构
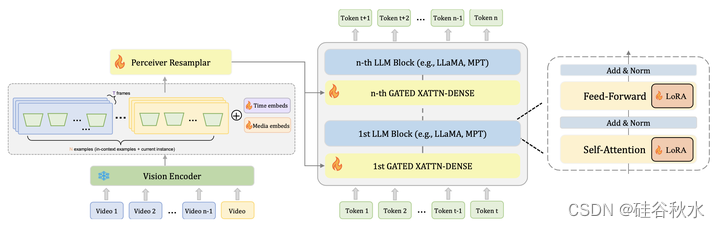
模型基于OpenFlamingo架构,名为Dolphins。该模型由来自CLIP[70]的视觉编码器、用于接收来自视觉编码器的视觉特征重采样器、和来自大语言模型(例如,LLaMA[16]、MPT[34])的文本编码器组成,该大语言模型配备有用于图像-文本交互的门控交叉注意层。然而,与Flamingo不同,OpenFlamingo缺乏支持视频输入的能力。因此,为了减轻空间特征聚合导致的全局时间特征消失,引入了一组学习的潜向量作为时间位置嵌入。类似地,另一组学习的潜向量合并用作media位置嵌入,在少样本提示中引入必要的排序信息。这些嵌入的加入显著增强了模型在视频理解方面的能力。为了保留预训练知识并减少计算消耗,冻结编码器,只微调添加到文本编码器的重采样模块、门控交叉注意层和LoRA[71]模块,如图所示。















 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









