









23年10月16日来自香港科技大学、同济大学和华盛顿大学的论文“BEVGPT: Generative Pre-trained Large Model for Autonomous Driving Prediction, Decision-Making, and Planning“。
预测、决策和运动规划对于自动驾驶至关重要。 在大多数工作中,它们被视为单独的模块或组合成具有共享主干但独立任务头的多任务学习范例。 然而,作者认为它们应该被整合到一个综合框架中。 尽管最近的几种方法遵循这种方案,但它们都受到复杂的输入表示和冗余框架设计的困扰。 更重要的是,无法对未来的驾驶场景做出长期预测。
为了解决这些问题,作者重新思考自动驾驶任务中各个模块的必要性,并仅将所需的模块纳入到极简的自动驾驶框架中。 BEVGPT,一种集成了驾驶场景预测、决策和运动规划的生成式预训练大模型。 该模型以鸟瞰(BEV)图像作为唯一输入源,并根据周围的交通场景做出驾驶决策。 为了确保驾驶轨迹的可行性和平滑性,作者开发了一种基于优化的运动规划方法。 在 Lyft Level 5 数据集上实例化 BEVGPT,并用 Woven Planet L5Kit 进行真实驾驶模拟。 所提出框架的有效性和鲁棒性得到了验证,在 100% 决策指标和 66% 运动规划指标上优于以前的方法。 此外,该框架长期准确生成 BEV 图像的能力通过驾驶场景预测任务得到了证明。
如图所示是BEVGPT 框架的两阶段训练过程。 在预训练阶段,用大量的自动驾驶数据来训练因果Transformer。 目标是学习驾驶场景预测和决策。 该模型容量大,可在4秒内决定未来轨迹,并在长达6秒内预测未来驾驶场景。 在线微调阶段,将经过训练的因果Transformer调优为运动动力学的运动规划和准确的 BEV 生成。
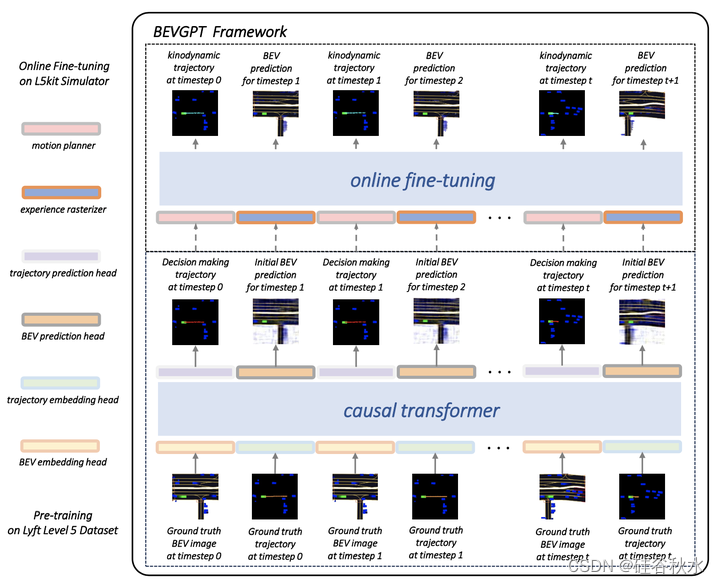
在该框架中,决策输出是自车在 T = 4s 范围内的未来位置,运动规划器进一步处理生成运动动力学且平滑的轨迹。 考虑到静态环境信息可以很容易地从高清地图中获得,更加关注对车辆和行人等动态目标的精确预测。 驾驶场景预测通过环境地图和动态预测相结合得到,如图所示。

为了合理地表示自动驾驶汽车的运动并规划可行的轨迹,采用运动学自行车模型,如图所示。

采用分段多项式轨迹来表示导数平坦输出,即 px 和 py 。 为了最小化后续运动规划模块中的抖动,选择五次多项式表示。 假设轨迹总共由 M 段组成,每段具有相同的时间间隔 Δt。
规划轨迹f(t)的基本要求包括动态可行性和轨迹平滑性。 同时,最好是最小化控制的工作。 在例子中,选择加速度来代表控制效果。 指定初始状态 p0 和最终状态 pM。 决策输出 pn 应该被包含在轨迹中。
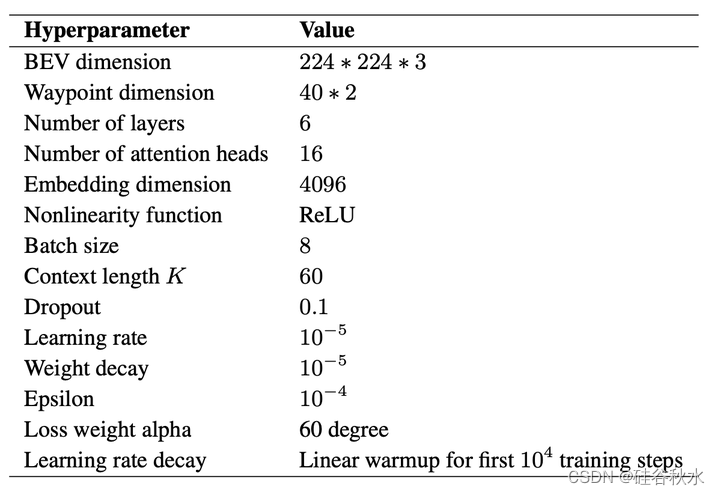
本研究中,采用 GPT 架构(Radford 2018),添加一个因果自注意掩码修改 Transformer 架构,以便自回归地生成预测token。 超参数如下表所示。
由于任务所需自动驾驶数据的多样性,使用(Houston 2021)提出的自动驾驶数据集。 包含20 辆自动驾驶汽车组成的车队在四个月内收集的 1,000 多个小时的驾驶数据。 从数据集中提取车辆姿态、语义 BEV 图像和静态环境地图图像。 具体来说,首先在数据集迭代并消除短于 24 秒的场景,即时间间隔 Δt = 0.1 秒的 240 帧。 然后提取自车的未来目标位置作为决策训练的标签。 最后,记录每帧的目标位置、当前 BEV 图像、下一个 BEV 图像和下一个环境地图图像作为训练数据集。
预训练阶段,在提取的数据集上训练 BEVGPT 20 个 epoch。 为了提高模型的决策和预测能力,用均方误差(MSE)设计损失函数。用 Woven Planet L5Kit 的自动驾驶模拟,对预训练模型进行微调。 BEV 输入被嵌入并馈送到模型中,确定 MΔt 时间间隔的未来轨迹点。 采用运动规划器根据决策输出生成动态可行的轨迹。 然后把可执行轨迹“喂“模型,生成未来的 BEV 预测。
此外,还开发了经验光栅化器帮助模型获取模拟驾驶场景的静态信息。 直觉是,一旦知道静态全局地图、自动驾驶车辆的初始世界坐标以及世界坐标和光栅坐标之间的转换,就可以轻松地将所有车道和交叉口映射到光栅化 BEV 图像中。 经过Δt时间间隔的模拟后,可以获得下一张BEV图像的真值。
为了评估未来长期驾驶场景预测的能力,设计的实验要求模型在 T = 6 秒内生成未来的 BEV 图像。 在这种情况下,BEVGPT 需要用第一帧的 BEV 真值自动回归预测 60 个时间步长的未来驾驶场景。 选择四种具有挑战性的交通场景。 第一个是有红绿灯的路口,车辆应了解红灯的含义并在路口前停车。 第二个是绿灯亮起的高动态交叉路口,车辆需要正确通过交叉路口。 第三种是多智体环境中的笔直道路,自动驾驶车辆应尽可能快地向前行驶。 最后一个是道路交叉口,交通信号由红变绿,车辆需要理解这一信息并及时启动。如图为预测结果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









