







BDD100k数据集标注转YOLO格式:
# -*- coding: utf-8 -*-
# @Author: lay
# @Time: 2022/3/30 上午12:03
"""
把bdd100k数据集制作YOLO数据集的格式,以此进行训练
YOLO数据集的格式: class、x_center/img_width、y_center/img_height、w/img_width、h/img_height
class :目标类别
x_center/img_width :归一化中心列坐标
y_center/img_height :归一化中心行坐标
w/img_width :归一化宽
h/img_height :归一化高
"""
import os
import cv2 as cv
import shutil
import json
# ----------文件路径根据自己的情况修改----------
# 数据文件目录
data_root = r"/home/lay/PycharmProjects/data/bdd100k_det_yolo/"
# 图片位置
# img_root = data_root + "images/train"
img_root = data_root + "images/val"
# 转换后标签要存放的位置
# label_root = data_root + 'labels/train'
label_root = data_root + 'labels/val'
# 原始标签文件位置
label_ori = r"/home/lay/PycharmProjects/data/bdd100k_det_yolo/labels/det_20"
# 标签json文件
# jsonpath = os.path.join(label_ori, 'det_train.json')
jsonpath = os.path.join(label_ori, 'det_val.json')
# ----------上面是所有相关文件的路径----------
if not os.path.isdir(label_root):
os.makedirs(label_root)
else:
# 如果之前已经生成过: 递归删除目录和文件, 重新生成目录
shutil.rmtree(label_root)
os.makedirs(label_root)
jsonfile = open(jsonpath, "rb")
fileJson = json.load(jsonfile)
# 由于有些图片没有对应的标注txt文件,下面做了一些处理
imgs = os.listdir(img_root)
img_count = len(imgs)
json_label_count = len(fileJson)
print("img_count: ", img_count)
print("json_label_count: ", json_label_count)
fileJson_imgs = []
for i in range(len(fileJson)):
imgdict = fileJson[i]
fileJson_imgs.append(imgdict['name'])
if 'labels' not in imgdict.keys():
print('json {} not labels!'.format(i))
print('imgdict: ', imgdict)
imgs_diff_jsonfile = list(set(imgs).difference(set(fileJson_imgs)))
jsonfile_diff_imgs = list(set(fileJson_imgs).difference(set(imgs)))
print('in imgs but not in jsonfile: ', imgs_diff_jsonfile)
print('in jsonfile but not in imgs: ', jsonfile_diff_imgs)
for del_img in imgs_diff_jsonfile:
del_img_path = os.path.join(img_root, del_img)
if os.path.exists(del_img_path):
os.remove(del_img_path)
used_names = ['car', 'bus', 'truck']
category2id = {
"car": 0,
"bus": 1,
"truck": 2
}
# fileJson是list类型, list里面是dict
count = 0
empty_count = 0
for imgdict in fileJson:
txtfile = imgdict['name'].replace('.jpg', '.txt')
txtpath = os.path.join(label_root, txtfile)
# 计算图片尺寸
imgpath = os.path.join(img_root, imgdict['name'])
img = cv.imread(imgpath)
img_height, img_width, _ = img.shape
# some images don't have labels, because nothing in images!
if 'labels' not in imgdict.keys():
t = open(txtpath, 'a')
t.close()
empty_count += 1
print('created empty txt file: ', txtfile)
continue
for label in imgdict['labels']:
category = label['category']
x1 = label['box2d']['x1']
x2 = label['box2d']['x2']
y1 = label['box2d']['y1']
y2 = label['box2d']['y2']
x_center = (x1 + x2) / 2
y_center = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
if category in used_names:
label_str = '{:d} {:.6f} {:.6f} {:.6f} {:.6f}\n'.format(
category2id[category],
x_center / img_width, # center_x
y_center / img_height, # center_y
w / img_width, # bbox_w
h / img_height) # bbox_h
# 以追加的方式添加每一帧的label
with open(txtpath, 'a') as f:
f.write(label_str)
count += 1
if count % 200 == 0:
print('image {} dealt done!'.format(count))
print('image {} dealt done!'.format(count))
labels = os.listdir(label_root)
imgs = os.listdir(img_root)
print('labels txt file count: ', len(labels))
print('images count: ', len(imgs))
for img in imgs:
txtf = img.replace('.jpg', '.txt')
if txtf not in labels:
txtpath = os.path.join(label_root, txtf)
t = open(txtpath, 'a')
t.close()
print('created empty txt file: ', txtf)
empty_count += 1
print('########################################')
print('labels txt file count: ', len(os.listdir(label_root)))
print('empty txt file count: ', empty_count)
print('images count: ', len(os.listdir(img_root)))
print('\nAll image dealt! Done!')
修改训练需要的相关配置文件,然后训练:
python ../train.py --weights yolov5l.pt \
--cfg ../models/yolov5l_bdd100k.yaml \
--data ../data/bdd100k.yaml \
--hyp ../data/hyps/hyp.scratch-med.yaml \
--epochs 300 \
--batch-size 16 \
--device 0 \
--name "yolov5l_bdd100k_20220330"
官方推荐训练300轮,由于bdd100k数据集足够大,训练了33轮看到各项loss趋于平稳,就停下了。



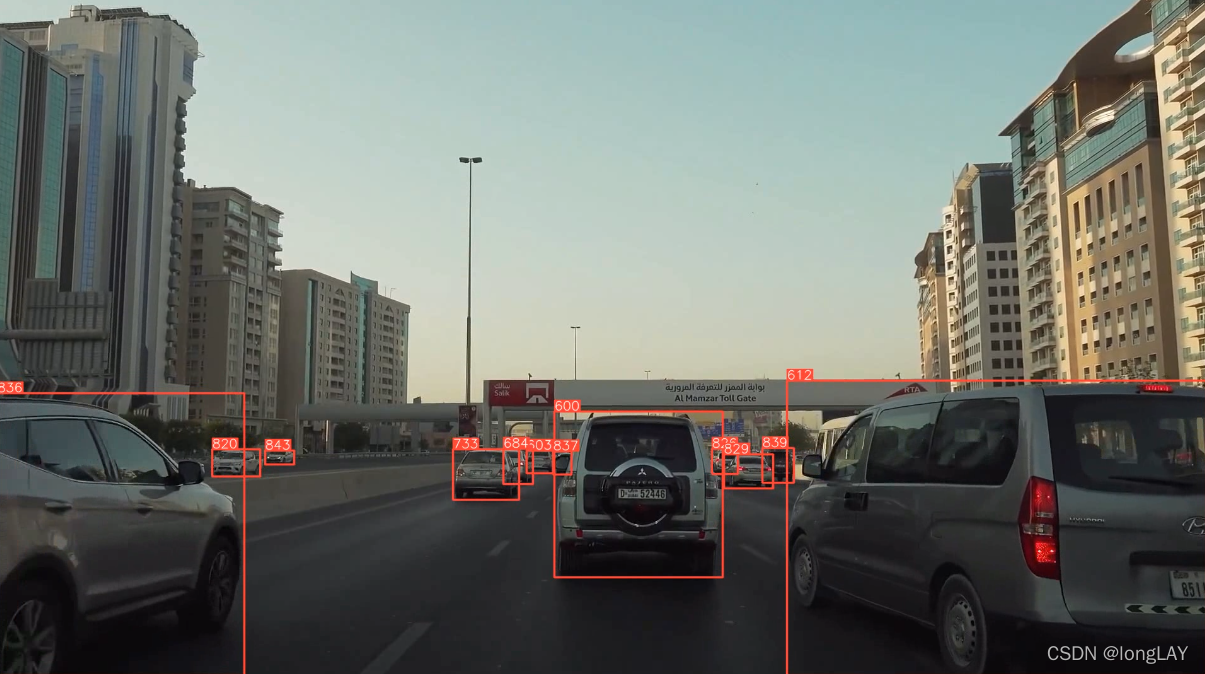
效果(视频截的几张图):















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









