










24年6月来自上交大论文“Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters”。
利用激活稀疏性是一种很有前途的方法,可以显著加速大语言模型 (LLM) 的推理过程,而不会影响性能。然而,激活稀疏性由激活函数决定,而常用的激活函数如 SwiGLU 和 GeGLU 表现出有限的稀疏性。简单地用 ReLU 替换这些函数无法实现足够的稀疏性。此外,训练数据不足会进一步增加性能下降的风险。为了应对这些挑战,一种新的激活函数 dReLU,旨在提高 LLM 激活稀疏性,以及高质量的训练数据混合比,以促进有效的稀疏化。此外,采用混合专家 (MoE) 模型中前馈网络 (FFN) 专家的稀疏激活模式来进一步提高效率。通过将神经元稀疏化方法应用于 Mistral 和 Mixtral 模型,每次推理迭代仅分别激活 25 亿和 43 亿个参数,同时实现更强大的模型性能。评估结果表明,这种稀疏性实现 2-5 倍的解码速度提升。值得注意的是,手机上TurboSparse-Mixtral-47B 实现了每秒 11 个 tokens 的推理速度。
最近 LLM 通常更喜欢 GELU [23] 和 Swish [50] 等激活函数。然而,这些函数并不能显著提高激活稀疏度,而且很难通过条件计算加速。为了解决这个问题,ReLUfication [42] 是一种现有的最先进方法,它用 ReLU 替换了原来的激活函数,并继续进行预训练。尽管这种方法很有潜力,但往往难以达到所需的激活稀疏度水平,并可能导致性能下降 [30, 59]。
现有 ReLUfication 方法的失败可以归因于两个主要原因。首先,简单地用 ReGLU 替换 SwiGLU 效率低下,因为它只能将稀疏度从 40% 提高到 70% 左右。这表明,需要对模型架构进行更深入的研究,以实现更高的稀疏度。其次,当前方法中预训练数据的多样性有限,训练tokens数量不足,导致能力恢复不完整 [42, 30]。因此,扩大预训练数据集的多样性和增加训练tokens的数量是提高模型性能的关键步骤。
为了应对这些挑战,对现有的 ReLUfication 方法分析发现,其缺点源于 GLU 组件中的负激活。因此,提出一个名为 dReLU 的有效激活函数。将 dReLU 与 SwiGLU 一起应用于小规模 LLM 的预训练中,dReLU 的 LLM 性能与 SwiGLU 的 LLM 相当,同时还实现接近 90% 的稀疏度。
同时,对基于 MoE 的 LLM 进行稀疏度分析。专家中的前馈网络 (FFN) 保持稀疏激活,类似于密集 LLM 所表现出的行为。这一现象表明,将 MoE 技术与基于 ReLU 的稀疏激活相结合,有机会进一步加快推理速度。
分析一下常用的门控-MLP 块,由三个全连接层组成,并执行以下计算:
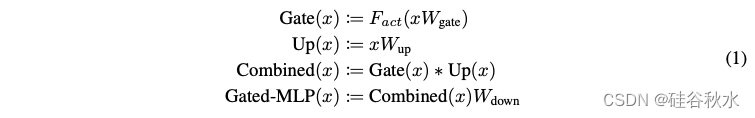
其中Fact代表不同的激活函数。
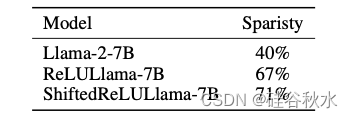
评估 ReLULlama-7B [59] 和原始 Llama-2-7B [60] 的稀疏性,如表所示。结果表明,现有的 ReLUfication 方法只能将稀疏性从 40% 提高到 67%,表明其在显著增强模型稀疏性方面效果有限。
现有的 ReLUfication 方法,主要侧重于修改门控组件。与以前的工作不同,ReLUfication 不会改变上投影组件的激活分布。根据 Gated-MLP 的定义(公式 1),门控和上投影组件共同影响神经元激活的稀疏性。然而,上投影组件中相当一部分激活值仍然小于 0。这表明,将小于 0 的上投影矩阵和门控矩阵输出屏蔽为非激活状态可以引入更强的稀疏性,而不会牺牲非线性能力。
这样就有了新的激活函数:dReLU(公式 2),其中 ReLU 在上投影和门控之后应用
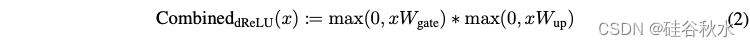
比较用 dReLU 和 SwiGLU 的 两个300M 参数解码器架构模型,均在 fineweb 数据集 [47] 下针对 5B 个tokens进行预训练。评估结果如表所示。
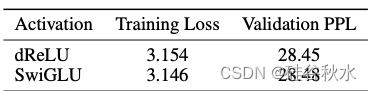
用 dReLU 结构的模型与用 SwiGLU 结构的模型相比,表现出相似的收敛性。值得注意的是,在 Wikitext-2 [39] 上评估这两个模型的困惑度。基于 DReLU 的模型在 WikiText-2 [39] 上的表现略好一些。
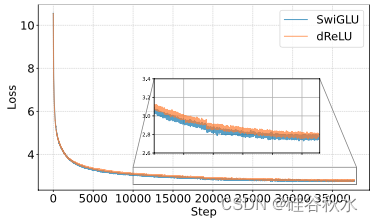
如图说明训练期间的损失曲线,表明具有 dReLU 激活函数的模型与 SwiGLU 模型相比实现相似的收敛能力。值得注意的是,虽然基于 SwiGLU 的模型具有较低的训练损失,但基于 dReLU 的模型具有较低的验证困惑度。这些结果提供了强有力的证据,表明采用 dReLU 结构不会损害模型性能。
另一个问题是基于 dReLU 模型的稀疏性。为了研究基于 dReLU 的模型的稀疏性,提出一种测量和评估模型在不同稀疏性水平下性能的方法,包括根据绝对值选择由 dReLU 或其他激活函数激活的前 k% 个值,如公式 3 和公式 4 所示:

其中 Wdown 表示下投影矩阵。通过改变 k 的值,可以控制模型的稀疏度。为了评估稀疏度对模型性能的影响,在不同的稀疏度水平上对一系列下游任务评估基于 dReLU 的模型。这能够确定 dReLU 激活函数的最佳稀疏度-性能权衡。
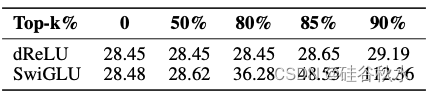
下表展示了基于 dReLU 和基于 SwiGLU 的模型在不同稀疏度水平上在 WikiText-2 上的困惑度。结果表明,dReLU 激活函数可以在不显著降低性能的情况下实现高稀疏度,即使在 90% 的稀疏度下也能保持具有竞争力的性能。相比之下,当稀疏度达到 80% 时,基于 SwiGLU 的模型的困惑度会急剧增加。
基于 dReLU 的 ReLUfication 是否可以在实现更高稀疏度的同时恢复原始模型的性能?
考虑两个代表性模型:Mistral-7B 和 Mixtral-47B。将原来基于 SwiGLU 的 FFN 替换为基于 dReLU 的 FFN,然后继续进行预训练。
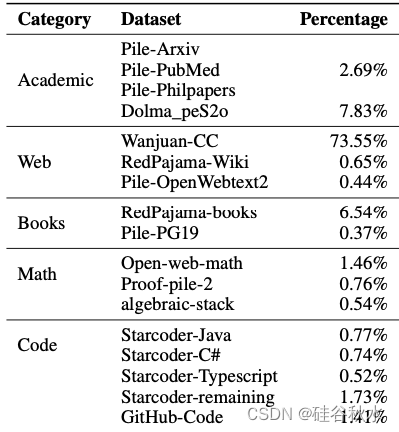
缘于ReLUfication过程,模型能力的恢复与恢复训练所用的语料密切相关。从开源社区收集尽可能多的语料用于训练,例如Wanjuan-CC[48]、open-web-math[46]、peS2o[54]、Pile[19]、The Stack[28]、GitHub Code[1]等。详细混合比例如下表所示:
预训练后,用高质量的 SFT 数据集进一步提高模型性能,包括 orca-math-word-problems [43]和bagel [27]。
ReLUfication 的超参基于先前研究的经验结果 [69]。用 llm-foundry 框架进行训练 [44] 并采用 FSDP 并行性。模型使用 AdamW 优化器 [38] 进行训练,超参数如下:β1 = 0.9 和 β2 = 0.95。用余弦学习率进度,并使用权重衰减和梯度剪裁的默认值,如表所示。总的来说,在 150B 个 tokens 上对模型进行了预训练。

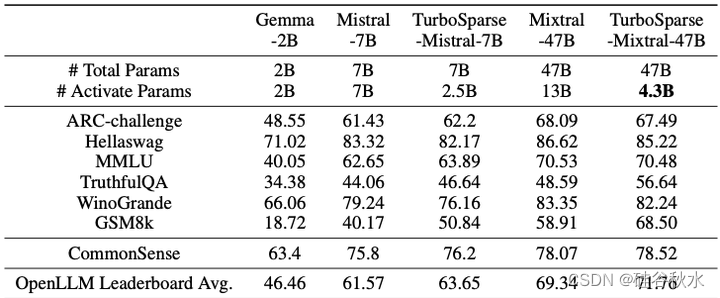
在 OpenLLM Leaderboard 中包含的任务上测量稀疏模型的性能,这些任务包括 25 样本 Arc-Challenge [13]、10 样本 Hellaswag [65]、5 样本 MMLU [22]、0 样本 Truth-fulQA [35]、5 样本 Winogrande [51] 和 8 样本 GSM8K [14]。
此外,还跟踪 Llama 2 的评估任务,其中包括常识推理任务。计算PIQA [8]、SCIQ [26]、ARC easy [13]、OpenBookQA [41] 的平均值。将模型与几个外部开源 LLM 进行比较,包括 Gemma-2B [58]、Mistral-7B [24] 和 Mixtral-47B [25]。
下游任务的性能如下表所示:
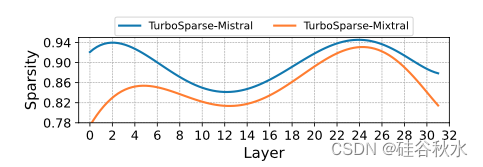
用通用数据集 (fineweb) 分析每层的零值激活比,如图所示。通过考虑输出值为零的激活,发现对于 TurboSparse-Mistral-7B,平均每层有 90% 的神经元处于非激活状态。对于 TurboSparse-Mixtral-47B,这个百分比略低,每个专家 FFN 的平均百分比为 85%。最初,Mixtral-47B 会在每层激活 8 位专家中的 2 位,从而引入 75% 的稀疏性,这意味着只需要计算 25% 的 FLOPS。此外,在 ReLUfication 之后,每个专家只会激活 15% 的神经元。结合这些,在推理中,每个 MoE 层中只有 3% 的参数会被激活。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









