










最近Deepseek团队(北大、清华和南京大学)刚刚公布开源MOE模型DeepSeek-V2,其技术细节见论文“DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model”。
DeepSeek-V2是一个混合专家 (MoE) 语言模型,具有训练经济、推理高效的特点。它包含 236B 总参数,其中每个 token 激活 21B,支持 128K tokens 的上下文长度。DeepSeek-V2 采用包括多头潜注意(MLA) 和 DeepSeek MoE 在内的创新架构。MLA 通过将KV缓存显著压缩为潜向量来保证高效推理,而 DeepSeek MoE 通过稀疏计算以经济的成本训练强大的模型。与 DeepSeek 67B 相比,DeepSeek-V2 实现了显著增强的性能,同时节省了 42.5% 的训练成本、减少了 93.3% 的 KV 缓存、并将最大生成吞吐量提升至 5.76 倍。在由 8.1T tokens组成的高质量多源语料库上对 DeepSeek-V2 进行预训练,并进一步执行有监督微调 (SFT) 和强化学习 (RL) 以充分发挥其潜力。评估结果表明,即使只有 21B 激活参数,DeepSeek-V2 及其聊天版本仍然在开源模型中实现了顶级性能。模型检查点可在 GitHub - deepseek-ai/DeepSeek-V2上找到。
下面介绍其细节。
架构
总体而言,DeepSeek-V2 仍然采用 Transformer 架构(Vaswani et al., 2017),其中每个 Transformer 块由一个注意模块和一个前馈网络 (FFN) 组成。然而,对于注意模块和 FFN,都设计和采用了创新架构。对于注意,设计MLA,它利用低秩K-V联合压缩来消除推理时间K-V缓存的瓶颈,从而支持高效推理。对于 FFN,采用 DeepSeek MoE 架构(Dai et al., 2024),这是一种高性能的 MoE 架构,能够以经济的成本训练出强大的模型。如图展示 DeepSeek-V2 的架构:其中MLA 通过显著减少生成的 KV 缓存来确保高效推理,而 DeepSeek MoE 通过稀疏架构以经济的成本训练出强大的模型。
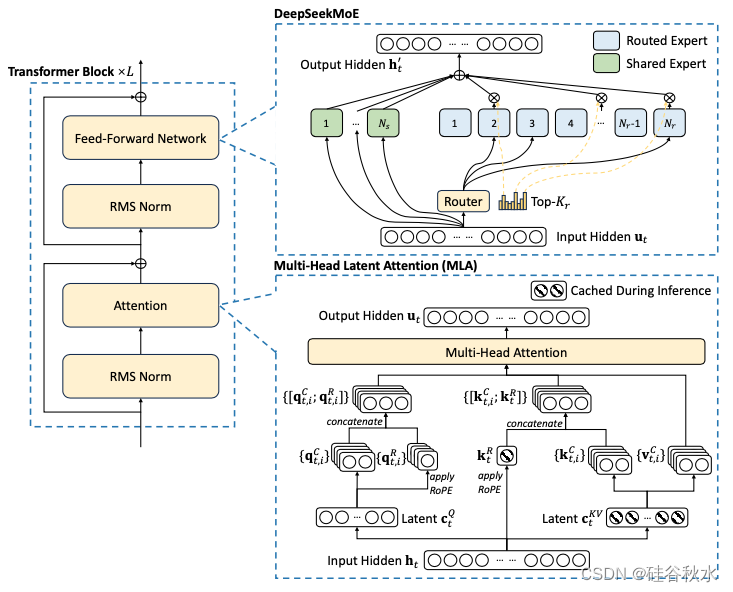
MLA
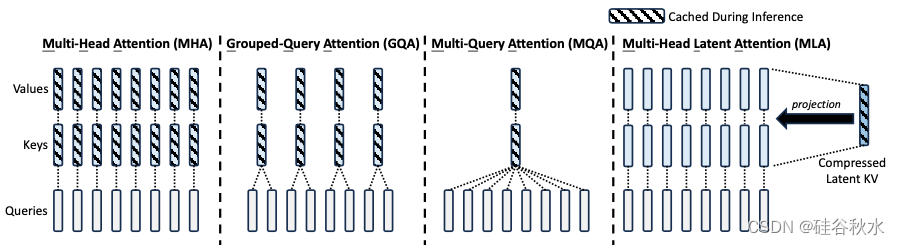
传统的 Transformer 模型通常采用多头注意机制 (MHA) (Vaswani et al., 2017),但在生成过程中,其繁重的KV缓存会成为限制推理效率的瓶颈。为了减少 KV 缓存,提出了多查询注意机制 (MQA) (Shazeer, 2019) 和分组查询注意机制 (GQA) (Ainslie et al., 2023)。它们需要的 KV 缓存量级较小,但性能不如 MHA。
对于 DeepSeek-V2,设计了一种创新的注意机制,称为多头潜注意机制 (MLA)。MLA 配备低秩KV联合压缩,性能优于 MHA,但需要的 KV 缓存量明显较少。
如图所示是多头注意 (MHA)、分组查询注意 (GQA)、多查询注意 (MQA) 和多头潜注意 (MLA) 的简化说明。通过将KV联合压缩为潜向量,MLA 显著减少推理过程中的 KV 缓存。
如 DeepSeek 67B (DeepSeek-AI, 2024) 那样,将旋转位置嵌入 (RoPE) (Su et al., 2024) 用于 DeepSeek-V2。但是,RoPE 与低秩 KV 压缩不兼容。具体来说,RoPE 对K和Q都是位置敏感的。如果将 RoPE 应用于K,则将与位置敏感的 RoPE 矩阵耦合。因此,必须在推理过程中重计算所有前缀tokens的K,这将严重阻碍推理效率。作为一种解决方案,提出解耦的 RoPE 策略,该策略使用额外的多头 Q 和共享 K 来承载 RoPE。
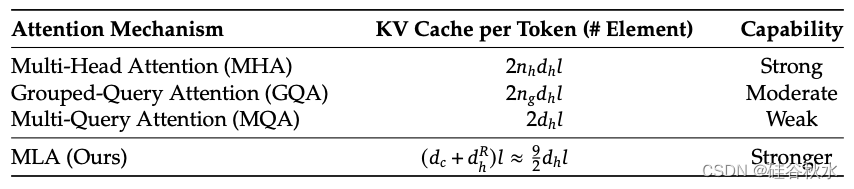
在下表 1 中展示不同注意机制中每个 token 的 KV 缓存比较。MLA 只需要少量的 KV 缓存,相当于只有 2.25 个组的 GQA,但可以获得比 MHA 更强的性能。
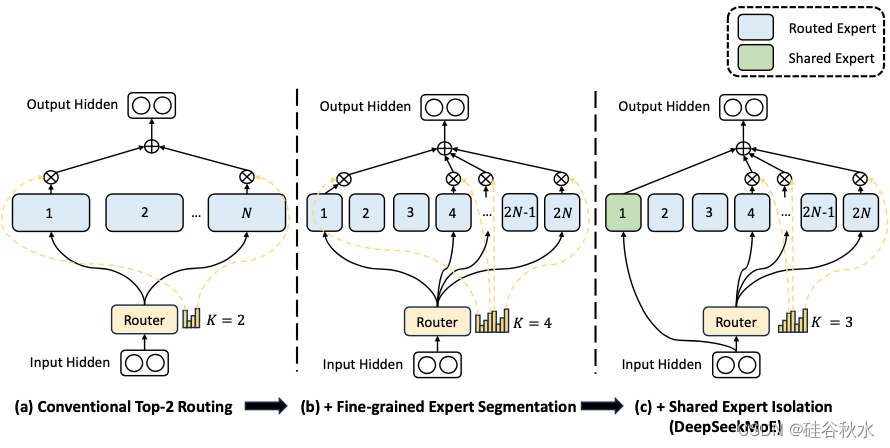
DeepSeek MoE
对于 FFN,采用 DeepSeekMoE 架构(Dai ,2024)。DeepSeekMoE 有两个关键思想:将专家细分为更细的粒度,以提高专家的专业化程度和更准确的知识获取,并隔离一些共享专家以减轻路由专家之间的知识冗余。在激活和总专家参数量相同的情况下,DeepSeekMoE 可以大大优于传统的 MoE 架构,例如 GShard(Lepikhin,2021)。
如图是DeepSeek MoE的示意图: (a) 展示具有传统 top-2 路由策略的 MoE 层;(b) 说明细粒度专家分割策略;随后 © 演示共享专家隔离策略的集成,构成了完整的 DeepSeek MoE 架构。值得注意的是,在这三种架构中,专家参数量和计算成本保持不变。
设计了一种设备受限的路由机制来限制与 MoE 相关的通信成本。当采用专家并行时,路由的专家将分布在多个设备上。对于每个 token,其与 MoE 相关的通信频率与其目标(targeted)专家覆盖的设备数成正比。由于 DeepSeek MoE 中的专家细分度分割,激活的专家数量可能很大,因此如果应用专家并行,与 MoE 相关的通信成本将更高。
对于 DeepSeek-V2,除了简单的 top-K 路由专家选择之外,还确保每个 token 的目标专家将分布在最多 𝑀 个设备上。具体来说,对于每个 token,首先选择 𝑀 个具有最高亲和力(affinity)分数专家的设备。然后,在这些 𝑀 设备上的专家中进行 top-K 选择。在实践中发现当 𝑀 ⩾ 3 时,设备受限路由可以实现与无限 top-K 路由大致相同的良好性能。
在自动学习路由策略时考虑负载平衡。首先,负载不平衡会增加路由崩溃的风险(Shazeer et al., 2017),导致某些专家无法得到充分训练和利用。其次,当使用专家并行时,负载不平衡会降低计算效率。在 DeepSeek-V2 的训练过程中,设计三种辅助损失,分别用于控制专家级负载平衡(LExpBal)、设备级负载平衡(LDevBal)和通信平衡(LCommBal)。
虽然平衡损失旨在鼓励平衡负载,但必须承认它们无法保证严格的负载平衡。为了进一步减轻负载不平衡造成的计算浪费,在训练期间引入设备级 token 丢弃策略。此方法首先计算每个设备的平均计算预算,这意味着每个设备的容量因子相当于 1.0。然后,受 Riquelme et al. (2021) 的启发,在每个设备上丢弃亲和力得分最低的 tokens,直到达到计算预算。此外,确保大约 10% 训练序列的 tokens 永远不会被丢弃。通过这种方式,可以根据效率要求灵活决定是否在推理期间丢弃 token,并始终确保训练和推理之间的一致性。
预训练
实验设置
在保持与 DeepSeek 67B(DeepSeek-AI,2024)相同的数据处理阶段同时,扩展数据量并提高数据质量。为了扩大预训练语料库,探索互联网数据的潜力并优化清理流程,恢复了大量被误删的数据。此外,纳入更多的中文数据,旨在更好地利用中文互联网上可用的语料库。除了数据量,还关注数据质量。用来自各种来源的高质量数据丰富预训练语料库,同时改进基于质量的过滤算法。改进的算法确保大量无用数据将被删除,而有价值的数据将大部分保留。此外,从预训练语料库中过滤掉有争议的内容,减轻特定区域文化引入的数据偏差。
采用与 DeepSeek 67B 相同的token化器,基于Byte-level Byte-Pair Encoding(BBPE) 算法构建,词汇量为 100K。Token化后的预训练语料包含 8.1T 的 tokens,其中中文 tokens 比英文 tokens 多约 12%。
模型超参。Transformer 层数设置为 60,隐维度设置为 5120。所有可学习参数均以标准差 0.006 随机初始化。在 MLA 中,将注意头的数量设置为 128,每个头的维度设置为 128。KV 压缩维度设置为 512,查询压缩维度设置为 1536。对于解耦的Q和K,将每个头的维度设置为 64。按照 Dai (2024) 的做法,用 MoE 层替代除第一层之外的所有 FFN。每个 MoE 层由 2 个共享专家和 160 个路由专家组成,其中每个专家的中间隐维度为 1536。在路由专家中,每个 token 将激活 6 个专家。此外,低秩压缩和细粒度专家分割将影响层的输出尺度。因此,在实践中,在压缩的潜向量之后使用额外的 RMS Norm层,并在宽度瓶颈(即压缩的潜向量和路由专家的中间隐状态)处乘以额外的缩放因子,以确保稳定的训练。在这种配置下,DeepSeek-V2 包含 236B 个参数,其中每个 token 激活 21B 个。
训练超参。用 AdamW 优化器(Loshchilov & Hutter,2017),超参数设置为 𝛽1 = 0.9、𝛽2 = 0.95 和 weight_decay = 0.1。学习率的调度采用warmup-and-step-decay策略(DeepSeek-AI, 2024)。最初,在前2K步中,学习率从0线性增加到最大值。随后,在训练大约60%的tokens后,将学习率乘以0.316,在训练大约90%的tokens后,学习率再乘以0.316。最大学习率设置为2.4×10−4,梯度裁剪范数设置为1.0。还使用了一个批次大小调度策略,在前225B个tokens的训练中,其从2304逐渐增加到9216,然后在剩余的训练中保持9216。将最大序列长度设置为4K,并在8.1T tokens上训练DeepSeek-V2。用流水线并行将模型的不同层部署在不同设备上,对于每一层,路由专家将统一部署在 8 台设备上(𝐷 = 8)。对于设备受限路由,每个 token 将最多发送到 3 台设备(𝑀 = 3)。对于平衡损失,三个损失项的专家级平衡因子分别设置为 0.003,0.05,0.02。在训练期间采用 token 丢弃策略来加速,但在评估时不丢弃任何 tokens。
DeepSeek-V2 基于 HAI-LLM 框架 (High-flyer, 2023) 进行训练,这是一个团队开发的高效轻量级训练框架。它采用 16 路zero-bubble流水线并行 (Qi et al., 2023)、8 路专家并行 (Lepikhin et al., 2021) 和 ZeRO-1 数据并行 (Rajbhandari et al., 2020)。鉴于 DeepSeek-V2 的激活参数相对较少,并且部分算子被重计算以节省激活内存,因此无需张量并行即可进行训练,从而降低通信开销。此外,为了进一步提高训练效率,将共享专家的计算与专家并行的all-to-all通信重叠。还为不同专家之间的通信、路由算法和融合线性计算定制更快的 CUDA 内核。此外,MLA 还基于改进的Flash Attention-2 (Dao, 2023) 进行优化。
在配备 NVIDIA H800 GPU 的集群上进行所有实验。H800 集群中的每个节点包含 8 个 GPU,使用 NVLink 和节点内的 NVSwitch 连接。在节点之间,使用 InfiniBand 互连来促进通信。
在对 DeepSeek-V2 进行初始预训练后,用 YaRN (Peng et al., 2023) 将默认上下文窗口长度从 4K 扩展到 128K。YaRN 专门应用于解耦共享K,因为它负责承载 RoPE (Su et al., 2024)。对于 YaRN,目标最大上下文长度设置为 160K。在这些设置下,可以预期模型对 128K 的上下文长度有良好的响应。与原始 YaRN 略有不同,由于设计独特的注意机制,调整长度缩放因子来调节注意熵。
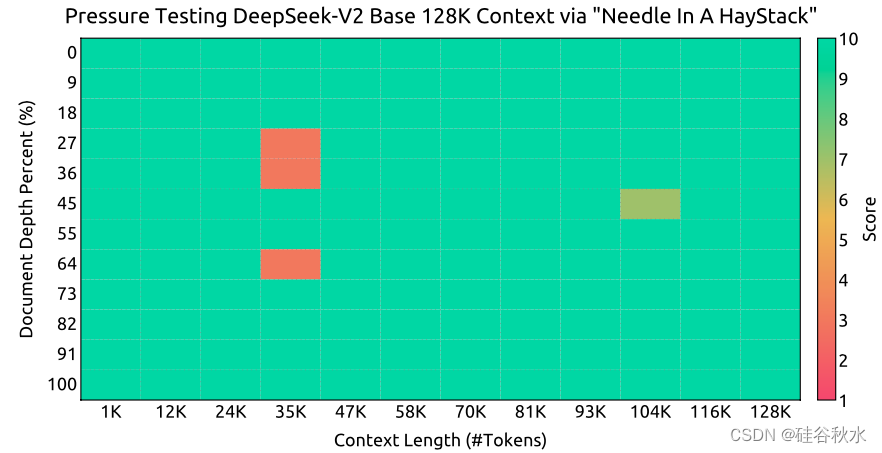
另外对模型进行了 1000 步训练,序列长度为 32K,批处理大小为 576 个序列。尽管训练仅在 32K 的序列长度下进行,但在 128K 的上下文长度下评估时,该模型仍表现出稳健的性能。如图所示“大海捞针”(NIAH) 测试的结果表明,DeepSeek-V2 在高达 128K 的所有上下文窗口长度上都表现良好。
评估
DeepSeek-V2 是在双语语料库上进行预训练的,因此根据一系列英语和中文基准对其进行评估。评估基于团队内部评估框架,该框架集成于 HAI-LLM中。
继之前的工作(DeepSeek-AI,2024)之后,对包括 HellaSwag、PIQA、WinoGrande、RACE-Middle、RACE-High、MMLU、ARC-Easy、ARC-Challenge、CHID、C-Eval、CMMLU、C3 和 CCPM 在内的数据集采用基于困惑度的评估,并对 TriviaQA、NaturalQuestions、DROP、MATH、GSM8K、HumanEval、MBPP、CRUXEval、BBH、AGIEval、CLUEWSC、CMRC 和 CMath 采用基于生成的评估。此外,对 Pile-test 进行基于语言建模的评估,并使用比特/字节 (BPB) 作为度量标准,确保对具有不同token化器的模型进行公平比较。
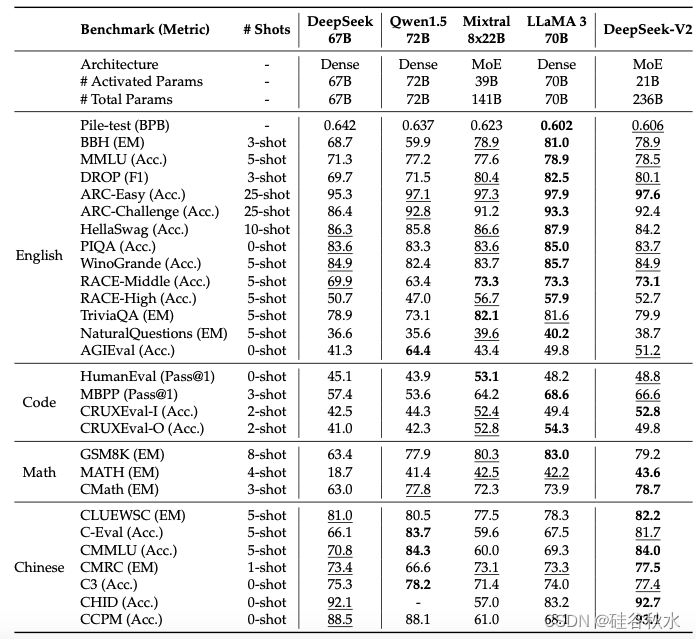
下表是DeepSeek-V2 和其他开源模型的评估结果比较:
训练成本。由于 DeepSeek-V2 为每个 token 激活的参数更少,所需的 FLOPS 也比 DeepSeek 67B 少,因此从理论上讲,训练 DeepSeek-V2 比训练 DeepSeek 67B 更经济。虽然训练 MoE 模型会引入额外的通信开销,但通过算子和通信优化,DeepSeek-V2 的训练可以达到相对较高的模型 FLOPS 利用率 (MFU)。在 H800 集群上进行实际训练时,每训练一万亿个 tokens,DeepSeek 67B 需要 300.6K GPU 小时,而 DeepSeek-V2 只需要 172.8K GPU 小时,即稀疏的 DeepSeek-V2 比密集的 DeepSeek 67B 可以节省 42.5% 的训练成本。
推理效率。为了高效地将 DeepSeek-V2 部署到服务中,首先将其参数转换为 FP8 的精度。此外,还对 DeepSeek-V2 进行了 KV 缓存量化(Hooper et al., 2024; Zhao et al., 2023),进一步将其 KV 缓存中每个元素平均压缩为 6 位。受益于 MLA 和这些优化,实际部署的 DeepSeek-V2 所需的 KV 缓存明显少于 DeepSeek 67B,因此可以服务于更大的批次大小。根据实际部署的 DeepSeek 67B 服务的提示和生成长度分布来评估 DeepSeek-V2 的生成吞吐量。在具有 8 个 H800 GPU 的单节点上,DeepSeek-V2 实现了超过 50K tokens/s 的生成吞吐量,是 DeepSeek 67B 最大生成吞吐量的 5.76 倍。此外,DeepSeek-V2 的提示输入吞吐量超过 100K tokens/s。
对齐
SFT
在之前的研究(DeepSeek-AI,2024)的基础上,整理包含 150 万个实例的指令调整数据集,其中包括 120 万个用于帮助的实例和 30 万个用于安全性的实例。与初始版本相比,提高了数据质量以减轻幻觉反应并提高写作能力。对 DeepSeek-V2 进行了 2 个 epochs 的微调,学习率设置为 5 × 10-6。对于 DeepSeek-V2 Chat (SFT) 的评估,除了几个有代表性的多项选择任务(MMLU 和 ARC), 主要包括基于生成的基准。还对 DeepSeek-V2 Chat (SFT) 进行了指令遵循评估 (IFEval)(Zhou et al.,2023),使用提示级松散准确度作为指标。此外,用 2023 年 9 月 1 日至 2024 年 4 月 1 日的 LiveCodeBench (Jain et al., 2024) 问题来评估聊天模型。除了标准基准之外,还在开放式对话基准上进一步评估模型,包括 MT-Bench (Zheng et al., 2023)、AlpacaEval 2.0 (Dubois et al., 2024) 和 AlignBench (Liu et al., 2023)。为了进行比较,还在评估框架和设置中评估了 Qwen1.5 72B Chat、LLaMA-3-70B Instruct 和 Mistral-8x22B Instruct。对于 DeepSeek 67B Chat,直接参考之前版本中报告的评估结果。
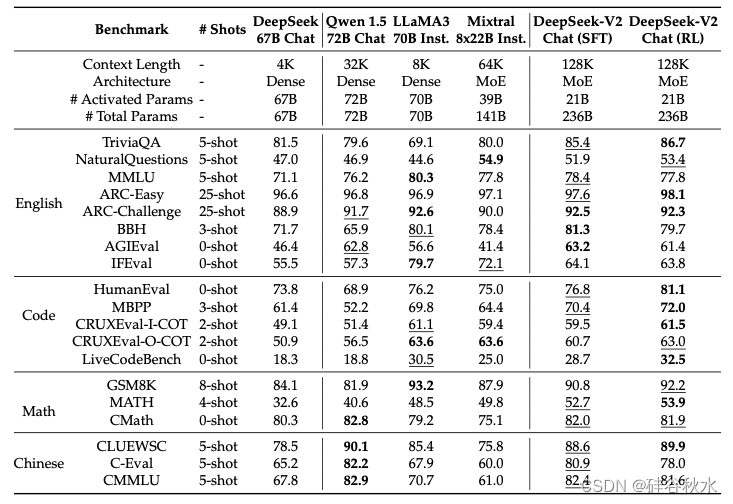
下表是DeepSeek-V2 Chat (SFT)、DeepSeek-V2 Chat (RL) 和其他代表性开源聊天模型之间的比较。关于 TriviaQA 和 NaturalQuestions,值得注意的是,聊天模型(例如 LLaMA3 70B Instruct)可能不严格遵守在少样本设置中通常指定的格式约束。因此,这可能导致评估框架低估某些模型。
RL
为了节省 RL 的训练成本,采用组相对策略优化 (GRPO) (Shao et al., 2024),它放弃了通常与策略模型大小相同的critic模型,而是从组得分中估计基线。
在初步实验中,在推理数据(例如代码和数学提示)上进行的 RL 训练表现出与在一般数据上训练不同的独特特征。例如,模型的数学和编码能力可以在较长的训练步骤中不断提高。因此,采用了两步 RL 训练策略,首先进行推理对齐,然后进行人类偏好对齐。
为了获得在强化学习训练中发挥关键作用的可靠奖励模型,需要精心收集偏好数据,并一丝不苟地进行质量过滤和比例调整。根据编译器反馈获取代码偏好数据,根据真实标签获取数学偏好数据。对于奖励模型训练,使用 DeepSeek-V2 Chat (SFT) 初始化奖励模型,并使用逐点或成对损失进行训练。在实验中,强化学习训练可以充分挖掘和激活模型的潜力,使其能够从可能的响应中选择正确且令人满意的答案。
在超大模型上进行强化学习训练对训练框架提出了很高的要求。它需要精心的工程优化来管理 GPU 内存和 RAM 压力,同时保持较快的训练速度。为此,实施以下工程优化。(1)首先,提出了一种混合引擎,分别采用不同的并行策略进行训练和推理,以实现更高的 GPU 利用率。(2)其次,利用具有大批量大小的 vLLM(Kwon et al.,2023)作为推理后端来加速推理速度。(3)第三,精心设计一种调度策略,用于将模型卸载到 CPU 并将模型加载回 GPU,从而在训练速度和内存消耗之间实现了近乎最佳的平衡。
评估结果
下表是GPT-4-0613 评分的 AlignBench 排行榜。模型排名按总分降序排列。标有 * 的模型表示通过其 API 服务或开放权重模型对其进行评估,而不是参考其原始论文中报告的结果。Erniebot-4.0 和 Moonshot 的后缀表示调用其 API 时的时间戳。
















 7491
7491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









