











摘要:
数据是具身人工智能或具身智能(EI)发展的瓶颈。本文想阐明什么数据对于 EI 中的动作/行为训练是必不可少的。首先简要概述了人工智能在算法、计算和数据方面的发展(以及人工智能的分级)。然后重点介绍具身人工智能的动作/行为学习方法(包括世界模型和视觉-语言-动作模型)。对于数据收集,调查了机器人的类型和灵活性,然后比较了机器人模拟平台和机器人或人类的真实动作数据捕获平台。关于人类数据,研究以自我为人工智能或可穿戴人工智能。最终,体现了 EI 对数据集的要求。结论中讨论了泛化的技巧。
1 引言
人工智能 (AI) 的进步得益于三个领域的进步:算法、计算和数据。算法是计算机系统用于解决问题或完成任务的程序或公式。计算是指使用计算机系统进行计算或处理数据。数据是指训练和验证 AI 模型所需的信息。
1.1 算法
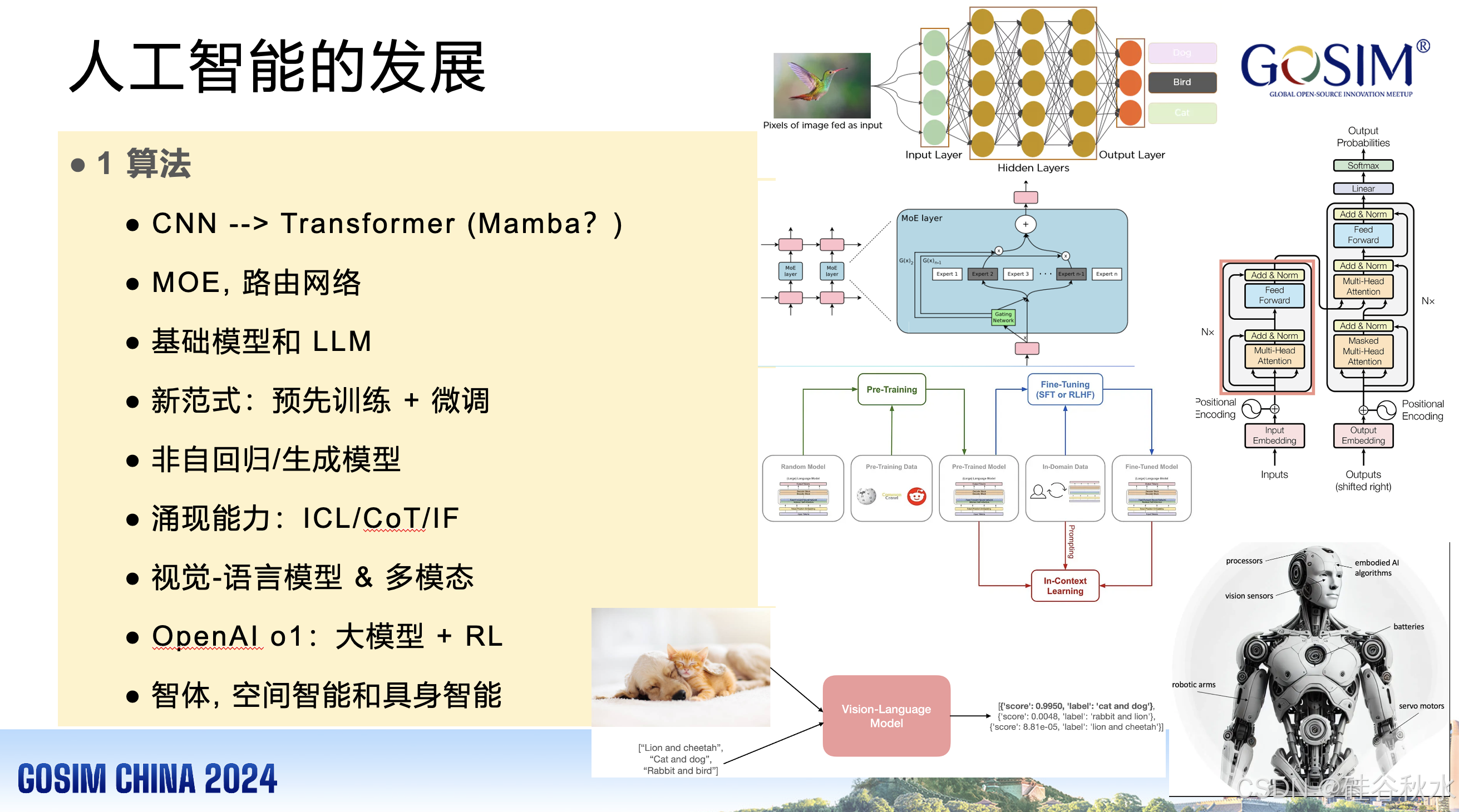
Transformer。与卷积神经网络 (CNN) 不同,Transformer [22] 是一种编码器-解码器架构,旨在从自然语言中提取信息。基本构建块称为单元,由两个模块组成,即多头注意 (MHA) 和前馈网络 (FFN)。此外,位置信息被明确地添加到模型中,位置编码 (PE) , 以保留句子中单词顺序的信息。
Mamba。Mamba [276, 320] 是一种选择性结构化状态空间模型,擅长长序列建模。Mamba 通过克服 CNN 的局部感知限制和 Transformer 的二次计算复杂性来应对长序列中的挑战。
基础模型。基础模型 [126, 210, 212] 在 NLP 中最为强大。在技术层面上,基础模型由迁移学习和扩展实现。迁移学习的理念是将从一个任务中学到的“知识”应用到另一个任务中。基础模型通常遵循这样的范式:模型在替代任务上进行预训练,然后通过微调适应下游感兴趣的任务。
LLM。最近出现的大多数大规模语言模型 (LLM) [137, 243] 都属于或基于基础模型。最近具有十亿个参数的模型已被有效地用于零/少样本学习,无需大规模任务特定数据或模型参数更新即可实现令人印象深刻的性能。
LLM 是基于 Transformer 的语言模型类别,其特点是具有大量参数,通常数量达数千亿甚至更多。这些模型在海量文本数据集上进行训练,使它们能够理解自然语言并执行各种复杂任务,主要是通过文本生成和理解。
一些著名的 LLM 示例包括 OpenAI GPT-1/2/3/3.5/4 [23, 29, 43, 80, 132]、Meta LLaMA 1/2/3 [123, 169, 318]、Microsoft Phi-1/1.5/2/3[158, 183, 217, 273]、Mistral [194]、Google Gemini [223] 及其开放轻量级版本 Gemma [259] 等。
通过选择适当的提示 [170],可以操纵模型行为,以便预训练的 LM 本身可用于预测所需的输出,有时甚至不需要任何额外的特定任务训练。
LLM 的涌现能力是将其与较小的语言模型区分开来的最重要特征之一。具体而言,上下文学习 (ICL) [114, 170]、指令跟随 [177] 和思维链推理 (CoT) [115, 148, 190, 275] 是 LLM 的三种典型涌现能力。
参数高效微调 (PEFT) 是一种关键技术,用于将预训练模型适配到专门的下游应用,其中一种典型的方法 LoRA [59] 利用低秩分解矩阵来减少可训练参数的数量。
由于 LLM 经过训练以捕获预训练语料库(包括高质量和低质量数据)的数据特征,因此它们很可能为人类生成有毒、有偏见甚至有害的内容。有必要将 LLM 与人类价值观 [80, 189] 保持一致,例如乐于助人、诚实和无害。
最近,OpenAI o1 模型 [339] 宣布用于强化学习 (RL) 的复杂推理,开启了新测试-时间规模化定律中的推理时间优化风格,类似的技术可以在 Math-Shepherd [222]、MiPS [239]、OmegaPRM [295]、REBASE [319]、规模化 LLM 测试-时间计算定律 [322]、Qwen2.5-Math [334]、OpenR [342] 和 Dualformer [347] 等中看到。
MoE。混合专家 (MoE) [226, 300] 模型为每个传入示例选择不同的参数。结果是一个稀疏激活模型,具有多个参数,但计算成本恒定。
CoE。 SambaNova [267, 286] 提出了专家组合 (CoE),将大型模型的广泛性和准确性与小型模型的性能相结合,类似于 RouteLLM [305] 的路由网络。
VLM。视觉语言模型 (VLM) 连接了自然语言处理 (NLP) 和计算机视觉 (CV) 的功能,打破了文本和视觉信息之间的界限,连接了多模态数据,例如 Dino 1/2 [56, 144]、CLIP [63]、DALL-E1/2/3 [64, 86, 203]、BLIP-1/2 [78, 119]、Flamingo [88]、SAM [141]、SEEM [143] 和 GPT-4v [192] 等。
MLLM。受 LLM 潜力的启发,许多多模态 LLM (MLLM) [186] 已被提出,以将 LLM 扩展到多模态领域,即感知图像/视频输入,并与用户进行多轮对话,例如 OpenAI 的 GPT-4o [293] 和 Anthropic Claude 3.5 [362]。上述模型在大量图像/视频-文本对上进行了预训练,只能处理图像级任务,例如图像字幕和问答。
智体。基于 LLM 的智体 [178, 185, 229, 240] 可以通过 CoT/ToT 和问题分解等技术表现出与符号智体相当的推理和规划能力。它们还可以通过从反馈中学习并执行新操作,获得与环境交互的能力,类似于反应式智体。
具身人工智能。最近的研究为机器人和具身人工智能开发了更高效的强化学习智体 [209, 212, 220, 221, 238, 241, 249, 288, 310]。重点是增强智体在具身环境中的规划、推理和协作能力。一些方法将互补的优势结合到具身推理和任务规划的统一系统中。高级命令可以改进规划,而低级控制器将命令转化为动作。
1.2 计算
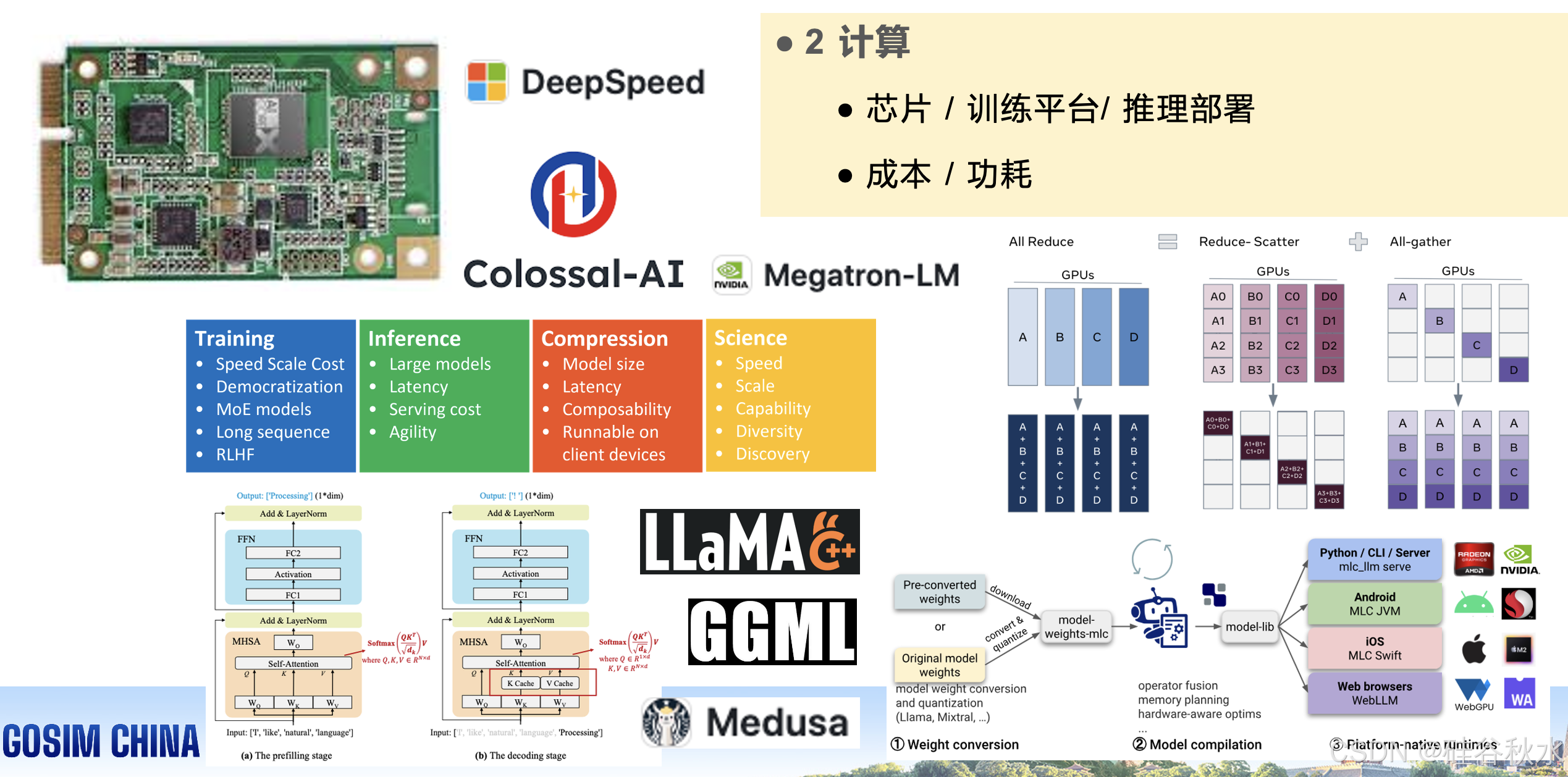
分布式训练。Colossal-AI 系统 [72] 引入了一个统一的接口,将模型训练的顺序代码扩展到分布式环境。它支持数据、流水线、张量和序列并行等并行训练方法,以及与**零冗余优化器(ZERO)**集成的异构训练方法。
模型并行是指将神经架构图划分或分片为子图,并将每个子图或模型分片分配给不同的设备。数据并行支持并行使用多个小批量数据。张量并行将张量沿特定维度拆分为 N 个块,并在多个 GPU 中拟合大型模型。流水线并行将传入的批次分解为小批量,并将模型的各层划分到多个 GPU 上。序列并行沿序列维度进行划分,使其成为训练长文本序列的有效方法。
高效的 Transformer 架构。为了提高 Transformer 架构的效率和可扩展性,对其进行了一些修改,例如多查询注意 (MQA)/分组查询注意 (GQA)、Switch Transformers、旋转位置嵌入 (RoPE)、Megatron-LM(一个 NVIDIA 开发的大型、功能强大的 Transformer)中的 FlashAttention1/2 [31]。
Perceiver IO [62] 在一组不太大的潜向量(例如 256 或 512)上使用自注意机制,并且仅使用输入与潜向量执行交叉注意。这使得自注意机制的时间和内存要求不依赖于输入的大小。
硬件效率。FlashAttention [90] 是一种 IO-觉察精确注意算法,它使用平铺来减少 GPU 高带宽内存 (HBM) 和 GPU 片上 SRAM 之间的内存读写次数。改进的 FlashAttention-2 [168],可以通过更好的工作划分来解决这些问题。
PagedAttention 由 vLLM [184](一种高吞吐量和内存高效的 LLM 推理和服务引擎)提出,是一种受到操作系统中经典虚拟内存和分页技术启发的注意算法。
内存优化。零冗余优化器 (ZeRO) [33] 通过将冗余模型状态划分为三个相应的阶段并优化通信来优化内存中的冗余模型状态,最终模型状态均匀分布在每个节点上。 ZeRO-Offload [51] 将两个状态的数据和计算卸载到 CPU,从而利用 CPU 节省 GPU 内存。 ZeRO-Infinity [52] 利用多个设备并行利用 CPU 和 NVMe 内存(便宜、慢但庞大),为当前的 GPU 集群聚合高效带宽。
自回归解码方法逐个生成 token。在每个解码步骤中,所有模型权重都从片外高带宽内存 (HBM) 加载到 GPU 芯片,导致内存访问成本高昂。KV 缓存的大小会随着输入长度的增加而增加,这可能会导致内存碎片和不规则的内存访问模式。 KV Cache 方法在多头自注意 (MHSA) 块 [208] 中存储和重用先前的 (K-V) 对。它包括两个步骤:1) 预填充;2) 解码。
推理加速。Medusa [231] 为 LLM 添加了额外的“头”,以同时预测多个未来token。这些头每个都会为相应位置生成多个可能的单词。LLaMA.cpp [235] 是 LLaMA 架构的低级 C/C++ 实现,支持多个 BLAS 后端以实现快速处理。它使用 GGUF 量化方案,并具有 CPU 和 GPU 卸载功能。
1.3 数据
在 CV 和 NLP 中,使用从互联网上抓取的大量多样化数据集进行训练 [7, 251] 可以生成可推广到各种新任务的模型。
同样,在具身 AI(例如机器人操纵)中,最近的研究表明,更大、更多样化的机器人训练数据集可以突破策略泛化的极限,包括主动迁移到新目标、指令、场景和实现 [70, 179, 195]。
研究人员已经转向模拟环境 [8, 45, 154, 199, 343] 以减轻数据获取的难度并加速数据收集过程。然而,这种策略也有自己的挑战,其中最重要的是模拟与现实之间的差距。
对于数据集,有必要进行清理、过滤和管理,以保护隐私,符合人类偏好,保持多样性和质量,即使在特定的领域和职业中也是如此。

1.4 分级
AGI(通用人工智能)的“火花”已出现在最新一代的 LLM 中。Google DeepMind 根据能力的深度(性能)和广度(通用性)提出了 AGI 的分级 [207]。
人工智能智体能够根据其训练和输入数据进行理解、预测和响应。在这些能力得到开发和改进的同时,了解它们的局限性以及它们所训练的底层数据的影响非常重要。[285] 提出了基于效用和能力的人工智能智体分级,包括感知、工具、行动、推理、决策、记忆、反思、泛化、自学、个性和协作等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









