










24年3月来自新加坡国立大学、英国爱丁堡大学和瑞士ETH的论文“OpenMoE: An Early Effort on Open Mixture-of-Experts Language Models”。
为了帮助开源社区更好地理解基于混合专家 (MoE) 的大语言模型 (LLM),Open-MoE构建一系列完全开源且可重现的仅解码器 MoE LLM,参数范围从 650M 到 34B,训练的tokens多达 1T 以上。基于 MoE 的 LLM 可以提供比密集 LLM 更有利的成本效益权衡,凸显了未来 LLM 开发的潜在有效性。
另外,深入分析OpenMoE 模型中的路由机制,三点发现:上下文无关的专业化、早期路由学习和面向结束的丢弃。MoE 模型中上下文相关性最小的路由决策主要基于 token ID。Token到专家的分配在预训练阶段的早期就已确定,并且基本保持不变。这种不完善的路由可能会导致性能下降,尤其是在多轮对话等连续任务中,其中序列中较晚出现的tokens更有可能被丢弃。

开源下载 https://github.com/XueFuzhao/OpenMoE
OpenMoE 包括:(1)OpenMoE-Base/16E:一个用于调试目的的 0.65B 参数小模型。16E 表示每个 MoE 层有 16 位专家;(2)OpenMoE-8B/32E:此变型总共有 8B 参数,Transformer 块中每个 token 激活约 2B 参数,并在超过 1 万亿个 token 上进行预训练;(3)OpenMoE-8B/32E-Chat,OpenMoE-8B/32E 的聊天版本,用 WildChat [2] 数据集的 100K 子集进行微调;(4)OpenMoE-34B/32E:一个更大规模的模型,Transformer 块中每个 token 激活 6B 参数,并使用 200B token 进行训练,证明了方法的可扩展性。
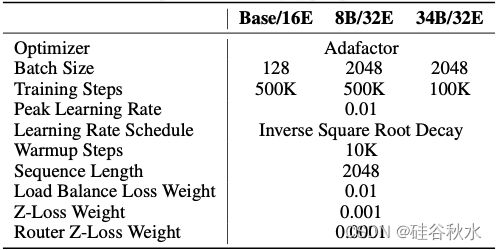
下表是模型的配置细节:

OpenMoE-8B/32E 模型实现了与 OpenLLaMA-3B [19] 和 TinyLLaMA-1.1B [56] 相当的性能,两个密集的开放式 LLM 使用了更高的训练成本。值得注意的是,在 MT-Bench [58] 上,OpenMoE-8B/32E-Chat 在单轮对话中的表现明显优于两个密集的 LLM。此外,OpenMoE-8B/32E 提供 5 个中间检查点,每个检查点都比前一个多使用 200B 个 token 进行训练,以支持和鼓励未来的研究。
一些 LLM 训练策略的探索:(1)与内部或文本为主开源数据训练模型的常见做法不同,用大量代码训练 OpenMoE,在预训练的早期阶段占比高达 52.25%;(2)超越传统的下一个token预测训练目标,采用 UL2 训练目标 [47],其动机是其有效性【1】以及与编码数据的良好一致性 [5]。
尽管 MoE 很有效,但关于 MoE 为何表现良好的研究仍然不足。从高层次来看,MoE 引入了比密集模型更多的可训练参数。为了扩展参数量时保持 FLOPS 不变,MoE 应用了一个路由层,该路由层以稀疏和自适应的方式将每个 token 分配给少数专家。这种稀疏专家选择过程对于 MoE 的功能至关重要。
不幸的是,尽管现有文献简要地可视化路由决策 [28、33、38、42、61],但仍然不清楚路由器的工作原理以及路由决策如何影响 MoE 模型中的结果,尤其是对于用来自不同领域的混合数据集进行训练的后-ChatGPT LLM。在这项工作中,基于各种分类法研究了这个问题,包括领域、语言、任务和 token。
主要结论如下:(1)与上下文无关的专业化:MoE 倾向于简单地根据相似的 token 级语义对 token 进行聚类,这意味着无论上下文如何,某个 token 更有可能被路由到某个专家;(2)早期路由学习:token ID 路由专业化在预训练的早期就已建立,并且基本保持不变,因此 token 在整个训练过程中始终由相同的专家处理;(3)到结束的丢弃:由于每个专家都有固定的最大容量,如果专家已经达到容量上限,则序列中较晚出现的 token 面临更高的被丢弃风险。这个问题在指令调整数据集中更为严重。与预训练数据相比,这些数据集通常表现出领域差距,这意味着在早期预训练期间建立和巩固的平衡 token 分配策略在指令调整场景中可能不那么有效。这令人担忧,因为指令数据在将 LLM 部署到实际应用中起着重要作用。
预训练数据集
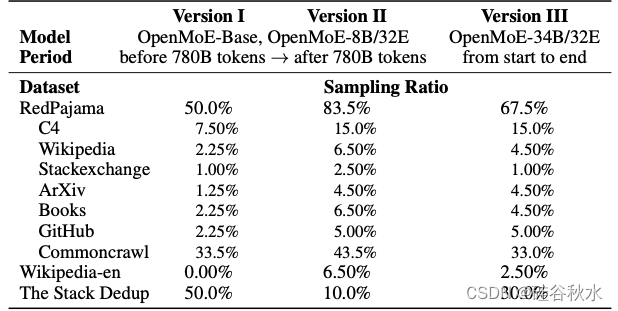
现代 LLM 通常由来自各个领域的数据集组合训练而成,即数据混合 [7, 9, 21, 36, 49]。除了针对代码定制的 LLM(例如 StarCoder [30]、CodeLLaMA [40])外,大多数现有模型的预训练数据以文本数据为主。例如,GitHub 数据集的采样率仅为 LLaMA 的 4.5% [49]。然而,代码数据非常重要,原因有二。首先,代码数据可能会提高具有思维链的复杂推理能力 [16]。更重要的是,与有时模糊且容易误解的自然语言不同,代码总是精确的。这使得代码成为一种更有效的语言,让机器能够简洁地传达信息,而不会在不同的(具身)AI 智体之间产生误解,因此,代码在实际应用中具有主导 LLM 通信的巨大潜力。采取一种以代码为主的预训练数据混合方案。如表所示是数据混合的三种版本,最开始从 RedPajama [11] 中提取了 50% 的数据,从 The Stack [25] 的复制版本中提取 50% 的数据。实验结果表明,版本 I 数据混合方案在代码比例上可能有点激进。在预训练的后期修复了这些问题。
模型架构
Token 化器。采用词汇量为 256K 的 umT5 [10] token 化器,原因有二:(1)具有大型多语言词汇量的 umT5 token 化器比使用小型词汇量的 token 化器(例如词汇量为 32K 的 LLaMA token 化器)更好地支持低资源语言;(2)与一些旧的 token 化器(如 BERT [24] 和 T5 [37] token 化器)相比,umT5 token 化器具有字节回退功能,可以更好地支持词汇量以外的分词。
token 选择路由。模型架构和路由设计通常遵循 ST-MoE [61],确保训练稳定性,这在训练大模型时极为重要。给定 E 个可训练专家和输入表征 x,MoE 模型的输出可以表示为:
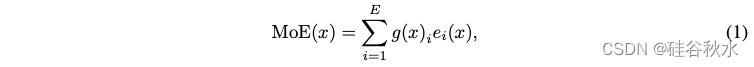
其中ei() 是第 i 个专家的非线性变换函数,g()i 是非线性映射 g() 的路由器第 i 个元素。
Top-2 选择。根据上面的公式,当 g(·) 是稀疏向量时,在训练过程中,只有部分专家会被激活并通过反向传播进行更新。将门控层设置为 top-K 选择:
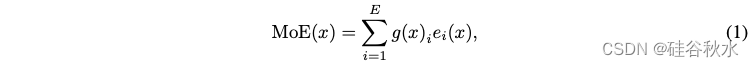
其中 f() 是路由的线性变换,设定 K = 2。
残差MoE。Transformer块描述为

在 OpenMoE 中,对于每个基于 MoE 的 Transformer 块,用一个残差 MoE 层来确保每个 token 始终激活一个固定的 FFN 层。即:
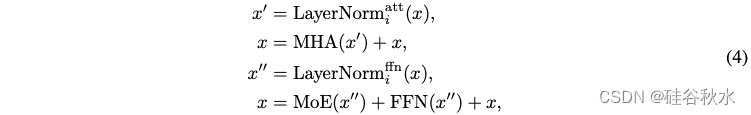
以交错方式使用基于 MoE 的 Transformer 块,而不是在每个 Transformer 块中都放置 MoE。在设置中, OpenMoE-Base/16E 和 OpenMoE 34B/32E 中每 4 层使用一次 MoE,在 OpenMoE-8B/32E 中每 6 层使用一次 MoE。此设置的灵感来自 ViT-MoE [38] 中的发现,即每层使用 MoE 会在路由过程中引入更多的计算开销,然后导致比交错使用 MoE 更糟糕的成本效益权衡。
负载平衡损失和路由器 Z-损失。ST-MoE [61] 遵循 Shazeer 的思路 [42],使用 MoE 负载平衡损失来确保分配给不同专家的 token 数量均衡,从而使 MoE 模型能够实现更好的并行性。对于每个路由操作,给定 E 个专家和 N 个批次(其中有 B = N L tokens),在训练期间将以下辅助损失添加到总模型损失中:
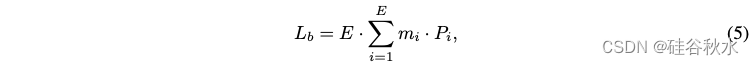
其中 Pi = softMax(f(x)) ,tokens 分给专家 i 的token部分是:
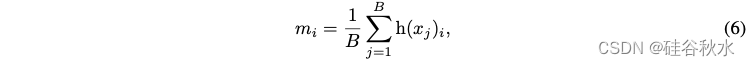
其中 h(·) 是Top-K 选取的索引向量。h(xj )i 是 h(xj ) 的第 i 个元素。值得注意的是,与g(x)i 不同,mi 和 h(xj)i 是不可导的。然而,端到端优化 MoE 需要一个可导的损失函数,因此用路由得分 softmax(f(x))(即 Pi)使路由决策可导,进而可学习。
除了负载平衡损失之外,Zoph [61] 还提出路由器 z-loss,以实现更稳定的 MoE 训练:
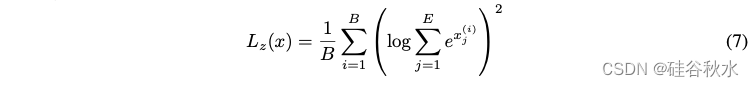
此路由器 z-loss 可以惩罚门控网络的大 logit 输入,并鼓励数字的绝对幅度较小,从而可以减少 MoE 层中的舍入误差。
综合起来,最终训练损失可以写成:
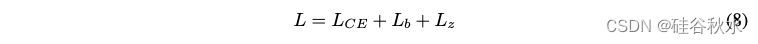
其中LCE是大模型预训练的交叉熵。
训练目标
没有直接采用原始的因果语言建模 (CasualLM),而是探索 UL2 [46],这是一个更加多样化的语言模型预训练目标,它结合展开损坏 (SpanCorrupt) 和前缀语言建模 (PrefixLM) [37]。值得注意的是,UL2 中的 SpanCorrupt 比原始 SpanCorrupt 更加多样化,因为它混合了各种展开长度和损坏率。
有两个理由在 OpenMoE 中探索 UL2。首先,UL2 在 PaLM-2 [1] 中显示出有希望的结果。更重要的是,激进的token掩码与现实世界中的代码补全任务非常相似,例如 Copilot。Bavarian [5] 还发现,类似的中间填充 (FiM) 目标可以比原始训练目标更好地对代码进行建模。由于预训练数据混合中使用更多代码,因此直观地采用涵盖 FiM 的 UL2 是更合理的选择。
详细 UL2 训练目标配置如表所示。仅使用 20% 的低掩码率 (r=0.15),因为训练期间的输出tokens较少,这可能会减慢学习速度。还使用了比默认 UL2 设置更多的 PrefixLM,因为PrefixLM 训练增强的零样本和上下文学习能力非常重要。

有监督微调
尽管对齐不是此 OpenMoE 项目的重点,但仍使用开源 WildChat 数据集 [2] 的子集进行有监督微调 (SFT),以增强指令遵循能力,并研究 SFT 之前和之后 MoE 模型的行为。由于 OpenMoE 开发后期缺乏计算资源,仅在 WildChat 中从 GPT-4 中挑选指令-响应对。子集包括 58K 对话,每个对话平均包含 1.8 个回合。
其他设计
根据最近的 LLM,用 RoPE [45] 进行位置嵌入,采用 SwiGLU [41] 作为密集和 MoE Transformer 块中 FFN 激活函数。OpenMoE 模型的更详细模型配置和训练超参如下表所示。
应用数据并行性、张量并行性 [43, 52] 和专家并行性 [27] 进行大规模训练模型。在 Google Cloud TPU 上训练 OpenMoE 模型,根据可用性配备 64 到 512 个 v3 芯片。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









