









23年6月来自除美国耶鲁大学以外国内多家大学和公司如清华、人大、腾讯、知乎等的论文“ToolLLM: Facilitating Large Language Models To Master 16000+ Real-world APIs“。
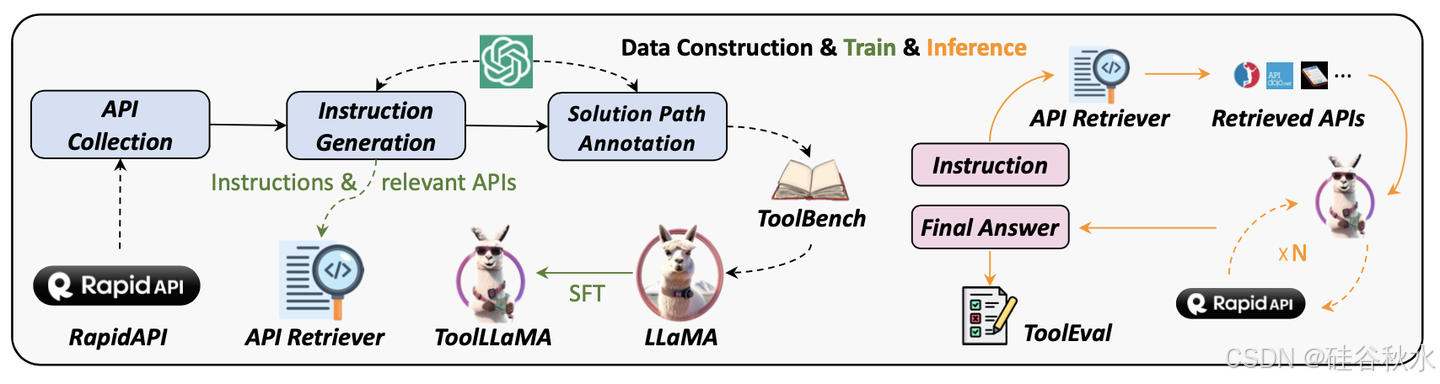
尽管开源语言大模型(LLM)及其变型(例如LLaMA和Vicuna)取得了进步,但在执行更高级别的任务方面仍然受到很大限制,例如遵循人类指令使用外部工具(API)。这是因为当前的指令调优主要集中在基本的语言任务上,而不是工具使用领域。这与最先进的(SOTA)LLM形成鲜明对比,例如ChatGPT,后者已经展示了出色的工具使用能力,但不幸的是仍然闭源。为了促进开源LLM中的工具使用功能,该文引入了ToolLLM,这是一个数据构建、模型训练和评估的通用工具使用框架。首先介绍 ToolBench,这是一个用于工具的指令微调数据集,用 ChatGPT 自动创建。具体来说,从 RapidAPI Hub 收集有49 个类别 16464 个真实世界的 RESTful API,然后通过提示 让ChatGPT 生成涉及这些 API 的各种人类指令,涵盖单个工具和多个工具场景。最后,用 ChatGPT 为每个指令去搜索有效的解决方案路径(API 调用链)。为了使搜索过程更有效率,作者开发了一种基于深度优先搜索的决策树(DFS-DT),使LLM能够评估多个推理轨迹并扩展搜索空间,结果表明DFSDT显着增强了LLM的规划和推理能力。为了有效地评估工具使用情况,还开发了一个自动评估器:ToolEval。在ToolBench上微调LLaMA并获得ToolLLaMA。ToolEval显示,ToolLLaMA表现出执行复杂指令和推广到未见API的非凡能力,并表现出与ChatGPT相当的性能。为了使流水线更实用,还设计了一个神经 API 检索器,为每个指令推荐合适的 API,无需手动选择 API。
如图所示,一个高质量的指令调优数据集 ToolBench。用最新的ChatGPT(gpt-3.5-turbo-16k)自动构建,该ChatGPT已通过增强的函数call功能进行了升级。给定一条指令,API 检索器推荐一组相关 API,这些 API 被发送到 ToolLLaMA 进行多轮决策,得出最终答案。尽管筛选了大量 API,但检索器表现出非凡的检索精度,返回的 API 与基本事实密切相关。
下表列出了ToolBench与先前工作之间的比较。

RapidAPI 是领先的 API 市场,将开发人员与数千个现实世界的 API 连接起来,简化了各种服务和数据源集成到应用程序的过程。在该平台上,开发人员只需注册一个 RapidAPI key即可发现、测试和连接到各种 API。RapidAPI 中的所有 API 都可以分为 49 个粗粒度的类别,例如体育、金融和天气。这些类别用于将每个 API 与最相关的主题相关联。此外,该中心还提供更细粒度的分类,称为聚集(collections),例如中文 API、基于 AI 的顶级 API 和数据库 API。同一聚集中的 API 具有共同的特征,并且通常具有相似的功能或目标。
如图左边所示,每个工具可能由多个 API 组成。对于每个工具,会抓取以下信息:工具的名称和描述、主机的 URL 以及属于该工具的所有可用 API;对于每个 API,记录其名称、描述、HTTP 方法、必需参数、可选参数、请求主体、API 调用的可执行代码片段(snippets)以及示例 API 调用响应。这些丰富而详细的元数据是LLM理解和有效使用API的宝贵资源,即使是以零样本的方式。
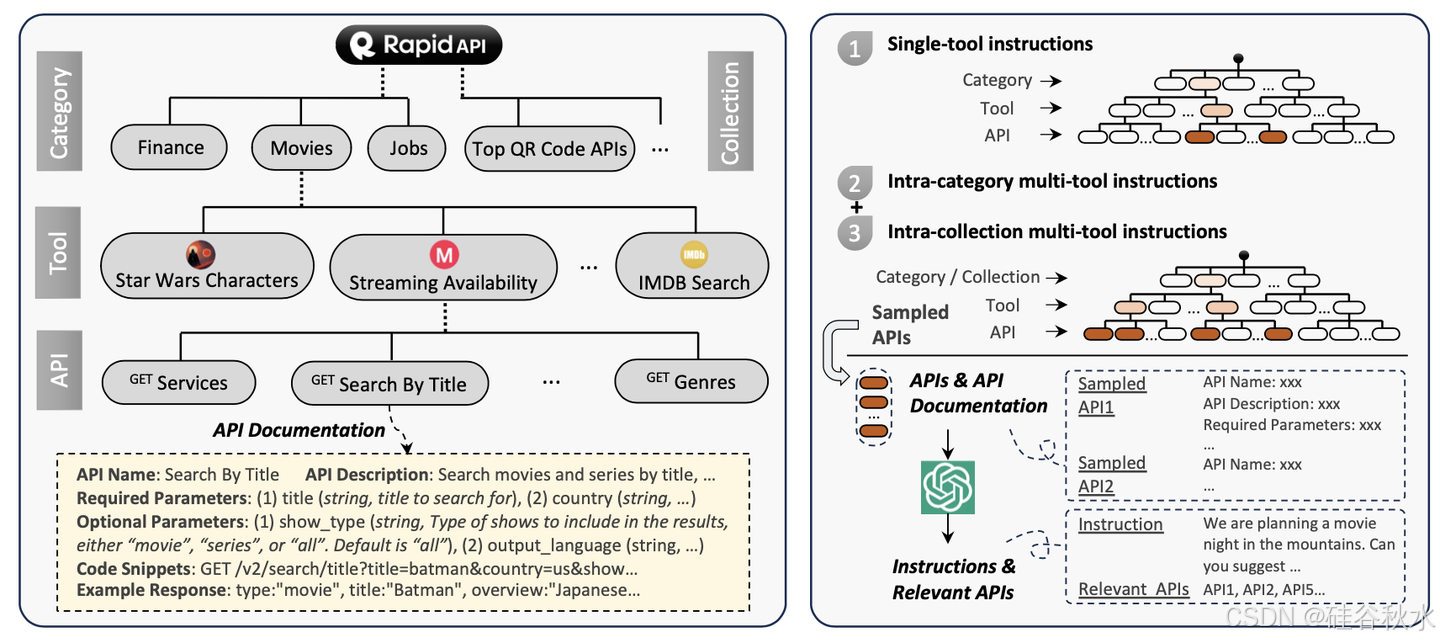
最初,从 RapidAPI 收集了 10853 个工具(53190 个 API)。但是,这些 API 的质量和可靠性可能会有很大差异。特别是,某些 API 可能维护不佳,例如返回 404 错误或其他内部错误。为此,执行严格的滤波过程,以确保ToolBench的最终工具集可靠且功能强大。
滤波过程如下:(1)初始测试:首先测试每个API的基本功能,以确定是否可操作。丢弃任何不符合此基本标准的 API;(2)示例响应评估:进行API调用,获得示例响应。然后,通过响应时间和质量来评估其有效性。始终表现出较长响应时间的 API 将被省略。此外,会过滤掉具有低质量响应的 API,例如 HTML格式源代码或其他错误消息。最后,只保留了 3451 个高质量工具(16464 个 API)。
在检查每个 API 返回的响应时,发现某些响应可能包含冗余信息,并且太长而无法输入 LLM。由于LLM的上下文长度有限,这可能会导致问题。因此,执行响应压缩以减少 API 响应的长度,同时保留其关键信息。
由于每个 API 都有固定的响应格式,因此使用 ChatGPT 来分析一个响应示例,并删除响应中不重要的key以缩短其长度。ChatGPT 的提示包含以下每个 API 的信息:(1) 工具文档,包括工具名称、工具描述、API 名称、API 描述、参数和示例 API 响应。这给了 ChatGPT 一个关于 API 功能的提示;(2) 3 个上下文学习示例,每个示例包含一个原始 API 响应和一个由专家编写的压缩响应模式。这种方式获得了所有 API 的响应压缩策略。在推理过程中,当 API 响应长度超过 2048 个token时,删除不重要的信息压缩响应。如果压缩响应仍长于 2048,仅保留前 2048 个token。
生成高质量的指令需要两个关键方面:1)多样性,以确保LLM处理广泛的API使用场景,提高其通用性和健壮性;2)多工具使用,以反映通常需要多种工具相互作用的现实世界情况,提高LLM的实际适用性和灵活性。为此,采用自下而上的方法来生成指令。不是从头开始头脑风暴(brainstorming)出指令,然后搜索相关的API,而是从收集的API开始,并制定涉及它们的各种指令。
如上图的右边所示,对于单工具指令 (I1),迭代每个工具并为其 API 生成指令。但是,对于多工具设置,由于 RapidAPI 中不同工具之间的互连是稀疏的,因此来自整个工具集的随机采样组合通常会导致一系列不相关的工具,这些工具无法以自然的方式被单个指令覆盖。为了解决稀疏性问题,利用RapidAPI 层次结构信息。由于属于同一类别或集合的工具在功能和目标上通常相互关联,因此从同一类别/集合中随机选择 2-5 个工具,并从每个工具中最多采样 3 个 API 来生成指令。将生成的指令分别表示为类别内(intra-category)多工具指令 (I2) 和聚集内(intra-collection)多工具指令 (I3)。通过严格的人工评估,发现这种方式生成的指令已经具有高度的多样性,涵盖了各种实际场景。Atlas5 的指令可视化说明了这一点。
在生成初始指令集后,评估它们是否存在于 采样的API集合中,进一步滤除那些带有幻觉相关 API 的指令。最后,收集了超过 200k 个合格的指令 N 个相关 API 对,包括 I1/I2/I3 的 87413/84815/25251 个实例。
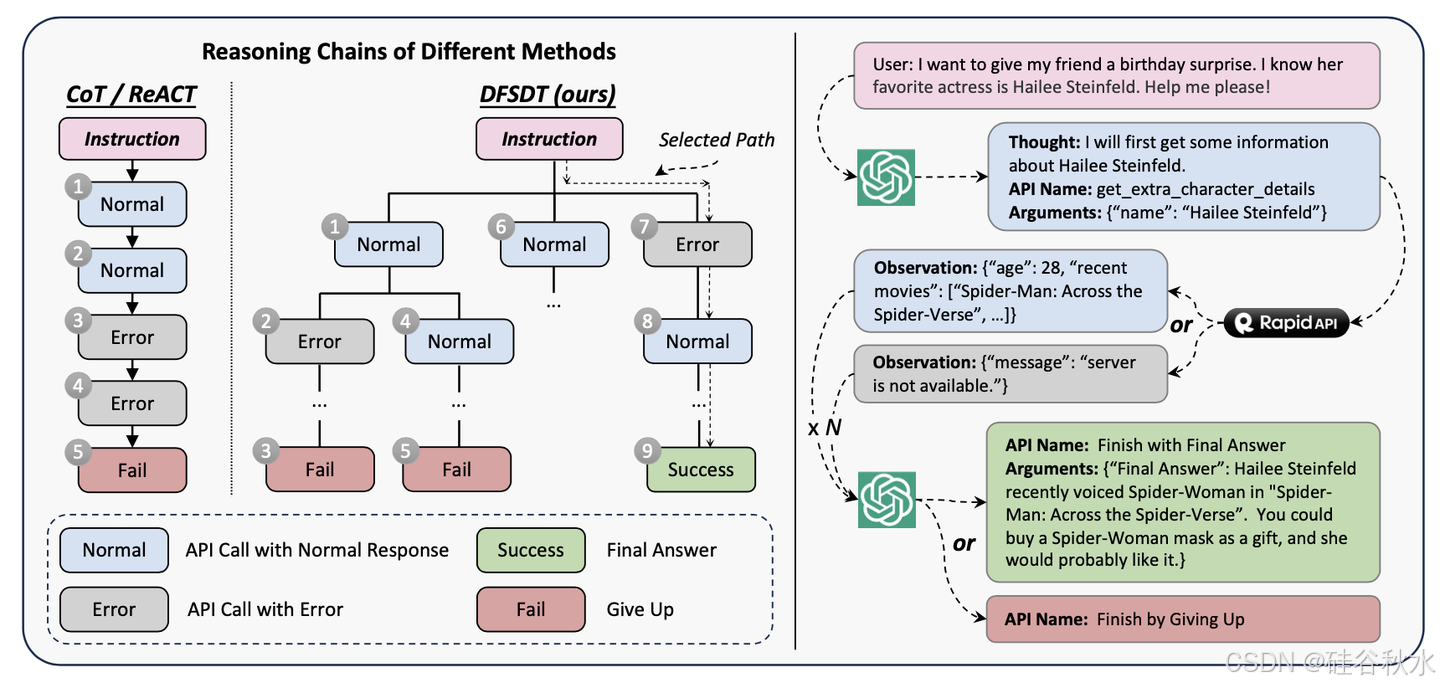
如图 所示,给定指令 Inst∗,提示 ChatGPT 搜索有效的动作序列:{a1 , · · · , aN }。这种多步骤的决策过程被塑造成 ChatGPT 的多轮对话。在每个时间步 t 处,模型根据先前的交互生成一个动作at,即 ChatGPT(at|{A1, R1, · · ·, at−1, rt−1}, Inst∗),其中 r∗ 表示真正的 API 响应。对于每个动作,都会提示 ChatGPT 指定要使用的 API、API 调用的特定参数及其“思维”。换句话说,at 具有以下格式:“思维:· · · ,API 名称:· · · ,参数:· ”。因此,决策空间是思维、可用 API 和可能参数的笛卡尔乘积,其本质上是无限的。
为了利用 gpt-3.5-turbo-16k 的函数调用功能,将每个 API 视为一个特殊函数,并将其 API 文档输入到 ChatGPT 的函数域中。通过这种方式,模型了解如何调用 API。对于每个指令Inst∗,将所有采样的API作为可用函数提供给ChatGPT,而不仅仅是其相关的API。通过这种方式,模型获得了对更广泛范围的 API 的访问权限,并扩展了动作空间。为了完成一个动作序列,定义了两个附加函数,即“最终答案方式完成”和“放弃方式完成”。前一个函数有一个参数,对应于原始指令的详细最终答案;而后一个函数没有参数,专为这种情况而设计,即在多轮 API 调用尝试后,提供的 API 无法成功完成原始指令。
在试点研究中,发现传统的CoT(Wei2023)或ReACT(Yao2022)对决策具有局限性:(1)错误传播:错误的动作可能会进一步传播错误并导致模型陷入错误的循环中,例如以错误的方式不断调用API或产生幻觉API;(2)有限探索:虽然动作空间是无限的,但CoT或ReACT只探索一个可能的方向,导致对整个动作空间的探索有限。因此,即使是 GPT-4 也经常找不到有效的解决方案路径,这使得标注变得困难。
为此构建一个决策树来扩展搜索空间并增加找到有效路径的可能性。如上图所示,DFSDT 允许模型评估不同的推理路径,并选择 (1) 沿着有希望的路径前进,或者 (2) 调用“放弃方式完成”函数,并扩展新节点来放弃现有节点(例如 API 调用失败的节点)。在节点扩展过程中,为了使子节点多样化,扩展搜索空间,提示 ChatGPT 让其提供之前生成的节点信息,并明确鼓励模型生成不同的节点。
更喜欢深度优先搜索 (DFS) 而不是广度优先搜索 (BFS),因为只要找到一个有效路径,标注就可以完成。使用 BFS 在到达终端节点(即“最终答案方式完成”或“放弃方式完成”的节点)之前会花费过多的 OpenAI API 调用。
在实践中,必须平衡有效性与成本(OpenAI API 调用的数量)。因此,选择对DFSDT执行pre-order遍历(DFS的变体)。总体而言,这种设计实现了与DFS相似的性能,同时大大降低了成本。最终,生成了 12657 个指令-解决方案对,用于训练 ToolLLaMA。虽然可以构造更多的训练实例,但发现 12657 个实例已经带来了令人满意的泛化性能。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









